Spark调优—上篇
更好的序列化实现
Spark用到序列化的地方
1)Shuffle时需要将对象写入到外部的临时文件。
2)每个Partition中的数据要发送到worker上,spark先把RDD包装成task对象,将task通过
网络发给worker。
3)RDD如果支持内存+硬盘,只要往硬盘中写数据也会涉及序列化。
默认使用的是java的序列化。但java的序列化有两个问题,一个是性能相对比较低,另外它序
列化完二进制的内容长度也比较大,造成网络传输时间拉长。业界现在有很多更好的实现,如
kryo,比java的序列化快10倍以上。而且生成内容长度也短。时间快,空间小,自然选择它
了。
方法一:修改spark-defaults.conf配置文件
设置:
spark.serializer org.apache.spark.serializer.KryoSerializer
注意:用空格隔开
方法二:启动spark-shell或者spark-submit时配置
–conf spark.serializer=org.apache.spark.serializer.KryoSerializer
方法三:在代码中
val conf = new SparkConf()
conf.set(“spark.serializer”,“org.apache.spark.serializer.KryoSerializer”)
三种方式实现效果相同,优先级越来越高。
通过代码使用Kryo
文件数据:
rose 23
tom 25
Person类代码:
class Person(var1:String,var2:Int) extends Serializable{
var name=var1
var age=var2
}
MyKryoRegister类代码:
import org.apache.spark.serializer.KryoRegistrator
import com.esotericsoftware.kryo.Kryo
class MyKryoRegister extends KryoRegistrator {
def registerClasses(kryo: Kryo): Unit = {
kryo.register(classOf[Person])
}
}
KryoDriver代码:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.storage.StorageLevel
object KryoDriver {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster(“local”).setAppName(“kryoTest”)
.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
.set(“spark.kryo.registrator”, “cn.tedu.MyKryoRegister”)
val sc = new SparkContext(conf)
val data=sc.textFile(“d://people.txt”)
val userData=data.map { x => new Person(x.split(" “)(0),x.split(” ")(1).toInt) }
userData.persist(StorageLevel.MEMORY_AND_DISK)
userData.foreach(x=>println(x.name))
}
}
Spark调优—中篇
配置多临时文件目录
spark.local.dir参数。当shuffle、归并排序(sort、merge)时都会产生临时文件。这些临时
文件都在这个指定的目录下。那这个文件夹有很多临时文件,如果都发生读写操作,有的线程
在读这个文件,有的线程在往这个文件里写,磁盘I/O性能就非常低。
怎么解决呢?可以创建多个文件夹,每个文件夹都对应一个真实的硬盘。假如原来是3个程序
同时读写一个硬盘,效率肯定低,现在让三个程序分别读取3个磁盘,这样冲突减少,效率就
提高了。这样就有效提高外部文件读和写的效率。怎么配置呢?只需要在这个配置时配置多个
路径就可以。中间用逗号分隔。
spark.local.dir=/home/tmp,/home/tmp2
然后需要把每个目录挂载到不同的磁盘上
启用推测执行机制
可以设置spark.speculation true
开启后,spark会检测执行较慢的Task,并复制这个Task在其他节点运行,最后哪个节点先运
行完,就用其结果,然后将慢Task 杀死
collect速度慢
我们在讲的时候一直强调,collect只适合在测试时,因为把结果都收集到Driver服务器上,数
据要跨网络传输,同时要求Driver服务器内存大,所以收集过程慢。解决办法就是直接输出到
分布式文件系统中。
有些情况下,RDD操作使用MapPartitions替代map
map方法对RDD的每一条记录逐一操作。mapPartitions是对RDD里的每个分区操作
rdd.map{ x=>conn=getDBConn.conn;write(x.toString);conn close;}
这样频繁的链接、断开数据库,效率差。
rdd.mapPartitions{(record:=>conn.getDBConn;for(item<-recorders;
write(item.toString);conn close;}
这样就一次链接一次断开,中间批量操作,效率提升。
扩展:重要源码解读
SparkConf类
/**
- Configuration for a Spark application. Used to set various Spark parameters as key-value pairs.
- Most of the time, you would create a SparkConf object with
new SparkConf(), which will load - values from any
spark.*Java system properties set in your application as well. In this case, - parameters you set directly on the
SparkConfobject take priority over system properties. - For unit tests, you can also call
new SparkConf(false)to skip loading external settings and - get the same configuration no matter what the system properties are.
- All setter methods in this class support chaining. For example, you can write
new SparkConf().setMaster("local").setAppName("My app").- @param loadDefaults whether to also load values from Java system properties
- @note Once a SparkConf object is passed to Spark, it is cloned and can no longer be modified
- by the user. Spark does not support modifying the configuration at runtime.
