目录
一、认识scrapy
1.简介
scrapy是一个为遍历爬行网站、分解获取数据而设计的应用程序框架,它可以应用在广泛领域:数据挖掘、信息处理和或者历史片(历史记录)打包等等。(来自百度百科)
2.框架架构图
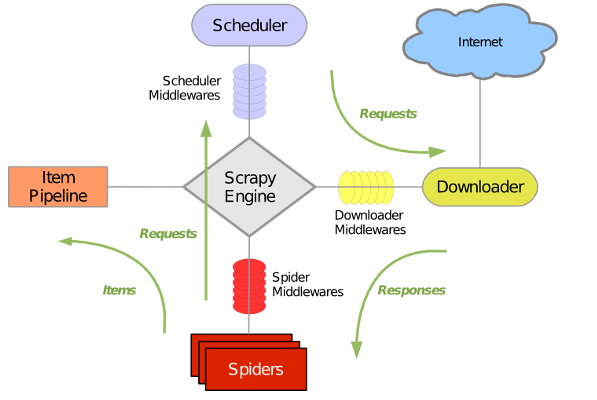
各个模块解释:
1).Scrapy Engine(引擎):整个框架的核心,负责通讯,信号,数据流传输。
2).Scheduler(调度器):用来接受引擎发送过来的请求,相当于url(网址)的优先队列,他来决定爬取的地址是什么,同时去除重复的网址。
3).Downloader(下载器):负责下载request请求并将response相应交还给引擎,再由引擎交给爬虫spider。
4).Spider(爬虫):处理response,分析、提取数据,获取item所需要的字段,并将需要再次爬取的url提交给引擎,再次进行爬取。
5).Item Pipeline(管道):处理spider从网页中获取到的数据实体。
3.运作流程
1).引擎询问spider处理哪个url?
2).spider提交url
3).引擎找到调度器,拿到处理requests请求url,然后再给到引擎
4).引擎找到下载器,下载requests请求,(如果失败,引擎告诉调度器记录稍后处理)
5).引擎找到spider,将下载好的数据交给spider处理
6).spider拿到response数据,分两步:(1)返回给管道处理数据(2)重复第2步,知道url提交处理完毕
注意:只有调度器中不存在任何request请求了,程序才算执行完毕。
4.新建scrapy爬虫的大致思想
1).新建项目:(scrapy startproject xxx)
2).明确目标:我要爬取哪个网站(url),我要的实体字段是什么(编写item文件)
3).制作爬虫:spiders文件夹下创建爬虫(spiders/xxspider.py)
4).存储内容:(pipeline.py)设计管道爬取内容
5.补充(安装scrapy)
确保已经安装了pip(Python包管理工具),执行命令:
sudo pip install scrapy
安装成功之后,输入命令:
scrapy version
可查看版本号。
如安装过程有错请查看此博:===》错误收集。
二、开始第一个项目
scrapy简单易上手,只需按步骤配置好即可。(针对于入门)。下面以我的视角开始第一个scrapy爬虫小项目。
1.新建项目
在保存项目的目录打开终端,执行:scrapy startproject mySpider
会自动创建一个项目,以下是它的目录结构以及简介:
mySpider/
scrapy.cfg:配置文件
myspider/:项目的Python模块,从此处引用代码
_init_.py
items.py:目标文件
pipelines.py:管道文件
settings.py:设置文件
spiders/
_init_.py
xxxspider.py:自定义的爬虫2.明确目标(item)
本次爬取目标是电影网电影排行top100的电影名.(url:http://www.1905.com/vod/top/lst/)
1.打开item.py文件
2.新建一个item类:
#创建一个 FilmItem 类,和构建 item 模型(model)。
class FilmItem(scrapy.Item):
name=scrapy.Field()
3.即类似于ORM映射
3.制作爬虫(spider)
这里创建一个名为film的爬虫,域名为1905.com。
1.在spider文件夹下,执行命令:scrapy genspider film ‘1905.com’
2.得到一个film.py文件,打开:
# -*- coding: utf-8 -*-
import scrapy
class FilmSpider(scrapy.Spider):
#爬虫名字,必须唯一
name = 'film'
#搜索范围,规定爬虫只能爬这个域名的网页
allowed_domains = ['1905.com']
#爬取的url元祖/列表,爬虫从这里开始下载数据,后续url继承
start_urls = ['http://1905.com/']
#解析response的方法,每个url初始化后被调用传回的response作为唯一参数
def parse(self, response):
pass
这个爬虫文件强制三个属性,一个方法,代码块中已有介绍。
3.修改film.py的内容,用命令创建只是是代码规范化,具体操作要以实际情况更改代码,这里代码更改为:
# -*- coding: utf-8 -*-
import scrapy
from mySpider.items import FilmItem
class FilmSpider(scrapy.Spider):
name = 'film'
allowed_domains = ['1905.com']
start_urls = ['http://www.1905.com/vod/top/lst/']
#这个配置很重要,我迷离好久才明白,这个配置可以兼容多个爬虫管道,稍后有详解。
custom_settings = {
'ITEM_PIPELINES': {'mySpider.pipelines.FilmPipeline': 300}
}
def parse(self, response):
#//*[@id="rankWARP"]/div[2]/div/div[1]/div/dl[2]/dt[3]/a
#分析网页源代码,通过xpath获取想要的标签
# ’//‘从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。‘/dt[@class="li03 oh"]:选取所有calss=“li03 oh”的dt元素
films = response.xpath('//dl/dt[@class="li03 oh"]')
for each_film in films:
item=FilmItem()
#'.'当前节点,‘./a/@title’选取a元素的名为title的所有属性。
item['name']=each_film.xpath('./a/@title').extract()[0]
#数据提交给管道
yield item
源代码分析图:(妙招:右键-检查-copy-copyxpath)。

xpath方法解析补充:
1).xpath()返回一个SelectorList 对象
2).xpath().extract()返回一个list(就是系统自带的那个) 里面是一些你提取的内容
3).xpath().extract()[0]返回2中list的第一个元素(如果list为空抛出异常)
4)返回1中SelectorList里的第一个元素(如果list为空抛出异常),和3达成的效果一致
5)4中返回的是一个str(如果Python2为unicode应该), 所以5会返回str的第一个字符
4.编辑管道文件(pipelines.py)
# -*- coding: utf-8 -*-
class FilmPipeline(object):
def process_item(self,item,spider):
#print("我写入文件了")
#暂且先写入文本文件查看效果
with open("top100_film_title.txt",'a') as film:
film.write(item["name"]+'\n')mySpider文件夹下将会创建一个文本文件:
![]()
内容就是爬取到的电影名:

5.保存数据
scrapy保存信息的最简单的方法主要有四种:
1)-o 输出指定格式的文件,命令如下:
scrapy crawl itcast -o teachers.json2)json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl3)csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv4)xml格式
scrapy crawl itcast -o teachers.xml例如,保存为json格式:
执行:
![]()
结果(二进制码没关系,.encode("utf8")解码即可):

大功告成,这就是最简单的scrapy入门爬虫项目。
最后,我想说杨玉清我喜欢你❤~哈哈彩蛋~❤