首先来了解下什么是正则表达式?(what)
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。 许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
通俗来说,正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,模式描述在搜索文本时要匹配的一个或多个字符串。
正则表达式的特点是 1.灵活性、逻辑性和功能性非常的强;
2.可以迅速地用极简单的方式达到字符串的复杂控制;
3.对于刚接触的人来说,比较晦涩难懂
正则表达式的分类:
1.普通字符、
2.标准字符、
3.特殊字符、
4.限定字符(又叫量词)
5.定位字符(也叫边界字符)
普通字符
包括字母[a-zA-Z]、数字[0-9]、下划线[-]、汉字,标点符号:
- 匹配字母a可以 regex=a
- 匹配字母b可以 regex=b
- 匹配字母a或者b可以 regex=a|b,这个正则引入一个特殊字符“|”,专业名称为“或”,你也可以叫它“竖线”,它表示“或”的意思。
- 匹配字母a或者b或者c可以 regex=a|b|c
- 匹配字母a或者b或者c或者d可以 regex=a|b|c|d
- 如果匹配所有26个字母,这种写法明显很二(low)了。
这里引入两个特殊字符方括号“[ ]”和中划线“-” 。“[ ]”专业名称为“字符集合”,你也可以叫它“方括号”。“-” 表示“范围”,你也可以叫它“到”,regex=[A-Z] 匹配从A到Z26个字母中的任意一个。
举例来说,那么匹配字母a或者b或者c或者d可以 regex=[abcd]。
匹配数字1到8的任意数字可以 regex=[1-8],这样就不会匹配到0与9这2个数字了,如下:

标准字符集合
标准字符集合是能够与“多种普通字符”匹配的简单表达式,比如:\d、\w、\s。
匹配数字0到9的任意数字可以 regex=[0-9] 也可以 regex=\d。
标准字符集要注意区分大小写,大写是相反的意思。
regex=\D,则匹配非数字字符,即不能匹配数字0到9,如下:

常用的标准字符说明 标黄的要熟记。

特殊字符
特殊字符在正则表达式中表示特殊的含义,比如:*,+,?,\,等等。
- “\”是转义字符,用于匹配特殊字符
- 匹配反斜杠“\”可以 regex=\\,因为“\”是特殊字符,所以需要在它前边再加一个“\”进行转义
- 匹配星号“*”,可以 regex=\,因为“\”是特殊字符,所以需要在它前边再加一个“\”进行转义
常用的特殊字符说明 标黄的要熟记。

限定字符
限定字符又叫量词,是用于表示匹配的字符数量的。
- 匹配任意1位数字可以 regex=\d
- 匹配任意2位数字可以 regex=\d\d
- 匹配任意3位数字可以 regex=\d\d\d
匹配任意8位数字,再这么写就有点二了。这里引入用于表示数量限定字符“{n}”。“{n}”,n是一个非负整数,匹配确定的n次。
注意:regex=\d\d{3} 匹配任意4个数字不是6个,量词只对它前面的字符负责, regex=\d\d{3} 匹配的内容如下:

- 匹配任意8位数字可以 regex=\d{8}
- 匹配任意8位以上的数字可以 regex=\d{8,}
- 匹配任意1到8位以上的数字可以 regex=\d{1,8}

从上图,我们可以看到 regex=\d{1,8},可以匹配到任意1-8个数字,超过8位数字后,从新开始匹配。
注意: 匹配次数中的“贪婪模式”与“非贪婪模式”:
正则的匹配默认是贪婪模式,即匹配的字符越多越好,而非贪婪模式是匹配的字符越少越好,在修饰匹配字数的量词后再加上一个问号“?”即可。
那么同样是上面的字符串,regex=\d{1,8}?匹配到什么呢?

因为在{1,8}这个量词后面加上了问号“?”,表示非贪婪模式,所以只能匹配到1个数字,即匹配的字符越少越好
常用的限定字符说明 标黄的要熟记。

- 匹配0个或多个字母A可以 regex=A* 或者 regex=A{0,}
- 匹配至少一个字母A可以 regex=A+ 或者 regex=A{1,}
- 匹配0个或1字母A可以 regex=A?或者 regex=A{0,1}
- 匹配至少一个 Hello可以 regex=(Hello)+,匹配的效果如下:
![]()
定位字符
定位字符也叫字符边界,标记匹配的不是字符而是符合某种条件的位置,所以定位字符是“零宽的”。
常用的定位字符:

匹配以 Hello 开头的字符串可以 regex=^Hello

匹配以 Hello 结尾的字符串可以 regex=Hello$,如下:
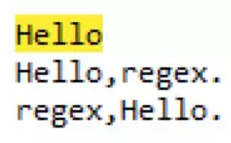
匹配以H开头以o结尾的任意长度字符串可以regex=^H.*o$,如下:
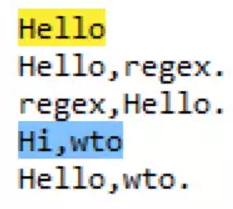
\b匹配这样一个位置:前面的字符和后面的字符不全是\w。如果在“hello,hello1 helloregex,hello regexhello.”这个字符串里匹配regex=hello\b,匹配到的结果如下:

分析一下:为什么 hello1 匹配不了“hello\b”这个正则?
首先\b是一个定位字符,它是零宽的,标识一个位置,这个位置的前面和这个位置的后面不能全是\w,即不能全是字母数字和下划线 [A-Za-z0-9_],而hello1的o与1之间的位置前面是o后面是1,前后全是\w,不符合\b匹配的含义,因此hello1不能匹配正则表达式 “hello\b”。
但是 bhello 可以匹配 “hello\b” 这个正则,因为 hello 的结尾的位置,前面是o,后面是空白,所以符合\b匹配的含义,因此 bhello 可以匹配 “hello\b” 这个正则。
以上是最基础的知识,希望可以帮助可以更好地掌握正则表式。