/
SparkContext实例化的时候需要传进一个SparkConf作为参数,SparkConf描述整个Spark应用程序的配置信息,
SparkConf可以进行链式的调用,即:
new SparkConf().setMaster(“local”).setAppName(“TestApp”)
SparkConf的部分源码如下:
// 用来存储key-value的配置信息
private val settings = new ConcurrentHashMapString, String
// 默认会加载“spark.”格式的配置信息
if (loadDefaults) {
// Load any spark.* system properties
for ((key, value) <- Utils.getSystemProperties if key.startsWith(“spark.”)) {
set(key, value)
}
}
/** Set a configuration variable. */
def set(key: String, value: String): SparkConf = {
if (key == null) {
throw new NullPointerException(“null key”)
}
if (value == null) {
throw new NullPointerException("null value for " + key)
}
logDeprecationWarning(key)
settings.put(key, value)
// 每次进行设置后都会返回SparkConf自身,所以可以进行链式的调用
this
}
SparkContext类
/**
- Main entry point for Spark functionality. A SparkContext represents the connection to a Spark
- cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
- Only one SparkContext may be active per JVM. You must
stop()the active SparkContext before - creating a new one. This limitation may eventually be removed; see SPARK-2243 for more details.
- @param config a Spark Config object describing the application configuration. Any settings in
- this config overrides the default configs as well as system properties.
/
SparkContext是整个Spark功能的入口,代表了应用程序与整个集群的连接点,
Spark应用程序是通过SparkContext发布到Spark集群的,并且Spark程序的运行都是在SparkContext为核心的调
度指挥下进行的,SparkContext崩溃或者结束就代表Spark应用程序执行结束,所以SparkContext在Spark中是非
常重要的一个类。
SparkContext部分源码(只选取重要部分):
SparkContext最主要的作用:①初始化SparkEnv对象②初始化并启动三个调度模块DAG,Task,Backend,此外,会建立
各个工作节点的心跳机制,用于检测和监控
// 是否允许存在多个SparkContext,默认是false
// If true, log warnings instead of throwing exceptions when multiple SparkContexts are active
private val allowMultipleContexts: Boolean =
config.getBoolean(“spark.driver.allowMultipleContexts”, false)
// An asynchronous listener bus for Spark events
private[spark] val listenerBus = new LiveListenerBus
// 追踪所有执行持久化的RDD
// Keeps track of all persisted RDDs
private[spark] val persistentRdds = new TimeStampedWeakValueHashMap[Int, RDD[_]]
// System property spark.yarn.app.id must be set if user code ran by AM on a YARN cluster
if (master == “yarn” && deployMode == “cluster” && !_conf.contains(“spark.yarn.app.id”)) {
throw new SparkException("Detected yarn cluster mode, but isn’t running on a cluster. " +
“Deployment to YARN is not supported directly by SparkContext. Please use spark-submit.”)
}
// Create the Spark execution environment (cache, map output tracker, etc)
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
//设置executor进程的大小,默认1GB
_executorMemory = _conf.getOption(“spark.executor.memory”)
.orElse(Option(System.getenv(“SPARK_EXECUTOR_MEMORY”)))
.orElse(Option(System.getenv(“SPARK_MEM”))
.map(warnSparkMem))
.map(Utils.memoryStringToMb)
.getOrElse(1024)
// We need to register “HeartbeatReceiver” before “createTaskScheduler” because Executor will
// retrieve “HeartbeatReceiver” in the constructor.
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.askBoolean
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler’s
// constructor
_taskScheduler.start()
_env.blockManager.initialize(_applicationId)
_env.metricsSystem.start()
}
其实SparkContext中最主要的三大核心对象就是DAGScheduler、TaskScheduler、SchedulerBackend
1)DAGScheduler主要负责分析依赖关系,然后将DAG划分为不同的Stage(阶段),其中每个Stage由可以并发
执行的一组Task构成,这些Task的执行逻辑完全相同,只是作用于不同的数据。
2)TaskScheduler作用是为创建它的SparkContext调度任务,即从DAGScheduler接收不同Stage的任务,并且向
集群提交这些任务,并为执行特别慢的任务启动备份任务
3)SchedulerBackend作用是依据当前任务申请到的可用资源,将Task在Executor进程中启动并执行,完成计算
的调度过程。
SparkEnv
/* - :: DeveloperApi ::
- Holds all the runtime environment objects for a running Spark instance (either master or worker),
- including the serializer, RpcEnv, block manager, map output tracker, etc. Currently
- Spark code finds the SparkEnv through a global variable, so all the threads can access the same
- SparkEnv. It can be accessed by SparkEnv.get (e.g. after creating a SparkContext).
