新人小白,不对请指教谢谢,因为只是弄了个简单的测试所以名字就没有过多的要求了,希望各位见谅。
转载请声明原文:https://blog.csdn.net/qq_41210534/article/details/86591330
DELETE
FROM
a
WHERE
id IN (
SELECT
s.id
FROM
(
SELECT
a.id
FROM
a
WHERE
a.id NOT IN (
SELECT
id
FROM
a
GROUP BY
c_1,
c_2
)
) s
);
上面是全部的删除语句具体数据借鉴了刘宇LY的博客,我还做了些许数据增加

下面我来解释下这条SQL
首先查询出重复的数据的id
SELECT
s.id
FROM
(
SELECT
a.id
FROM
a
WHERE
a.id NOT IN (
SELECT
id
FROM
a
GROUP BY
c_1,
c_2
)
) s
使用了子查询,这里将查询结果设置别名s方便后面操作,GROUP BY 后面我觉得应该是判断数据是否重复的条件
SELECT
id
FROM
a
GROUP BY
c_1,
c_2
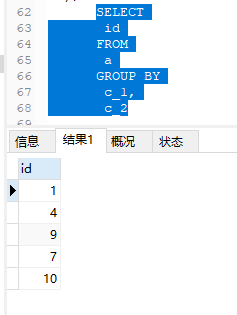
子查询最里面的这一句主要是根据判断条件获得id,可以看到我和1相同的还有2,3。但经过判断后只查出来1,所以这里选择了 a.id NOT IN 来进行下一步的排除,因为这个也处于子查询中所以条件我想主要还是里面的 GROUP BY 那么这里使用 NOT IN 出错的可能性也能减少
最外层删除的判断采用了 IN 主要是担心返回的数据不止一条

又采用了一层子查询,可能可以减少掉这一层,还有其他事情就没去测试了,
最后将这些结果作为 IN 中的条件进行删除。