数据集的标准化处理
数据集如果标准化处理,对机器学习中的很多算法(包括梯度下降),会有很好的优化(存进)效果。如果数据未标准化(例如,数据集特征之间相差的数量级较大时),很多算法的表现性能不佳。
X[0]
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.model_selection import train_test_split
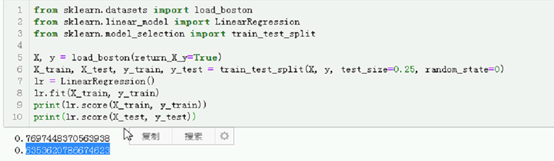
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
lr = LinearRegression()
lr.fit(X_train, y_train)
# 数据集未标准化对线性回归类影响不大。
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
# 数据集未标准化对梯度下降算法影响极大。
sgd = SGDRegressor(eta0=0.01, max_iter=100)
sgd.fit(X_train, y_train)
print(sgd.score(X_train, y_train))
print(sgd.score(X_test, y_test))
我们可以使用sklearn中提供的相关类对数据集进行标准化处理,可以将特征转换成相同的数量级,进而消除数量级不同对算法造成的影响。常用的两种方式:
- StandardScaler
- MinMaxScaler。
StandardScaler 将特征转换为标准正态分布的形式。(均值为0,标准差为1。)
MinMaxScaler 将特征转换(缩放)为指定区间的分布。默认(也是通常情况下),我们将特征缩放到[0, 1],我们也把这种缩放方式成为归一化。
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# s = StandardScaler()
# t = s.fit_transform(X)
# t[0:5]
mm = MinMaxScaler()
t = mm.fit_transform(X)
# t[0:5]
from sklearn.datasets import load_boston
from sklearn.linear_model import SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.pipeline import Pipeline
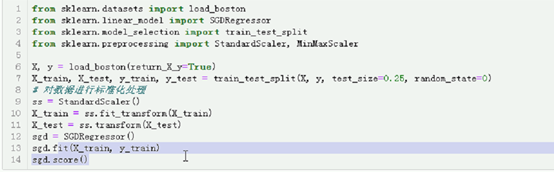
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# # 对数据进行标准化处理
# ss = StandardScaler()
# # ss = MinMaxScaler((-1, 1))
# X_train = ss.fit_transform(X_train)
# X_test = ss.transform(X_test)
# sgd = SGDRegressor(eta0=0.01, max_iter=100)
# sgd.fit(X_train, y_train)
# print(sgd.score(X_train, y_train))
# print(sgd.score(X_test, y_test))
# 可以使用流水线进行处理,简化操作。
pipeline = Pipeline([("ss", StandardScaler()), ("sgd", SGDRegressor(eta0=0.01, max_iter=100))])
pipeline.fit(X_train, y_train)
print(pipeline.score(X_train, y_train))
print(pipeline.score(X_test, y_test))
梯度下降数据标准化与未标准化的对比
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
%matplotlib qt
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"]=False
# 定义原函数
def f(x1, x2):
return 0.05 * x1 ** 2 + x2 ** 2
# 针对x1求梯度值。
def gradient_x1(x1, x2):
return 0.1 * x1
# 针对x2求梯度值。
def gradient_x2(x1, x2):
return 2 * x2
# 定义学习率
alpha = 1.1
# 定义列表,存放x1,x2与y的移动轨迹。
x1_list = []
x2_list = []
y_list = []
# 定义初始点。
x1, x2 = 4.8, 4.5
for i in range(5):
# 使用列表加入x1,x2,与y的轨迹信息。
x1_list.append(x1)
x2_list.append(x2)
y_list.append(f(x1, x2))
# 根据梯度值调整每个自变量。
x1 -= alpha * gradient_x1(x1, x2)
x2 -= alpha * gradient_x2(x1, x2)
X1 = np.arange(-5, 5, 0.1)
X2 = np.arange(-5, 5, 0.1)
X1, X2 = np.meshgrid(X1, X2)
Y = np.array([X1.ravel(), X2.ravel()]).T
Y = f(Y[:, 0], Y[:, 1])
Y = Y.reshape(X1.shape)
fig = plt.figure()
ax = Axes3D(fig)
# 绘制方程曲面。
surf = ax.plot_surface(X1, X2, Y, rstride=5, cstride=5, cmap="rainbow")
# 绘制x1,x2,y的移动轨迹。
ax.plot(x1_list, x2_list, y_list, 'bo--')
# 指定为哪一个图形生成颜色条。
fig.colorbar(surf)
# plt.title("函数$y = 0.2(x1 + x2) ^ {2} - 0.3x1x2 + 0.4$")
plt.show()
m = plt.contourf(X1, X2, Y, 15)
# 在等高线上绘制x1与x2的移动轨迹。
# plt.scatter(x1_list, x2_list, c="r")
plt.plot(x1_list, x2_list, "ro--")
plt.colorbar(m)
进一步解释
数据集长啥样?
其实梯度下降 就是对数据集有要求
Eg. Age列 工资列 数量基相差很大
模型在这个数据集上的表现就会表现的不好
以波斯顿房价数据集
里面有13 个特征 ,
只对xy 感兴趣 不反悔别的