*/
SparkEnv是Spark的执行环境对象,其中包括但不限于:
1)serializer
2)RpcEnv
3)BlockManager
4)MapOutPutTracker(Shuffle过程中非常重要)等
在local模式下Driver会创建Executor,在Standalone部署模式下,Worker上创建Executor。所以SparkEnv存在
于Spark任务调度时的每个Executor中,SparkEnv中的环境信息是对一个job中所有的Task都是可见且一致的。确
保运行时的环境一致。
SparkEnv的构造步骤如下:
- 创建安全管理器SecurityManager;
Spark currently supports authentication via a shared secret. Authentication can be configured to be on via the
spark.authenticate configuration parameter. This parameter controls whether the Spark communication protocols do
authentication using the shared secret. This authentication is a basic handshake to make sure both sides have the same
shared secret and are allowed to communicate. If the shared secret is not identical they will not be allowed to
communicate. The shared secret is created as follows:
For Spark on YARN deployments, configuring spark.authenticate to true will automatically handle generating and
distributing the shared secret. Each application will use a unique shared secret.
For other types of Spark deployments, the Spark parameter spark.authenticate.secret should be configured on each of
the nodes. This secret will be used by all the Master/Workers and applications.
SecurityManager是Spark的安全认证模块,通过共享秘钥进行认证。启用认证功能可以通过参数
spark.authenticate来配置。此参数控制spark通信协议是否使用共享秘钥进行认证。这种认证方式基于握手机制,
以确保通信双方都有相同的共享秘钥时才能通信。如果共享秘钥不一致,则双方将无法通信。可以通过以下过程来
创建共享秘钥:
①在spark on YARN部署模式下,配置spark.authenticate为true,就可以自动产生并分发共享秘钥。每个应用程
序都使用唯一的共享秘钥。
②其他部署方式下,应当在每个节点上都配置参数spark.authenticate.secret。此秘钥将由所有Master、worker
及应用程序来使用。
spark.authenticate.secret=001
2. 创建RpcEnv;
Spark1.6推出的RpcEnv、RpcEndPoint、RpcEndpointRef为核心的新型架构下的RPC通信方式,在底层封装了
Akka和Netty,也为未来扩充更多的通信系统提供了可能。
①如果底层用的是Akka的RPC通信
RpcEnv=ActorSystem
RpcEndPoint=Actor
RpcEndpointRef=Actor通信的对象
②如果底层用的是Netty的RPC通信
RpcEnv=NettyServer
RpcEndPoint=NettyClient
RpcEndpointRef=NettyClient的通信对象
Spark1.6之前用的是Akka,1.6之后用的是Netty
3. 创建ShuffleManager
4. ShuffleManager负责管理本地及远程的Block数据的shuffle操作。ShuffleManager默认通过反射方式生成的
SortShuffleManager的实例。默认使用的是sort模式的SortShuffleManager,当然也可以通过修改属性
spark.shuffle.manager为hash来显式控制使用HashShuffleManager。
4. 创建Shuffle Map Task任务输出跟踪器MapOutputTracker
MapOutputTracker用于跟踪Shuffle Map Task任务的输出状态,
此状态便于Result Task任务获取地址及中间结果。
Result Task 会到各个Map Task 任务的所在节点上拉取Block,这一过程叫做Shuffle。
MapOutputTracker 有两个子类:
①MapOutputTrackerMaster(for driver)
②MapOutputTrackerWorker(for executors)
shuffleReader读取shuffle文件之前就是去请求MapOutputTrackerMaster
要自己处理的数据在哪里?
MapOutputTrackerMaster给它返回一批
MapOutputTrackerWorker的列表(地址,port等信息)
然后进行shuffleReader
5. 内存管理器MemoryManager
spark的内存管理有两套方案,新旧方案分别对应的类是UnifiedMemoryManager和StaticMemoryManager。
旧方案是静态的,storageMemory(存储内存)和executionMemory(执行内存)拥有的内存是独享的不可相互
借用,故在其中一方内存充足,另一方内存不足但又不能借用的情况下会造成资源的浪费。新方案是统一管理的,
初始状态是内存各占一半,但其中一方内存不足时可以向对方借用,对内存资源进行合理有效的利用,提高了整体
资源的利用率。
Spark的内存管理,是把内存分为两大块,包括storageMemory和executionMemory。其中storageMemory用
来缓存rdd,unroll partition,direct task result、广播变量等。executionMemory用于
shuffle、join、sort、aggregation 计算中的缓存。除了这两者以外的内存都是预留给系统的。每个Executor进程
都有一个MemoryManager。
MemoryManager 的选择是由spark.memory.useLegacyMode来控制的,默认是使用UnifiedMemoryManager
来管理内存。用的是动态管理机制。即存储缓存和执行缓存可以相互借用,动态管理的优势在于可以充分里用缓
存,不会出现一块缓存紧张,而另外一块缓存空闲的情况。
6. 创建块传输服务NettyBlockTransferService
NettyBlockTransferService使用Netty提供的网络应用框架,提供web服务及客户端,获取远程节点上Block的集
合。底层的fetchBlocks方法用于获取远程shuffle文件中的数据。
7. 创建BlockManagerMaster
BlockManagerMaster负责对BlockManager的管理和协调
8. 创建块管理器BlockManager
/**
- Manager running on every node (driver and executors) which provides interfaces for putting and
- retrieving blocks both locally and remotely into various stores (memory, disk, and off-heap).
