本文介绍sharding的基本思想和理论上的切分策略
Sharding JDBC:
1:基本思想
Sharding的基本思想就要把一个数据库切分成多个部分放到不同的数据库(server)上 ,从而缓解单一数据库的性能问题。不太严格的讲,对于海量数据的数据库,如果是因为表多,这时候适合使用垂直切分,即把关系紧密(比如同一模块)的表切分出来放在一个server上 ;如果表并不多,但每张表的数据非常多,这时候适合水平切分,即把表的数据按某种规则(比如按ID散列)切分到多个数据库(server)上,现实中更多是这两种情况混杂在一起,这时候需要根据实际情况做出选择,也可能会综合使用垂直与水平切分 .
a)垂直切分:
特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非 常低,相互影响很小,业务逻辑非常清晰的系统 ,将不同业 务模块所使用的表分拆到不同的数据库中 ,及share nothing .
b)水平切分:将同一个表中的不同数据拆 分到不同的数据库中.
因此多数系统会将垂直切分和水平切分联合使用,先对系统做垂直切分,再针对每一小搓表的情况选择性地做水平切分,从而整个数据库切分成一个分布式矩阵 。
2:实例,
电商平台,包含了用户、商品、评价、订单等几大模块,最简单的做法就是在一个数据库中分别创建users、shops、comment、order四张表

但是,随着业务规模的增大,访问量的增大,我们不得不对业务进行拆分。每一个模块都使用单独的数据库来进行存储,不同的业务访问不同的数据库,将原本对一个数据库的依赖拆分为对4个数据库的依赖,这样的话就变成了4个数据库同时承担压力,
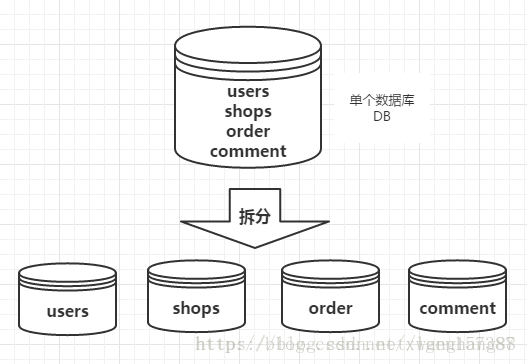
a)分表的实现策略:
对于大部分数据库的设计和业务的操作基本都与用户的ID相关,因此使用用户ID是最常用的分库的路由策略。用户的ID可以作为贯穿整个系统用的重要字段。因此,使用用户的ID我们不仅可以方便我们的查询,还可以将数据平均的分配到不同的数据库中。(当然,还可以根据类别等进行分表操作,分表的路由策略还有很多方式),数据比较大的时候,对数据进行分表操作,首先要确定需要将数据平均分配到多少张表中,也就是:表容量
这里假设有100张表进行存储,则我们在进行存储数据的时候,首先对用户ID进行取模操作,根据 user_id%100 获取对应的表进行存储查询操作
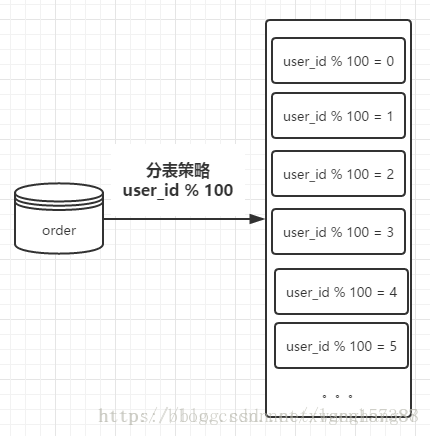
例如,user_id = 101 那么,我们在获取值的时候的操作,可以通过下边的sql语句:
select * from order_1 where user_id= 101 其中,order_1是根据 101%100 计算所得,表示分表之后的第一张order表.