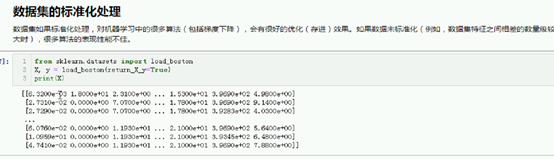
1个就能看出数据集中差距很大

这样很多算法 在砂锅面 力不从心
线性回归 不在乎 因为最小二成
管你表不标准化 ,差的多也没关系 对w影响不大
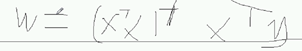
然后进行切割
没必要测试看下效果
已经也可以了 因为boston有很多离群点

将近差不多,但是也还好
还能用
看一下梯度下降是怎么样的

全是复述 而且付了很多

有好一点

最好的才这么一点
所以 梯度下降 量刚不一样个影响极大

回到图,要进行标准化

没有标准化,why表现这么差??
只是因为量纲大x2重要 但其实 他不是

比它重要吗 ,不能说明啊

如果建模的haul,可能就把x2看成最重要的了
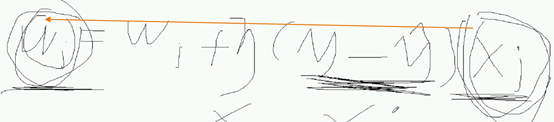
更新公式是:
因为 xj = wj + (y-y_hat)xj
y-y_hat没什么
x之间量纲 不一致,w回收很大影响
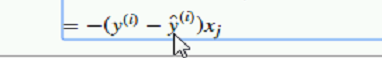
只是因为ix da 造成w大
如何变成同一个数量积?
很多方法
通常使用 两个方法
- 正太分布的
- 最小二乘的

虽然能将特征转换成相同的数量积,进而消除

Stand 将特征转换为标准正态分布的形式
均值为0 标准差为1
缩放

Stand 内部
?????????????没听

精心一下测试
转换后 每一类 均值为0 标准正太分布

变成0到1的区间

虽然差的不大了,但是还是差的不小
多项是处理的时候 fit 是powers
Fit 就是转换器
学习规则
转换的类型,就是fit 转换规则
Stand的就是fit数据激励的均值和标准差
转换的规则就是
Fit设么呢?
Fit最小值 最大值
当前值 – 最小 除以 最大值 – 最小值
计算的就是0到1百分比
接下来就用差距乘以百分比
+最小值
就能缩放到一个区间
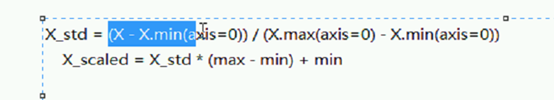
直接看一下r^2值

训练r2 跟线性回归的很接近了

相比 缺失 标准化 效果更好
我们对标准化 stand 进行一个标准正态分布的形式

左边0中心化
均值为0 标准差为1
围绕0对称
就叫0中心化
而特征缩放到 0,1
不是0中心化
深度学习的话 0中心化效果更好
习惯初始化的haul 0中心化
这里面很简单的几个w,没问题
但是神经网络里面
有很多神经值 层次
全部0初始化就没有意义了 习惯上都是正态分布初始化
这样一改也是0中心初始化

标准化
训练fit
transform 转换
麻烦
简化 用流水线处理
pipeline 元祖 阶段 评估器
w1的更新依赖于x1 w2 依赖于x2
如果差不多 比例差不多
相当于物理上的合力
如果量纲差距大 就会出现一个更新特别快 一个更新特别慢
为了不然w 1 发散 震荡
就把

用可视化 看一下 量纲影响的梯度下降
量纲一样,先看均匀的
学习率 alpha调小点,不然看不到求
差20倍 数量积不一样

W1移动非常慢 w2块
看一下图像,是否还是均匀的


横向慢 纵向块
更新幅度不一样 改了啥系数

X2竖直的 一下就更新到了 x1慢
也能求解,但是需要更多的迭代次数 更新
会比平常迭代很多次
就是因为数量积不一样赵成的
如果条块的话 w2 太快 就会呈现发散的
现在是0.8没问题
已经有差不多的情况


X2早到了,x1发散了

改成1.1.
发散了
找不到极值点了

改成就5次

数据不标准化的情况下,也可以求出极值点
但是付出了 学习率小 迭代次数多 的代价