*/

如上图所示,每一个Executor进程创建时,都会创建一个BlockManager,而所有的BlockManager都由
BlockManagerMaster来管理。
BlockManager主要提供了读取和写数据的接口,可以从本地或者是远程读取和写数据,读写数据可以基于内存、
磁盘或者是堆外空间 (OffHeap)。
9. 创建广播管理器BroadcastManager
BroadcastManager用于将配置信息、序列化后的RDD以及ShuffleDependency等信息在本地存储。 此外,
BroadcastManager会将数据从一个节点广播到其他的节点上。例如Driver上有一张表,而Executor中的每个并行
执行的Task(100万个)都要查询这张表,那我们通过广播的方式就只需要往每个Executor把这张表发送一次就行
了。Executor中的每个运行的Task查询这张唯一的表,而不是每次执行的时候都从Driver获得这张表。避免Driver
节点称为性能瓶颈。
Spark的广播机制
当声明一个广播变量时,最终的结果是所有的节点都会收到这个广播变量,Spark底层的实现细节如下:
①驱动程序driver将序列化的对象分为小块并存储在驱动器的blockmanager中。
②根据spark.broadcast.compress配置属性确认是否对广播消息进行压缩,根据spark.broadcast.blockSize配置
属性确认块的大小,默认为4MB。
③为每个block生成BroadcastBlockId(全局唯一且递增)。即driver端会把广播数据分块,每个块做为一个block
存进driver端的BlockManager
④每个executor会试图获取所有的块,来组装成一个完整的broadcast的变量。“获取块”的方法是首先从
executor自身的BlockManager中获取,如果自己的BlockManager中没有这个块,就从别的BlockManager中获
取。这样最初的时候,driver是获取这些块的唯一的源。
⑤但是随着各个BlockManager从driver端获取了不同的块(TorrentBroadcast会有意避免各个executor以同样的顺
序获取这些块),这样做的好处是可以使“块”的源变多。
⑥每个executor就可能从多个源中的一个,包括driver和其它executor的BlockManager中获取块,这要就使得流量
在整个集群中更均匀,而不是由driver作为唯一的源。
10. 创建缓存管理器CacheManager
CacheManager用于管理和持久化RDD

11. 创建监听总线ListenerBus和检测系统MetricsSystem
Spark整个系统运行情况的监控是由ListenerBus以及MetricsSystem 来完成的。spark监听总线
(LiveListenerBus)负责监听spark中的各种事件,比如job启动、各Worker的内存使用率、BlockManager的添
加等等,并通过MetricsSystem展示给UI
12. 创建SparkEnv
当所有的组件准备好之后,最终可以创建执行环境SparkEnv
Spark Sql
概述
Spark为结构化数据处理引入了一个称为Spark SQL的编程模块。它提供了一个称为DataFrame(数
据框)的编程抽象,DF的底层仍然是RDD,并且可以充当分布式SQL查询引擎。
SparkSQL的由来
SparkSQL的前身是Shark。在Hadoop发展过程中,为了给熟悉RDBMS但又不理解MapReduce的技
术人员提供快速上手的工具,Hive应运而生,是当时唯一运行在hadoop上的SQL-on-Hadoop工具。
但是,MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,运行效率较低。
后来,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出
的是:
1)MapR的Drill
2)Cloudera的Impala
3)Shark
其中Shark是伯克利实验室Spark生态环境的组件之一,它基于Hive实施了一些改进,比如引入缓存管
理,改进和优化执行器等,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的
提升。
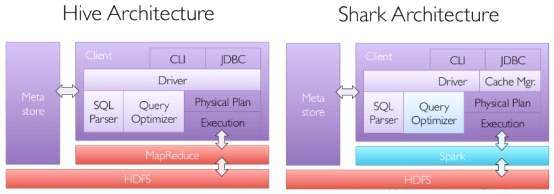
但是,随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于hive的太多依赖(如采用hive
的语法解析器、查询优化器等等),制约了Spark的One Stack rule them all的既定方针,制约了
spark各个组件的相互集成,所以提出了sparkSQL项目。

SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar
Storage)、Hive兼容性等,重新开发了SparkSQL代码。
由于摆脱了对hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方
便。
2014年6月1日,Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队
将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话。
SparkSql特点
1)引入了新的RDD类型SchemaRDD,可以像传统数据库定义表一样来定义SchemaRDD
2)在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行
Join操作。
3)内嵌了查询优化框架,在把SQL解析成逻辑执行计划之后,最后变成RDD的计算
为什么sparkSQL的性能会得到怎么大的提升呢?
