完整代码
https://github.com/ChenMingK/MNIST-recognization
MNIST数据集压缩包在里面,配好环境后运行CNN.py即可
实验环境
PyCharm, tensorflow(3.5), WIN10
推荐网址:
http://www.tensorfly.cn/tfdoc/tutorials/mnist_pros.html tensorflow官方
https://morvanzhou.github.io/ 莫烦python
https://blog.csdn.net/ling_mochen/article/details/79314118 python&PyCharm环境搭建
https://blog.csdn.net/cs_hnu_scw/article/details/79695347 tensorflow安装教程
实验目的 & 内容
1、了解深度学习的基本原理
2、能够使用深度学习开源工具识别图像中的数字
3、了解图像识别的基本原理
安装开源深度学习工具设计并实现一个深度学习模型,它能够学习识别图像中的数字序列。然后使用数据训练它:你可以使用人工合成的数据(推荐),或直接使用现实数据。
算法原理(搬运莫烦Python)
深度学习概述
深度学习归根结底也是机器学习的一种,如果说要做机器学习分类的话,除了分成监督学习、无监督学习、半监督学习和增强学习之外,从算法网络深度的角度来看还可以分成浅层学习算法和深度学习算法。
深度学习的常见结构
常见结构有DNN,CNN,RNN。DNN是表示有深度学习网络的算法的统称,CNN主要是一种空间概念上的深度学习结构,RNN是时间概念上的深度学习结构。
深度神经网络(DNN)
DNN泛指多层次的神经网络,这些模型的隐藏层之间彼此相连。只是针对处理数据的种类和特点不同,衍生出各种不同的结构,如CNN和RNN。
卷积神经网络(CNN)

举一个识别图片的例子, 我们知道神经网络是由一连串的神经层组成,每一层神经层里面有存在有很多的神经元. 这些神经元就是神经网络识别事物的关键. 每一种神经网络都会有输入输出值, 当输入值是图片的时候, 实际上输入神经网络的并不是那些色彩缤纷的图案,而是一堆堆的数字. 当神经网络需要处理这么多输入信息的时候, 也就是卷积神经网络就可以发挥它的优势的时候了. 那什么是卷积神经网络呢?

我们先把卷积神经网络这个词拆开来看. “卷积” 和 “神经网络”. 卷积也就是说神经网络不再是对每个像素的输入信息做处理了,而是图片上每一小块像素区域进行处理, 这种做法加强了图片信息的连续性. 使得神经网络能看到图形, 而非一个点. 这种做法同时也加深了神经网络对图片的理解. 具体来说, 卷积神经网络有一个批量过滤器, 持续不断的在图片上滚动收集图片里的信息,每一次收集的时候都只是收集一小块像素区域, 然后把收集来的信息进行整理, 这时候整理出来的信息有了一些实际上的呈现, 比如这时的神经网络能看到一些边缘的图片信息, 然后在以同样的步骤, 用类似的批量过滤器扫过产生的这些边缘信息, 神经网络从这些边缘信息里面总结出更高层的信息结构,比如说总结的边缘能够画出眼睛,鼻子等等. 再经过一次过滤, 脸部的信息也从这些眼睛鼻子的信息中被总结出来. 最后我们再把这些信息套入几层普通的全连接神经层进行分类, 这样就能得到输入的图片能被分为哪一类的结果了.

上面是一张猫的图片, 图片有长, 宽, 高 三个参数.这里的高指的是计算机用于产生颜色使用的信息. 如果是黑白照片的话, 高的单位就只有1, 如果是彩色照片, 就可能有红绿蓝三种颜色的信息, 这时的高度为3. 我们以彩色照片为例子. 过滤器就是影像中不断移动的东西, 他不断在图片收集小批小批的像素块, 收集完所有信息后, 输出的值, 我们可以理解成是一个高度更高,长和宽更小的”图片”. 这个图片里就能包含一些边缘信息. 然后以同样的步骤再进行多次卷积, 将图片的长宽再压缩, 高度再增加, 就有了对输入图片更深的理解. 将压缩,增高的信息嵌套在普通的分类神经层上,我们就能对这种图片进行分类了.

