浏览器:火狐浏览器
开发工具:pycharm
这几天自学python爬虫,于是写了一个在线汉语字典。
选择的爬取的网站为:百度汉语。(url简单)
1、寻找查询时url的变化规律。
搜索成语:“坚壁清野”(这里不能直接复制,直接复制地址会自动转换成url格式,不利于发现鼓励)
搜索汉字:“爱”
搜索词语:“莲花”
对比上面三个URL,我们可以发现规律如下:
前面和后面是固定不变的,中间wd=(需要查询的词语)。
url = https://hanyu.baidu.com/s?wd=(需要查询的词语)&device=pc&from=home
2、爬取网页代码。
这一步比较简单,但需要注意url的格式。
import urllib.request
import requests
from bs4 import BeautifulSoup
#url前边的部分。因为此地址中包含特殊符号(?),所以为动态页面。
url_prefix = "https://hanyu.baidu.com/s?wd="
word = input("请输入需要查询的词语:")
#word = urllib.parse.quote(word)
url_suffix = "&device=pc&from=home"
#真正URL
url = url_prefix + word + url_suffix
#爬取该页全部代码
response = requests.get(url)
#使用'utf-8'格式编码(防止中文乱码)
response.encoding = 'utf-8'
html = response.text
soup = BeautifulSoup(html, "lxml")但这样看上去没错实际会报错。

因为URL 只允许一部分 ASCII 字符(数字字母和部分符号),其他的字符(如汉字)是不符合 URL 标准的。 所以 URL 中使用其他字符就需要进行 URL 编码。
所以我们使用函数:urllib.parse.quote()对汉字进行格式转换。
即加入:
word = urllib.parse.quote(word)现在我们得到了全部的代码,就可以进行第三步。
3、筛选我们需要的内容。
我们需要的内容为:
(1):解释
(2):例句(诗句)
在浏览器中按F12可以得到网页的全部代码。
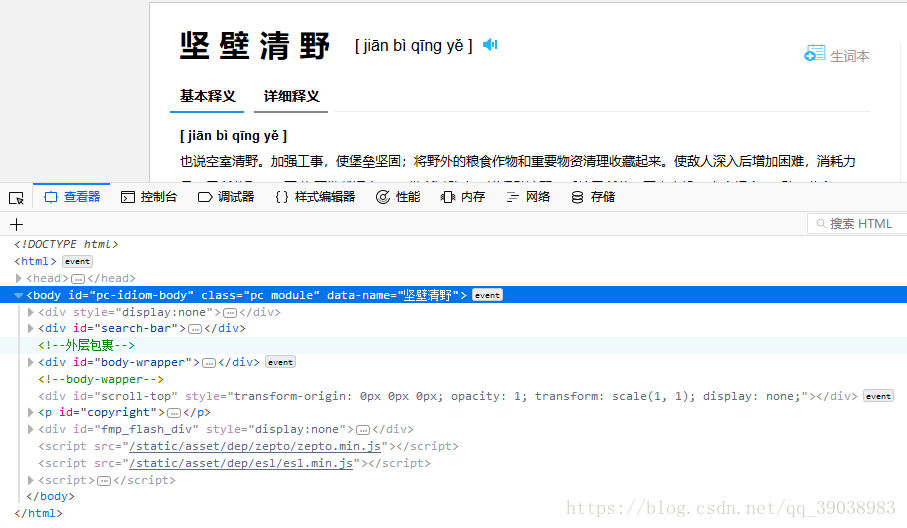
从中选取我们需要的内容。
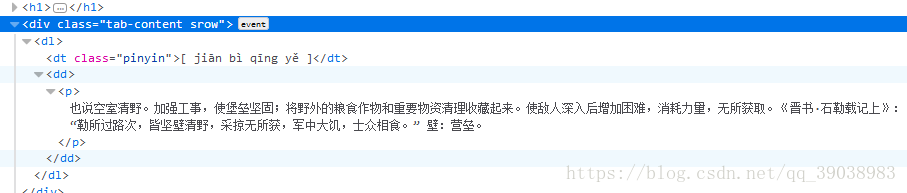
成语和词语的解释位置不同,但寻找方法相同,这里就不做赘述。
#基本解释存在于:poem-list-item-body和tab-content
soup_explain_1 = soup.find_all(class_="poem-list-item-body")
soup_explain_2 = soup.find_all(class_="tab-content")
if soup_explain_1 == None and soup_explain_2 == None:
print("该词没有收录。")
else:
print("解释:")
if soup_explain_1 != None:
for i in range(len(soup_explain_1)):
print(soup_explain_1[i].text.strip())
if soup_explain_2 != None:
for i in range(len(soup_explain_2)-2):
print(soup_explain_2[i].text.strip())运行结果:

这样这个爬虫就完成了。
爬取网页是推荐用Requests库。Urllib在爬取动态网页时,没有Requests简单。如果代码有问题的话,请各位留言。
完整代码:
import urllib.request
import requests
from bs4 import BeautifulSoup
#url前边的部分。因为此地址中包含特殊符号(?),所以为动态页面。
url_prefix = "https://hanyu.baidu.com/s?wd="
word = input("请输入需要查询的词语:")
word = urllib.parse.quote(word)
url_suffix = "&device=pc&from=home"
#真正URL
url = url_prefix + word + url_suffix
#爬取该页全部代码
response = requests.get(url)
#使用'utf-8'格式编码(防止中文乱码)
response.encoding = 'utf-8'
html = response.text
soup = BeautifulSoup(html, "lxml")
#基本解释存在于:poem-list-item-body和tab-content
soup_explain_1 = soup.find_all(class_="poem-list-item-body")
soup_explain_2 = soup.find_all(class_="tab-content")
if soup_explain_1 == None and soup_explain_2 == None:
print("该词没有收录。")
else:
print("解释:")
if soup_explain_1 != None:
for i in range(len(soup_explain_1)):
print(soup_explain_1[i].text.strip())
if soup_explain_2 != None:
for i in range(len(soup_explain_2)-2):
print(soup_explain_2[i].text.strip())