前言
这里记录python中pypdf2模块为什么会报错:NotImplementedError: only algorithm code 1 and 2 are supported。
1 问题描述
pypdf2是python中的处理pdf的一个模块,可以进行读取pdf的页码,建立索引,编辑pdf等有趣的操作。
如何下载并配置pypdf2呢?这里不赘述,请见我的CSDN资源页。
对于一个带有密码的pdf文件,如下:
理论上是可以用pypdf中的的decrypt函数进行密码破解的。
然而,在调用pdfReader.decrypt(password)这个函数的时候,报错,信息如下:
File "D:\software\Anaconda\lib\site-packages\PyPDF2\pdf.py", line 1987, in decrypt
return self._decrypt(password)
File "D:\software\Anaconda\lib\site-packages\PyPDF2\pdf.py", line 1996, in _decrypt
raise NotImplementedError("only algorithm code 1 and 2 are supported")
NotImplementedError: only algorithm code 1 and 2 are supported
2 寻求答案
寻求答案的过程很不容易,所以才写这篇博客,记录如下:
1)从 http://www.cnblogs.com/wj-1314/p/9649837.html 了解到decrypt的基本信息,
2)从 https://jingyan.baidu.com/article/4f7d5712fc6c311a2019279a.html 学到了如何加密pdf文件(福昕阅读器不行,要用Adobe Acrobat)
3)以“NotImplementedError: only algorithm code 1 and 2 are supported”为关键字进行搜索,查找可能的结果
4)从 https://stackoverflow.com/questions/50751267/only-algorithm-code-1-and-2-are-supported 知道多个对应网址及可能解决方案

5)从https://github.com/mstamy2/PyPDF2/issues/378 知道答案:
原来是因为给pdf加密的Adobe Acrobat软件的系统版本太高,然而pypdf2这个模块已经很久没有人维护了。所以导致无法解密。
此外还参考了:https://github.com/mstamy2/PyPDF2/issues/53 (显示除pypdf2之外的解决方案)
https://github.com/mstamy2/PyPDF2/issues/385 (表明pypdf2将被放弃,未来有可能开发pypdf3)
此外,我还通过在spyder中进行代码调试(debug),得知:
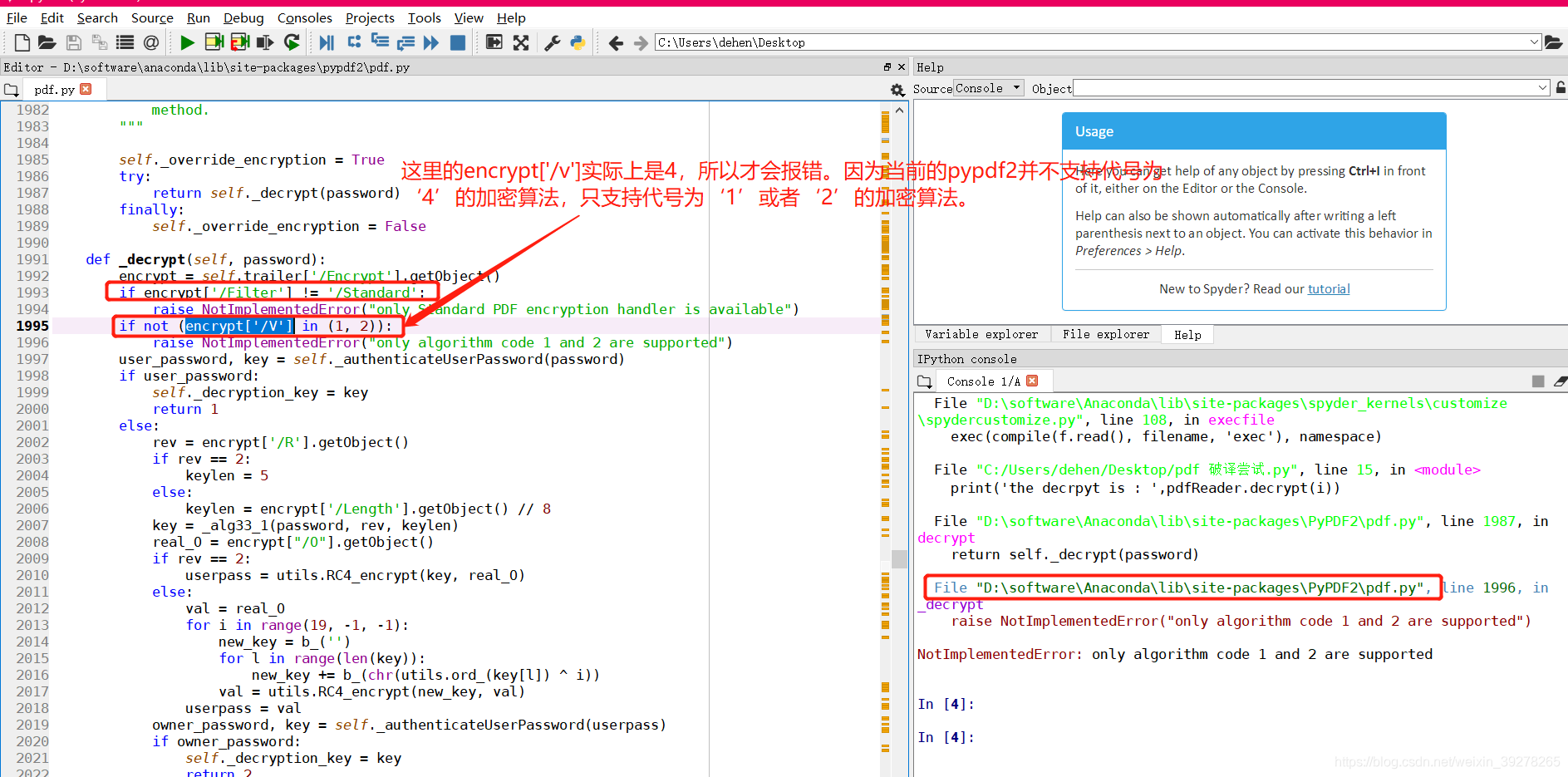
3 总结
所以原因就在于:
1)这个被加密的pdf可能是从高版本的acrobot中来的,所以对应的加密算法代号为‘4’
2)然而,现有的pypdf2模块并只支持加密算法代号为‘1’或者‘2’的pdf加密文件,所以才会报这样的错。
那怎么解决这个错误呢?
我觉得吧,这都是因为pypdf2没有更新(在github上看到的讨论是这个模块快要被放弃维护了,以后打算出pypdf3),所以这才会导致这种不兼容错误吧。
所以只能通过别的途径来破解密码了,或者说pypdf2的解密能力有限,我们也可以试试用更低版本的Adobe Acrobat,看看能不能解密成功。