主要sparkSQL在下面几点做了优化:
1)内存列存储(In-Memory Columnar Storage)
列存储的优势:
①海量数据查询时,不存在冗余列问题。如果是基于行存储,查询时会产生冗余列,消除冗余列一般在内存中进行的。或者基于行存储的查询,实现物化索引(建立B-tree B+tree),但是物化索引也是
需要耗费cpu的
②基于列存储,每一列数据类型都是同质的,好处一可以避免数据在内存中类型的频繁转换。好处二
可以采用更高效的压缩算法,比如增量压缩算法,二进制压缩算法。性别:男 女 男 女 0101
SparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储,如下
图所示。
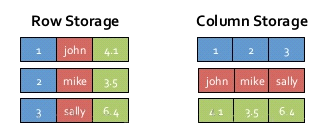
该存储方式无论在空间占用量和读取吞吐率上都占有很大优势。
对于原生态的JVM对象存储方式,每个对象通常要增加12-16字节的额外开销(toString、hashcode
等方法),如对于一个270MB的电商的商品表数据,使用这种方式读入内存,要使用970MB左右的内
存空间(通常是2~5倍于原生数据空间)。
另外,使用这种方式,每个数据记录产生一个JVM对象,如果是大小为200GB的数据记录,堆栈将产
生1.6亿个对象,这么多的对象,对于GC来说,可能要消耗几分钟的时间来处理(JVM的垃圾收集时
间与堆栈中的对象数量呈线性相关。显然这种内存存储方式对于基于内存计算的spark来说,很昂贵也
负担不起)
SparkSql的存储方式:对于内存列存储来说,将所有原生数据类型的列采用原生数组来存储,将Hive
支持的复杂数据类型(如array、map等)先序化后并接成一个字节数组来存储。
此外,基于列存储,每列数据都是同质的,所以可以降低数据类型转换的CPU消耗。此外,可以采用
高效的压缩算法来压缩,是的数据更少。比如针对二元数据列,可以用字节编码压缩来实现
(010101)
这样,每个列创建一个JVM对象,从而可以快速的GC和紧凑的数据存储;额外的,还可以使用低廉
CPU开销的高效压缩方法(如字典编码、行长度编码等压缩方法)降低内存开销;更有趣的是,对于
分析查询中频繁使用的聚合特定列,性能会得到很大的提高,原因就是这些列的数据放在一起,更容
易读入内存进行计算。
SparkSQL入门
概述
SparkSql将RDD封装成一个DataFrame对象,这个对象类似于关系型数据库中的表。
创建DataFrame对象
DataFrame就相当于数据库的一张表。它是个只读的表,不能在运算过程再往里加元素。
RDD.toDF(“列名”)
scala> val rdd = sc.parallelize(List(1,2,3,4,5,6))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at
:21
scala> rdd.toDF(“id”)
res0: org.apache.spark.sql.DataFrame = [id: int]
scala> res0.show#默认只显示20条数据
±–+
| id|
±–+
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
±–+
scala> res0.printSchema #查看列的类型等属性
root
|-- id: integer (nullable = true)
创建多列DataFrame对象
DataFrame就相当于数据库的一张表。
scala> sc.parallelize(List( (1,“beijing”),(2,“shanghai”) ) )
res3: org.apache.spark.rdd.RDD[(Int, String)] = ParallelColl
res3: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[5] at parallelize at
:22
scala> res3.toDF(“id”,“name”)
res4: org.apache.spark.sql.DataFrame = [id: int, name: string]
scala> res4.show
±–±-------+
| id| name|
±–±-------+
| 1| beijing|
| 2|shanghai|
±–±-------+
例如3列的
scala> sc.parallelize(List( (1,“beijing”,100780),(2,“shanghai”,560090),(3,“xi’an”,600329)))
res6: org.apache.spark.rdd.RDD[(Int, String, Int)] = ParallelCollectionRDD[10] at
parallelize at :22
scala> res6.toDF(“id”,“name”,“postcode”)
res7: org.apache.spark.sql.DataFrame = [id: int, name: string, postcode: int]
scala> res7.show
±–±-------±-------+
| id| name|postcode|
±–±-------±-------+
| 1| beijing| 100780|
| 2|shanghai| 560090|
| 3| xi’an| 600329|
±–±-------±-------+
可以看出,需要构建几列,tuple就有几个内容。
由外部文件构造DataFrame对象
1)txt文件
txt文件不能直接转换成,先利用RDD转换为tuple。然后toDF()转换为DataFrame。
scala> val rdd = sc.textFile("/root/words.txt")
.map( x => (x,1) )
.reduceByKey( (x,y) => x+y )
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[18] at reduceByKey at
:21
scala> rdd.toDF(“word”,“count”)
res9: org.apache.spark.sql.DataFrame = [word: string, count: int]
scala> res9.show
±-----±----+
| word|count|
±-----±----+
| spark| 3|
| hive| 1|
|hadoop| 2|
| big| 2|
| scla| 1|
| data| 1|
±-----±----+
2)json文件
文件代码:
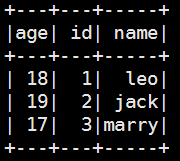
{“id”:1, “name”:“leo”, “age”:18}
{“id”:2, “name”:“jack”, “age”:19}
{“id”:3, “name”:“marry”, “age”:17}
代码:
import org.apache.spark.sql.SQLContext
scala>val sqc=new SQLContext(sc)
scala> val tb4=sqc.read.json("/home/software/people.json")
scala> tb4.show
3)parquet文件
- 什么是Parquet数据格式?
