题目
面试题目是这样子的:
两个单词如果包含相同的字母,次序不同,则称为字母易位词(anagram)。例如,“silent”和“listen”是字母易位词,而“apple”和“aplee”不是易位词。请定义函数检查两个单词是否是字母易位词。可以假设两个单词字母均为小写。要求算法复杂度尽量低。
看到这个题目,你的思路是什么?
思路一
首先,最基本的思路,便是检测字符串s1中的字符是否都出现在s2中(在s1和s2长度一样的前提下)。为了解决“apple”和“aplee”不是易位词的这种情况,不能仅仅判断出现在s2中就可以了,还需要做个标记。这里可以考虑将字符串转换为list,对于比较过的便设置为None。算法代码设计如下:
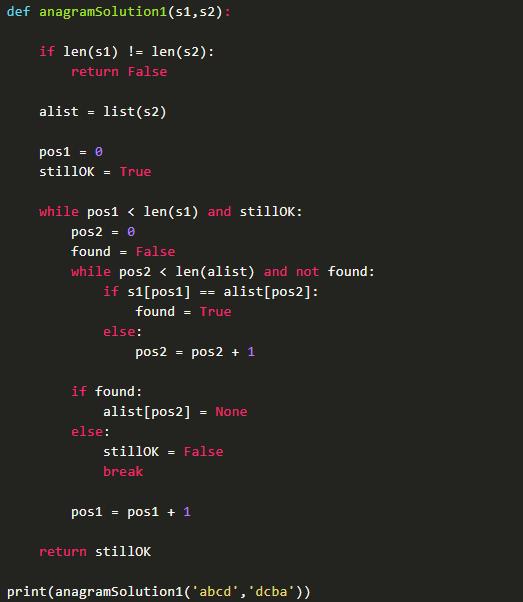
让我们考虑一下算法复杂度。可以从字符串s2来考虑,对于s2中的每个元素,s1都会从头开始进行遍历一次,所以算法的复杂度为:

即算法的复杂度为O(n^2)。
有没有算法复杂度更低的思路呢?思考一下。

思路二
通过题目,我们可以想到,字母易位词即为各个字母的数目相同,而顺序不一致。因而,如果对字符串按照字母顺序排序后,那么两个字符串应该完全一致。这样算法复杂度是否更低?
先看一下代码实现如下:
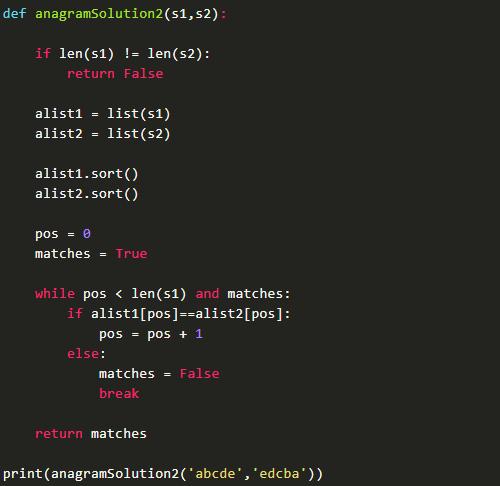
这样算法复杂度是否是O(n)了呢?因为仅仅进行了n次比较啊。当然不是,为什么呢?因为事先先对两个字符串进行了排序,而排序的复杂度并未计入。所以,此种算法的复杂度即为O(n*logn+n),为O(n*logn)。复杂度比思路一的复杂度降低了。
有没有复杂度更低的算法呢?
思路三
思路二利用了字母易位词即为各个字母的数目相同,而顺序不一致。我们从另外一个角度思考,字母一共有多少个?很明显,只有26个(只考虑小写字母)。那么,我们可以为字符串s1和s2分别设置26个计数器,然后判断这对应位置的计数是否相等,如果对应计数完全相等,则为字母易位词。算法代码实现如下:
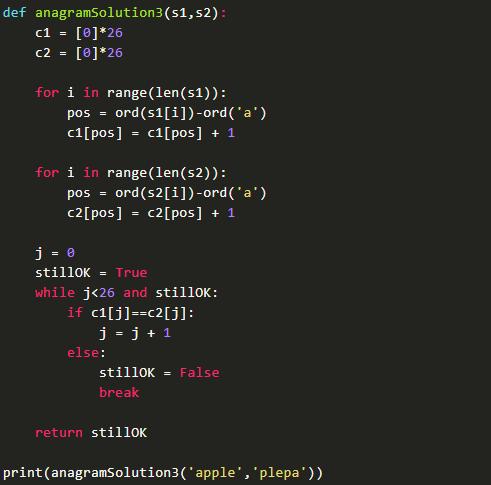
算法的复杂度为O(n + n + 26) ,即为O(n),为线性复杂度的算法。
前几天,一直在跟同事讨论怎么面试考察思维反应能力,