目录
String无疑是Java中使用最频繁的类之一,而String类也有一定的缺陷,随后衍生出了StringBuilder和StringBuffer,当然它们俩也有一定的缺陷。所以我们在选择字符串类型时需要考虑下使用哪个会比较合适。
一、String
1、成员属性
我们先来看一下String类的成员属性(jdk1.7)
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
{
/** The value is used for character storage. */
private final char value[];
/** The offset is the first index of the storage that is used. */
private final int offset;
/** The count is the number of characters in the String. */
private final int count;
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
//......
}可见:
String类其实是通过char数组来保存字符串的
String类是final类,也即意味着String类不能被继承,并且它的成员方法都默认为final方法。在Java中,被final修饰的类是不允许被继承的,并且该类中的成员方法都默认为final方法。
源码的注释中有这一句话:
Strings are constant; their values cannot be changed after theyare created. String buffers support mutable strings.
字符串是常量;它们的值在创建之后不能更改。字符串缓冲区支持可变字符串。
我们可以测试一下:
public class test {
public static void main(String[] args) {
String s = "abc";
System.out.println("s之前的hashCode:"+s.hashCode());
s = "abc" + "1";
System.out.println("s之后的hashCode:"+s.hashCode());
}
}![]()
我们都知道hashcode关联到对象在内存中的存储位置,字符串经过拼接操作后hashcode值改变了,也就是说s这个引用指向了另一个对象"abc1"。可以看一下String操作时内存变化的图:

这就会导致每次对String的操作都会生成新的String对象,短短的两个字符串,却需要开辟三次内存空间,这样不仅效率低下,而且大量浪费有限的内存空间。
2、方法
下面是取子串、拼接以及替换方法的源码:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ? this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
char buf[] = new char[count + otherLen];
getChars(0, count, buf, 0);
str.getChars(0, otherLen, buf, count);
return new String(0, count + otherLen, buf);
}
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = count;
int i = -1;
char[] val = value; /* avoid getfield opcode */
int off = offset; /* avoid getfield opcode */
while (++i < len) {
if (val[off + i] == oldChar) {
break;
}
}
if (i < len) {
char buf[] = new char[len];
for (int j = 0 ; j < i ; j++) {
buf[j] = val[off+j];
}
while (i < len) {
char c = val[off + i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(0, len, buf);
}
}
源码的逻辑清晰易读,可见无论是substring、concat还是replace操作都不是在原有的字符串上进行的,而是重新生成了一个新的字符串对象。也就是说进行这些操作后,最原始的字符串并没有被改变。
三、String字符串常量池
为了解决大量频繁的创建字符串而带来的高昂的时间与空间代价,JVM在堆内存(jdk1.7之后)中为字符串开辟一个字符串常量池,类似于缓存区。创建字符串常量时,首先坚持字符串常量池是否存在该字符串;存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中。
String其中两个实例化方法可以完美理解字符串常量池:
public class test {
public static void main(String[] args) {
String str1 = "hahaha";
String str2 = new String("hahaha");
String str3 = "hahaha";
String str4 = new String("hahaha");
System.out.println(str1==str2);
System.out.println(str1==str3);
System.out.println(str2==str4);
}
}运行结果:
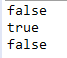
在上述代码中,String str1 = "hahaha";和String str3 = "hahaha"; 都在编译期间生成了 字面常量和符号引用,运行期间字面常量"hahaha"被存储在运行时常量池,只保存了一份)。通过这种方式来将String对象跟引用绑定的话,JVM执行引擎会先在运行时常量池查找是否存在相同的字面常量,如果存在,则直接将引用指向已经存在的字面常量;否则在运行时常量池开辟一个空间来存储该字面常量,并将引用指向该字面常量。
而通过new关键字来生成对象是在堆区进行的,而在堆区进行对象生成的过程是不会去检测该对象是否已经存在的。因此通过new来创建对象,创建出的一定是不同的对象,即使字符串的内容是相同的。
字符串常量池只能解决频繁地重复创建字面量相同字符串。还需要使用Java提供的其他两个操作字符串的类——StringBuffer类和StringBuild类来对此种变化字符串进行处理。
二、StringBuilder&StringBuild
先来看三者的继承结构