Parquet是一种列式存储格式,可以被多种查询引擎支持(Hive、Impala、Drill等),并且它
是语言和平台无关的。 - Parquet文件下载后是否可以直接读取和修改呢?
Parquet文件是以二进制方式存储的,是不可以直接读取和修改的。Parquet文件是自解析的,
文件中包括该文件的数据和元数据。 - 列式存储和行式存储相比有哪些优势呢?
可以只读取需要的数据,降低IO数据量;
压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编
码进一步节约存储空间。
参考链接:
http://blog.csdn.net/yu616568/article/details/51868447 讲解了parquet文件格式
http://www.infoq.com/cn/articles/in-depth-analysis-of-parquet-column-storage-
format 讲解了parquet列式存储
代码:
scala>val tb5=sqc.read.parquet("/home/software/users.parquet")
scala> tb5.show

4)jdbc读取
实现步骤:
1)将mysql 的驱动jar上传到spark的jars目录下
2)重启spark服务
3)进入spark客户端
4)执行代码,比如在Mysql数据库下,有一个test库,在test库下有一张表为tabx
执行代码:
import org.apache.spark.sql.SQLContext
scala> val sqc = new SQLContext(sc);
scala> val prop = new java.util.Properties
scala> prop.put(“user”,“root”)
scala> prop.put(“password”,“root”)
scala>val tb1=sqc.read.jdbc(“jdbc:mysql://hadoop01:3306/test”,“tb1”,prop)
scala> tabx.show
±–±—+
| id|name|
±–±—+
| 1| aaa|
| 2| bbb|
| 3| ccc|
| 1| ddd|
| 2| eee|
| 3| fff|
±–±—+
注:如果报权限不足,则进入mysql,执行:
grant all privileges on . to ‘root’@‘hadoop01’ identified by ‘root’ with grant option;
然后执行:
flush privileges;
SparkSql基础语法—上
通过方法来使用
(1)查询
df.select(“id”,“name”).show();
(2)带条件的查询
df.select(
“name”).where(
“列名”) 升序排列
orderBy/sort(
“列1” ,
“id”,
“name”.desc).show
df.select(
“name”).sort(
“id”,
“id”,
“score”), min(
"*")).show
(5)连接查询
scala>val dept=sc.parallelize(List((100,“caiwubu”),(200,“yanfabu”))).toDF(“deptid”,“deptname”)
scala>val emp=sc.parallelize(List((1,100,“zhang”),(2,200,“li”),(3,300,“wang”))).toDF(“id”,“did”,“name”)
scala>dept.join(emp,$“deptid” ===
“deptid” ===
“deptid” ===
“num” * 100).show
(7)使用列表
val df = sc.makeRDD(List((“zhang”,Array(“bj”,“sh”)),(“li”,Array(“sz”,“gz”)))).toDF(“name”,“addrs”)
df.selectExpr(“name”,“addrs[0]”).show
(8)使用结构体
{“name”:“陈晨”,“address”:{“city”:“西安”,“street”:“南二环甲字1号”}}
{“name”:“娜娜”,“address”:{“city”:“西安”,“street”:“南二环甲字2号”}}
val df = sqlContext.read.json(“file:///root/work/users.json”)
dfs.select(“name”,“address.street”).show
(9)其他
df.count//获取记录总数
val row = df.first()//获取第一条记录
val take=df.take(2) //获取前n条记录
val value = row.getString(1)//获取该行指定列的值
df.collect //获取当前df对象中的所有数据为一个Array 其实就是调用了df对象对应的底层的rdd的collect方法
SparkSql基础语法—下
通过sql语句来调用
(0)创建表
df.registerTempTable(“tabName”)
(1)查询
val sqc = new org.apache.spark.sql.SQLContext(sc);
val df =
sc.makeRDD(List((1,“a”,“bj”),(2,“b”,“sh”),(3,“c”,“gz”),(4,“d”,“bj”),(5,“e”,“gz”))).toDF(“id”,“name”,“addr”);
df.registerTempTable(“stu”);
sqc.sql(“select * from stu”).show()
(2)带条件的查询
val df =
sc.makeRDD(List((1,“a”,“bj”),(2,“b”,“sh”),(3,“c”,“gz”),(4,“d”,“bj”),(5,“e”,“gz”))).toDF(“id”,“name”,“addr”);
df.registerTempTable(“stu”);
sqc.sql("select * from stu where addr = ‘bj’ ").show()
(3)排序查询
val sqlContext = new org.apache.spark.sql.SQLContext(sc);
val df =