研究发现, 在每一次卷积的时候, 神经层可能会无意地丢失一些信息. 这时, 池化 (pooling) 就可以很好地解决这一问题. 而且池化是一个筛选过滤的过程, 能将 layer 中有用的信息筛选出来, 给下一个层分析. 同时也减轻了神经网络的计算负担. 也就是说在卷集的时候, 我们不压缩长宽, 尽量地保留更多信息, 压缩的工作就交给池化了,这样的一项附加工作能够很有效的提高准确性. 有了这些技术,我们就可以搭建一个属于我们自己的卷积神经网络了.

比较流行的一种搭建结构是这样, 从下到上的顺序, 首先是输入的图片(image), 经过一层卷积层 (convolution), 然后在用池化(pooling)方式处理卷积的信息, 这里使用的是 max pooling 的方式. 然后在经过一次同样的处理, 把得到的第二次处理的信息传入两层全连接的神经层 (fully connected),这也是一般的两层神经网络层,最后在接上一个分类器(classifier)进行分类预测
循环神经网络(RNN)
当输入数据具有依赖性且是序列模式时,CNN 的结果一般都不太好。CNN 的前一个输入和下一个输入之间没有任何关联。所以所有的输出都是独立的。CNN 接受输入,然后基于训练好的模型输出。如果你运行了 100 个不同的输入,它们中的任何一个输出都不会受之前输出的影响。但想一下如果是文本生成或文本翻译呢?所有生成的单词与之前生成的单词都是独立的(有些情况下与之后的单词也是独立的,这里暂不讨论)。所以你需要有一些基于之前输出的偏向。这就是需要 RNN 的地方。RNN 对之前发生在数据序列中的事是有一定记忆的。这有助于系统获取上下文。理论上讲,RNN 有无限的记忆,这意味着它们有无限回顾的能力。通过回顾可以了解所有之前的输入。但从实际操作中看,它只能回顾最后几步。

我们想象现在有一组序列数据 data 0,1,2,3. 在当预测 result0 的时候,我们基于的是 data0, 同样在预测其他数据的时候, 我们也都只单单基于单个的数据. 每次使用的神经网络都是同一个 NN. 不过这些数据是有关联 顺序的 , 就像在厨房做菜, 酱料 A要比酱料 B 早放, 不然就串味了. 所以普通的神经网络结构并不能让 NN 了解这些数据之间的关联.

那我们如何让数据间的关联也被 NN 加以分析呢? 想想我们人类是怎么分析各种事物的关联吧, 最基本的方式,就是记住之前发生的事情. 那我们让神经网络也具备这种记住之前发生的事的能力. 再分析 Data0 的时候, 我们把分析结果存入记忆. 然后当分析 data1的时候, NN会产生新的记忆, 但是新记忆和老记忆是没有联系的. 我们就简单的把老记忆调用过来, 一起分析. 如果继续分析更多的有序数据 , RNN就会把之前的记忆都累积起来, 一起分析.

我们再重复一遍刚才的流程, 不过这次是以加入一些数学方面的东西. 每次 RNN 运算完之后都会产生一个对于当前状态的描述 , state. 我们用简写 S( t) 代替, 然后这个 RNN开始分析 x(t+1) , 他会根据 x(t+1)产生s(t+1), 不过此时 y(t+1) 是由 s(t) 和 s(t+1) 共同创造的. 所以我们通常看到的 RNN 也可以表达成这种样子.
RNN的应用
RNN 的形式不单单这有这样一种, 他的结构形式很自由. 如果用于分类问题, 比如说一个人说了一句话, 这句话带的感情色彩是积极的还是消极的. 那我们就可以用只有最后一个时间点输出判断结果的RNN.
又或者这是图片描述 RNN, 我们只需要一个 X 来代替输入的图片, 然后生成对图片描述的一段话.
或者是语言翻译的 RNN, 给出一段英文, 然后再翻译成中文.
有了这些不同形式的 RNN, RNN 就变得强大了. 有很多有趣的 RNN 应用.比如让 RNN 描述照片. 让 RNN 写学术论文, 让 RNN 写程序脚本, 让 RNN 作曲. 我们一般人甚至都不能分辨这到底是不是机器写出来的.
实验流程
构造卷积神经网络并训练