如果你使用MyBatis做持久层的话,MyBatis已经提供了很好得支持数据库分表的功能,例如上述sql用MyBatis实现的话应该是
比如通过userId查询用户信息:
/**
* 获取用户相关的订单详细信息
* @param tableNum 具体某一个表的编号
* @param userId 用户ID
* @return 订单列表
*/
public List<Order> getOrder(@Param("tableNum") int tableNum,@Param("userId") int userId);
xml配置映射文件:
<select id="getOrder" resultMap="BaseResultMap">
select * from order_${tableNum}
where user_id = #{userId}
</select>其中${tableNum} 含义是直接让参数加入到sql中,这是MyBatis支持的特性
需要注意的地方:在实际的开发中,我们的用户ID更多的可能是通过UUID生成的,这样的话,我们可以首先将UUID进行hash获取到整数值,然后在进行取模操作。
b)分表的实现策略:
分库策略与分表策略的实现很相似,最简单的都是可以通过取模的方式进行路由。
数据库分表能够解决单表数据量很大的时候数据查询的效率问题,但是无法给数据库的并发操作带来效率上的提高 ,因为分表的实质还是在一个数据库上进行的操作 ,这个操作就很容易受数据库IO性能的限制。因此,如何将数据库IO性能的问题平均分配出来,将单个数据库分库操作就可以解决单台数据库的IO性能问题。
分库策略与分表策略的实现很相似,最简单的都是可以通过取模的方式进行路由 ,将用户ID进行取模操作,这样的话获取到具体的某一个数据库 ,同样的关键字:库容量
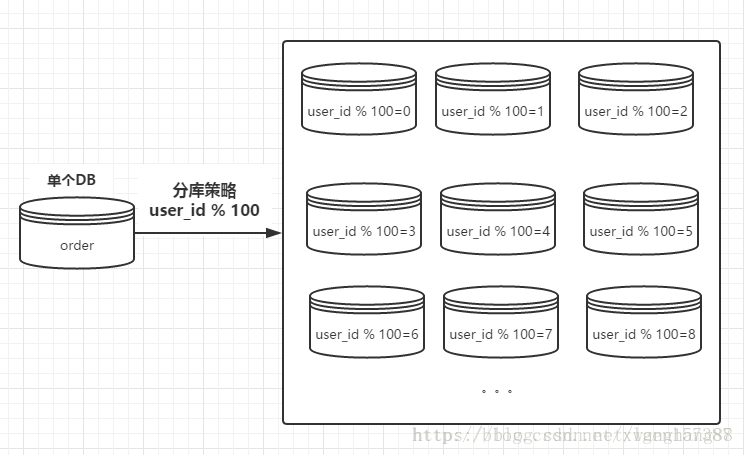
上图中库容量为10
同样,如果用户ID为UUID请先hash然后在进行取模。
3:分库与分表的实现原理:
数据库分表可以解决单表海量数据的查询性能问题,分库可以解决单台数据库的并发访问压力问题,我们要同时考虑这两个问题,因此,我们既需要对单表进行分表操作,还需要进行分库操作,以便同时扩展系统的并发处理能力和提升单表的查询性能,就是我们使用到的分库分表。
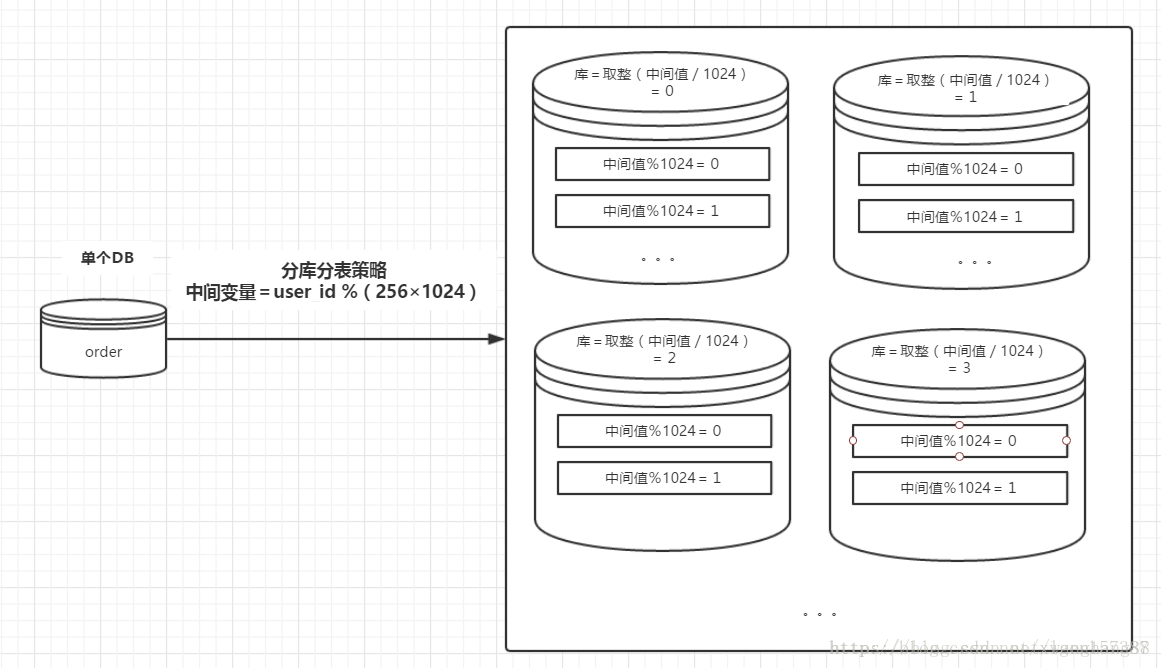
分库分表一种常见的路由策略如下:
1、中间变量 = user_id%(库数量*每个库的表数量);
2、库序号 = 取整(中间变量/每个库的表数量);
3、表序号 = 中间变量%每个库的表数量;
例如:
数据库有256 个,每一个库中有1024个数据表,用户的user_id=262145,按照上述的路由策略,可得:
1、中间变量 = 262145%(256*1024)= 1;
2、库序号 = 取整(1/1024)= 0;
3、表序号 = 1%1024 = 1;对于user_id=262145,将被路由到第0个数据库的第1个表中。
4:关于分库分表的总结:
关于分库分表策略的选择有很多种,上文中根据用户ID应该是比较简单的一种。其他方式比如使用号段进行分区或者直接使用hash进行路由等,hash路由策略的优缺点,优点是:数据分布均匀;缺点是:数据迁移的时候麻烦,不能按照机器性能分摊数据
分库分表之后,原本跨表的事物变成了分布式事物;由于记录被切分到不同的数据库和不同的数据表中,难以进行多表关联查询,并且不能不指定路由字段对数据进行查询。
5:关于分库分表之后的问题:
a)事务问题:
解决事务问题目前有两种可行的方案,分布式事务和通过应用程序与数据库共同控制实现事务。
使用分布式事务 ,
优点:交由数据库管理,