sc.makeRDD(List((1,“a”,“bj”),(2,“b”,“sh”),(3,“c”,“gz”),(4,“d”,“bj”),(5,“e”,“gz”))).toDF(“id”,“name”,“addr”);
df.registerTempTable(“stu”);
sqlContext.sql(“select * from stu order by addr”).show()
sqlContext.sql(“select * from stu order by addr desc”).show()
(4)分组查询
val sqlContext = new org.apache.spark.sql.SQLContext(sc);
val df =
sc.makeRDD(List((1,“a”,“bj”),(2,“b”,“sh”),(3,“c”,“gz”),(4,“d”,“bj”),(5,“e”,“gz”))).toDF(“id”,“name”,“addr”);
df.registerTempTable(“stu”);
sqlContext.sql(“select addr,count(*) from stu group by addr”).show()
(5)连接查询
val sqlContext = new org.apache.spark.sql.SQLContext(sc);
val dept=sc.parallelize(List((100,“财务部”),(200,“研发部”))).toDF(“deptid”,“deptname”)
val emp=sc.parallelize(List((1,100,“张财务”),(2,100,“李会计”),(3,300,“王艳发”))).toDF(“id”,“did”,“name”)
dept.registerTempTable(“deptTab”);
emp.registerTempTable(“empTab”);
sqlContext.sql(“select deptname,name from dept inner join emp on dept.deptid = emp.did”).show()
(6)执行运算
val sqlContext = new org.apache.spark.sql.SQLContext(sc);
val df = sc.makeRDD(List(1,2,3,4,5)).toDF(“num”);
df.registerTempTable(“tabx”)
sqlContext.sql(“select num * 100 from tabx”).show();
(7)分页查询
val sqlContext = new org.apache.spark.sql.SQLContext(sc);

val df = sc.makeRDD(List(1,2,3,4,5)).toDF(“num”);
df.registerTempTable(“tabx”)
sqlContext.sql(“select * from tabx limit 3”).show();
(8)查看表
sqlContext.sql(“show tables”).show
(9)类似hive方式的操作
scala>val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)
scala>hiveContext.sql(“create table if not exists zzz (key int, value string) row
format delimited fields terminated by ‘|’”)
scala>hiveContext.sql(“load data local inpath ‘file:///home/software/hdata.txt’ into
table zzz”)
scala>hiveContext.sql(“select key,value from zzz”).show
(10)案例
val sqlContext = new org.apache.spark.sql.SQLContext(sc);
val df = sc.textFile(“file:///root/work/words.txt”).flatMap{ _.split(" ") }.toDF(“word”)
df.registerTempTable(“wordTab”)
sqlContext.sql(“select word,count(*) from wordTab group by word”).show
SparkSql API
通过api使用sparksql
实现步骤:
1)打开scala IDE开发环境,创建一个scala工程
2)导入spark相关依赖jar包
3)创建包路径以object类
4)写代码
代码示意:
package cn.tedu.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
object Demo01 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster(“spark://hadoop01:7077”).setAppName(“sqlDemo01”);
val sc=new SparkContext(conf)
val sqlContext=new SQLContext(sc)
val rdd=sc.makeRDD(List((1,“zhang”),(2,“li”),(3,“wang”)))
import sqlContext.implicits._
val df=rdd.toDF(“id”,“name”)
df.registerTempTable(“tabx”)
val df2=sqlContext.sql(“select * from tabx order by name”);
val rdd2=df2.toJavaRDD;
//将结果输出到linux的本地目录下,当然,也可以输出到HDFS上
rdd2.saveAsTextFile(“file:///home/software/result”);
}
}
5)打jar包,并上传到linux虚拟机上
6)在spark的bin目录下
执行:sh spark-submit --class cn.tedu.sparksql.Demo01 ./sqlDemo01.jar
7)最后检验
SparkStreaming介绍
概述

Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数
据的能力,以吞吐量高和容错能力强著称。
SparkStreaming VS Storm
大体上两者非常接近,而且都处于快速迭代过程中,即便一时的对比可能某一方占优势。
在Spark老版本中,SparkStreaming的延迟级别达到秒级,而Storm可以达到毫秒级别。而
在最新的2.0版本之后,SparkStreaming能够达到毫秒级。
但后者可能很快就追赶上来。比如在性能方面,Spark Streaming刚发布不久,有基准测试显
示性能超过Storm几十倍,原因是Spark Streaming采用了小批量模式,而Storm是一条消息
一条消息地计算。但后来Storm也推出了称为Trident的小批量计算模式,性能应该不是差距
了。而且双方都在持续更新,底层的一个通信框架的更新或者某个路径的代码优化都可能让性
能有较大的提升。
目前,sparkStreaming还不能达到一条一条记录的精细控制,还是以batch为单位。所以像
Storm一般用于金融领域,达到每笔交易的精细控制。
但是两者的基因不同,更具体地说就是核心数据抽象不同。这是无法改变的,而且也不会轻易
改变,这样的基因也决定了它们各自最适合的应用场景。
Spark Streaming的核心抽象是DSTream,里面是RDD,下层是Spark核心DAG调度,所以
Spark Streaming的这一基因决定了其粒度是小批量的,无法做更精细地控制。数据的可靠性
也是以批次为粒度的,但好处也很明显,就是有可能实现更大的吞吐量。
另外,得益于Spark平台的良好整合性,完成相同任务的流式计算程序与历史批量处理程序的
代码基本相同,而且还可以使用平台上的其他模块比如SQL、机器学习、图计算的计算能力,
在开发效率上占有优势。而Storm更擅长细粒度的消息级别的控制,比如延时可以实现毫秒
级,数据可靠性也是以消息为粒度的。
核心数据抽象的不同导致了它们在计算模式上的本质区别。Spark Streaming在本质上其实是
像MR一样的批处理计算,但将批处理的周期从常规的几十分钟级别尽可能缩短至秒级(毫秒
级),也算达到了实时计算的延时指标。而且,它支持各类数据源,基本可以实现流式计算的
功能,但延时无法进一步缩短了。但Storm的设计初衷就是实时计算,毫秒级的计算当然不在
话下,而且后期通过更高级别的Trident也实现了小批次处理功能。

架构及原理
架构设计
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数
据源(如Kafka、Flume、Twitter、ZeroMQ和TCP 套接字)进行类似Map、Reduce和Join
等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。

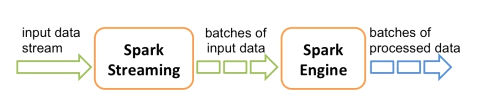
Spark Streaming是将流式计算分解成一系列短小的批处理作业,也就是把Spark Streaming
的输入数据按照batch size(如1秒)分成一段一段的数据DStream(Discretized-离散化
Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将
Spark Streaming中对DStream的Transformations操作变为针对Spark中对RDD的
Transformations操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务
的需求可以对中间的结果进行叠加或者存储到外部设备。
对DStream的处理,每个DStream都要按照数据流到达的先后顺序依次进行处理。即
SparkStreaming天然确保了数据处理的顺序性。
这样使所有的批处理具有了一个顺序的特性,其本质是转换成RDD的血缘关系。所以,
SparkStreaming对数据天然具有容错性保证。
为了提高SparkStreaming的工作效率,你应该合理的配置批的时间间隔, 最好能够实现上
一个批处理完某个算子,下一个批子刚好到来。
SparkStreaming与Kafka整合
代码示例:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.kafka.KafkaUtils
object Driver {
def main(args: Array[String]): Unit = {
//–启动线程数,至少是两个。一个线程用于监听数据源,其他线程用于消费或打印。至
少是2个
val conf=new SparkConf().setMaster(“local[5]”).setAppName(“kafkainput”)
val sc=new SparkContext(conf)
val ssc=new StreamingContext(sc,Seconds(5))
ssc.checkpoint(“d://check1801”)
//–连接kafka,并消费数据
val zkHosts=“192.168.150.137:2181,192.168.150.138:2181,192.168.150.139:2181”
val groupName=“gp1”
//–Map的key是消费的主题名,value是消费的线程数。也可以消费多个主题,比如:
Map(“parkx”->1,“enbook”->2)
val topic=Map(“parkx”->1)
//–获取kafka的数据源
//–SparkStreaming作为Kafka消费的数据源,即从kafka中消费的偏移量(offset)存到
zookeeper上
val kafkaStream=KafkaUtils.createStream(ssc, zkHosts, groupName, topic).map{data=>data._2}
val wordcount=kafkaStream.flatMap { line =>line.split(" ") }.map { word=>(word,1) }
.updateStateByKey{(seq,op:Option[Int])=>Some(seq.sum+op.getOrElse(0))}
wordcount.print()
ssc.start()
//–保持SparkStreaming线程一直开启
ssc.awaitTermination()
}
}