上图为CNN.py的结构图
layer1由第一个卷积层和其池化层组成
layer2由第二个卷积层和其池化层组成
之后数据传入第一个全连接层fc1,然后到第二个全连接层fc2
最后用于计算loss以及更新参数
from __future__ import print_function
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# number 1 to 10 data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 从压缩包采集数据
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
# 定义Weight变量,输入shape,返回变量的一些参数。 ???
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1) # 使用tf.truncted_normal产生随机变量来进行初始化
return tf.Variable(initial)
# 定义bias变量
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape) # 常量函数初始化
return tf.Variable(initial)
"""
定义卷积,tf.nn.conv2d函数是tensoflow里面的二维的卷积函数,x是图片的所有参数,W是此卷积层的权重,然后定义步长strides=[1,1,1,1]值,
strides[0]和strides[3]的两个1是默认值,中间两个1代表padding时在x方向运动一步,y方向运动一步,padding采用的方式是SAME。
"""
def conv2d(x, W):
# stride [1, x_movement, y_movement, 1]
# Must have strides[0] = strides[3] = 1
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# 使用最大值池化
def max_pool_2x2(x):
# stride [1, x_movement, y_movement, 1]
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 占位符
# define placeholder for inputs to network 定义输入的placeholder
xs = tf.placeholder(tf.float32, [None, 784])/255. # 28x28
ys = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32) # dropout的placeholder
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# 对输入的图片reshape:-1:不考虑输入的图片的维度 像素28X28 channel1 灰白图像
# print(x_image.shape) # [n_samples, 28,28,1]
# conv1 layer
"""""
Weight:卷积核patch大小:5X5 channel:1 输出32个featuremap
定义bias,它的大小是32个长度,因此我们传入它的shape为[32]
定义好了Weight和bias,我们就可以定义卷积神经网络的第一个卷积层h_conv1=conv2d(x_image,W_conv1)+b_conv1,同时我们对h_conv1进行非线性处理,
也就是激活函数来处理,这里我们用的是tf.nn.relu(修正线性单元)来处理,要注意的是,因为采用了SAME的padding方式,输出图片的大小没有变化依然是28x28,
只是厚度变厚了,因此现在的输出大小就变成了28x28x32
"""""
#with tf.name_scope('layer1'):
W_conv1 = weight_variable([5, 5, 1, 32]) # patch 5x5, in size 1, out size 32
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # output size 28x28x32 非线性处理(激活函数)
h_pool1 = max_pool_2x2(h_conv1) # 池化缩小长宽output size 14x14x32
# conv2 layer
#with tf.name_scope('layer2'):
W_conv2 = weight_variable([5, 5, 32, 64]) # patch 5x5, in size 32, out size 64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output size 14x14x64
h_pool2 = max_pool_2x2(h_conv2) # output size 7x7x64
# fc1 layer
# 进入全连接层前通过tf.reshape()将h_pool2的输出值从一个三维的变为一维的数据, -1表示先不考虑输入图片例子维度, 将上一个输出结果展平.
#with tf.name_scope('fc1'):
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
# [n_samples, 7, 7, 64] ->> [n_samples, 7*7*64]
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # 考虑过拟合的问题,加一个dropout处理
# fc2 layer 输入是1024,最后输出10(因为mnist数据集就是[0-9]十个类),prediction就是我们最后的预测值
#with tf.name_scope('fc2'):
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) # softmax分类器(多分类,输出是各个类的概率),对我们的输出进行分类
# the error between prediction and real data 利用交叉熵损失函数来定义我们的cost function
#with tf.name_scope('loss'):
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1])) # loss
# tf.summary.scalar('loss', cross_entropy)
# 用tf.train.AdamOptimizer()作为我们的优化器进行优化,更新参数(权值)使我们的cross_entropy最小
#with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess = tf.Session()
#merged = tf.summary.merge_all()
#writer = tf.summary.FileWriter("logs/", sess.graph)
init = tf.global_variables_initializer()
sess.run(init)
saver = tf.train.Saver() # 定义save
# 训练1000次,每50次输出正确率
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5}) # feed_dict喂数据
if i % 50 == 0:
accuracy = compute_accuracy(mnist.test.images[:1000], mnist.test.labels[:1000])
tf.summary.scalar('accuracy', accuracy)
# print(compute_accuracy(mnist.test.images[:1000], mnist.test.labels[:1000]))
print(accuracy)
# result = sess.run(merged, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5})
# writer.add_summary(result, i)
saver.save(sess, 'model/') # 模型储存位置 当前目录model文件夹中注释掉的有些是用来查看tensorboard的(加了之后训练的模型test.py运行会报错......)
模型保存
Tensorflow模型有两个主要的文件:
A) Meta graph:
这是一个保存完整Tensorflow graph的protocol buffer,比如说,所有的 variables, operations, collections等等。这个文件的后缀是 .meta 。
B) Checkpoint file:
这是一个包含所有权重(weights),偏置(biases),梯度(gradients)和所有其他保存的变量(variables)的二进制文件。它包含两个文件:
mymodel.data-00000-of-00001
mymodel.index
其中,.data文件包含了我们的训练变量。
另外,除了这两个文件,Tensorflow有一个叫做checkpoint的文件,记录着已经最新的保存的模型文件。