和 String 类不同的是,因为实现了Appendable接口,StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。
而StringBuilder和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问)。原因很简单,我们可以看一下StringBuilder和 StringBuffer中的insert方法的源码:
StringBuilder的insert方法:
public StringBuilder insert(int index, char str[], int offset,
int len){
super.insert(index, str, offset, len);
return this;
}StringBuffer的insert方法:
public synchronized StringBuffer insert(int index, char str[], int offset,
int len){
super.insert(index, str, offset, len);
return this;
}事实上,StringBuilder和StringBuffer类拥有的成员属性以及成员方法基本相同,区别是StringBuffer类的成员方法前面多了一个关键字:synchronized,不用多说,这个关键字是在多线程访问时起到安全保护作用的,也就是说StringBuffer是线程安全的。
StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。
具体的方法使用可以参考api手册,就不在此测试了~
不过三者之间的转换可以注意一下:
- String转换成StringBuffer:构造方法和append方法;
- StringBuffer转换成String:构造方法和toString方法。
三、三类对比
| String | StringBuffer | StringBuilder | |
| 对象类型 | 字符串常量。属于不可变类(每次对String的操作都会生成新的String对象),效率低,浪费大量优先的内存空间 | 字符串变量。属于可变类(任何对它指向的字符串的操作都不会产生新的对象)。每个StringBuffer对象都有一定的缓冲区容量,当字符串大小没有超过容量时,不会分配新的容量,当字符串大小超过容量时,会自动增加容量 | 字符串变量。属于可变类,速度更快 |
| 大致执行效率 | 低 | 中 | 高 |
| 线程有关 | 线程不安全 | 多线程操作字符串,线程安全 | 单线程操作字符串,线程不安全 |
| 适用场景 | 操作少,数据少 | 多线程,操作多,数据多 | 单线程,操作多,数据多 |
这三个类各有利弊,应当根据不同的情况来进行选择使用!
接下来我们可以测试一下三类的性能
public class test {
private static int time = 50000;
public static void main(String[] args) {
testString();
testStringBuffer();
testStringBuilder();
}
public static void testString () {
String s="";
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
s += "HappyNewYear";
}
long over = System.currentTimeMillis();
System.out.println("操作"+s.getClass().getName()+"类型使用的时间为:"+(over-begin)+"毫秒");
}
public static void testStringBuffer () {
StringBuffer sb = new StringBuffer();
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
sb.append("HappyNewYear");
}
long over = System.currentTimeMillis();
System.out.println("操作"+sb.getClass().getName()+"类型使用的时间为:"+(over-begin)+"毫秒");
}
public static void testStringBuilder () {
StringBuilder sb = new StringBuilder();
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
sb.append("HappyNewYear");
}
long over = System.currentTimeMillis();
System.out.println("操作"+sb.getClass().getName()+"类型使用的时间为:"+(over-begin)+"毫秒");
}
}运行结果:

对三种类型的的对象进行50000次拼接操作,其效率对比可见一斑!
大致效率:StringBuilder > StringBuffer > String;当然这也不是绝对的,当涉及到很少数目的字符串操作时孰快孰慢就不一定了。
另外,String类型拼接时"直接"拼接和"间接"拼接的效率是不同的(jvm在编译器对String类型的优化):
public class test {
private static int time = 50000;
public static void main(String[] args) {
test1String();
test2String();
}
public static void test1String () {
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
String s = "I"+"love"+"java";
}
long over = System.currentTimeMillis();
System.out.println("字符串直接相加操作:"+(over-begin)+"毫秒");
}
public static void test2String () {
String s1 ="I";
String s2 = "love";
String s3 = "java";
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
String s = s1+s2+s3;
}
long over = System.currentTimeMillis();
System.out.println("字符串间接相加操作:"+(over-begin)+"毫秒");
}
}![]()
也就是说对于直接相加字符串,效率很高,因为在编译器便确定了它的值,也就是说形如"Happy"+"New"+"Year"; 的字符串相加,在编译期间便被优化成了"happyNewYear"。。对于间接相加(即包含字符串引用),形如s1+s2+s3; 效率要比直接相加低,因为在编译器不会对引用变量进行优化。
关于+= 与 + 可以看另外一个例子:
public class test {
private static int time = 50000;
public static void main(String[] args) {
testString();
testString1();
}
public static void testString () {
String s="";
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
s += "Happy";
}
long over = System.currentTimeMillis();
System.out.println("操作 s += 'Happy';型使用的时间为:"+(over-begin)+"毫秒");
}
public static void testString1 () {
String s="";
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
s = s + "Happy";
}
long over = System.currentTimeMillis();
System.out.println("操作 s = s + 'Happy';型使用的时间为:"+(over-begin)+"毫秒");
}
}![]()
原因是s=s+"Happy"操作在编译器期间被优化成"(s的值)Happy",而+=是在运行期间进行拼接操作并赋值。
参考资料
1、https://blog.csdn.net/weixin_41101173/article/details/79677982
2、https://www.cnblogs.com/dolphin0520/p/3778589.html
3、https://blog.csdn.net/danceinkeyboard/article/details/72858374
4、https://blog.csdn.net/jisuanjiguoba/article/details/82531868