缺点:性能代价高,特别是shard越来越多时 ;
由应用程序和数据库共同控制 ,
原理:将一个跨多个数据库的分布式事务分拆成多个仅处于单个数据库上面的小事务,并通过应用程序来总控 各个小事务。
优点:性能上有优势,
缺点:需要应用程序在事务控制上做灵活设计。如果使用了spring的事务管理,改动起来会面临一定的困难;
b)跨节点Join的问题:
只要是进行切分,跨节点Join的问题是不可避免的。但是良好的设计和切分却可以减少此类情况的发生。解决这一问题的普遍做法是分两次查询实现。在第一次查询的结果集中找出关联数据的id,根据这些id发起第二次请求得到关联数据。
c)跨节点的count,order by,group by以及聚合函数问题 :
这些是一类问题,因为它们都需要基于全部数据集合进行计算 ,解决这个问题,与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。
d)一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制 ,一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由,因此不能像单个数据库节点那样通过ID主键自增的方式生成了。
分库分表后主键的生成策略:
d.1)UUID :使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外,最主要的问题是在索引上,在建立索引和基于索引进行查询时都存在性能问题。
d.2)结合数据库维护一个Sequence表 ,此方案的思路也很简单,在数据库中建立一个Sequence表,表的结构类如下:
CREATE TABLE `SEQUENCE` (
`tablename` varchar(30) NOT NULL,
`nextid` bigint(20) NOT NULL,
PRIMARY KEY (`tablename`)
) ENGINE=InnoDB
每当需要为某个表的新纪录生成ID时就从Sequence表中取出对应表的nextid,并将nextid的值加1后更新到数据库中以备 下次使用,此方案也较简单,但缺点同样明显:由于所有插入任何都需要访问该表,该表很容易成为系统性能瓶颈,同 时它也存在单点问题,一旦该表数据库失效,整个应用程序将无法工作 .
d.3)flickr的方案:它与一般Sequence表方案有些类似,但却很好地解决了性能瓶颈和单点问题,是一种非常可靠而高 效的全局主键生成方案。flickr这一方案的整体思想是 :建立两台以上的数据库ID生成服务器,每个服务器都有一张 记录各表当前ID的Sequence表,但是Sequence中ID增长的步长是服务器的数量,起始值依次错开 ,这样相当于把 ID的生成散列到了每个服务器节点上。
例如:如果我们设置两台数据库ID生成服务器,那么就让一台的Sequence表的ID起始值为1,每次增长步长为2,另一 台的Sequence表的ID起始值为2,每次增长步长也为2,那么结果就是奇数的ID都将从第一台服务器上生成,偶数的 ID都从第二台服务器上生成,这样就将生成ID的压力均匀分散到两台服务器上,同时配合应用程序的控制,当一个 服务器失效后,系统能自动切换到另一个服务器上获取ID,从而保证了系统的容错。
本文大体介绍了Sharding JDBC分库分表的相关原理,以及分库分表后的一些问题的及对应的问题,具体可以参考博文:https://blog.csdn.net/bluishglc/article/details/6161475
https://blog.csdn.net/bluishglc/article/details/7710738(flickr的方案生成ID)