训练日志及tensorboard观察loss变化曲线

上图为20次训练的正确率变化

分析:loss逐步下降说明我们的模型基本正确,正确率能达到97%。
加载模型并进行图片识别测试
该模块由test.py实现
首先准备好我们的图片:图片尺寸限制28×28(自己画的)
![]()
![]()
![]()
![]()
![]()
运行test.py首先显示读入的图片,关闭图片后输出预测的数字




基本上都能识别出来
思考题
深度算法参数的设置对算法性能的影响?
1.Learning Rate
学习率决定了权值更新的速度,设置得太大会使结果超过最优值,太小会使下降速度过慢。

2、层数
层数越多,灵敏度越好,收敛地更好,激活函数也越多,曲线的性能也更好
但是,神经元过拟合,并且计算量较大层数越多。在节点多的情况下一般会考虑:Drop-out
节点太多也不好,所以需要删除一些无效的节点 。
层数过多可采用drop-out方法。
3、激活函数
激活函数影响计算时间,且不同的问题适用于不同的激活函数。
4、损失函数
不恰当的损失函数会导致参数更新不准确。
还有优化器和分类器的选择等,训练集大小等。
Tips:
Tensorboard使用
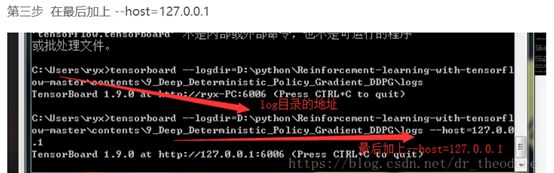
![]()
注意绝对路径相对路径…….要到logs目录下,最后可能要加 --host=127.0.0.1
placeholder的用法
tf.placeholder(dtype, shape=None, name=None)
此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值
dtype:数据类型。常用的是tf.float32,tf.float64等数值类型
shape:数据形状。默认是None,就是一维值,也可以是多维,比如[2,3], [None, 3]表示列是3,行不定
name:名称。
x = tf.placeholder(tf.float32, shape=(1024, 1024))
y = tf.matmul(x, x)
with tf.Session() as sess:
print(sess.run(y)) # ERROR: 此处x还没有赋值.
rand_array = np.random.rand(1024, 1024)
print(sess.run(y, feed_dict={x: rand_array})) # Will succeed.tf.nn.cond2v
tf.nn.conv2d是TensorFlow里面实现卷积的函数,参考文档对它的介绍并不是很详细,实际上这是搭建卷积神经网络比较核心的一个方法,非常重要
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
除去name参数用以指定该操作的name,与方法有关的一共五个参数:
第一个参数input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一
第二个参数filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
第三个参数strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
第四个参数padding:string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式(后面会介绍)
第五个参数:use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map,shape仍然是[batch, height, width, channels]这种形式。