版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wx1528159409
目录
一、Kafka是什么
kafka是一个分布式的消息队列,类似于Flume中的Channel,用于数据的缓存;
存储数据框架,减缓大量流式数据存储的压力
发送消息者称为Producer,消息接受者称为Consumer,Consumer接收数据称为对消息的消费。
在Hadoop的分层体系中,kafka横跨传输层和存储层,它既可以传输数据,又可以存储数据。
二、Kafka的详细架构图
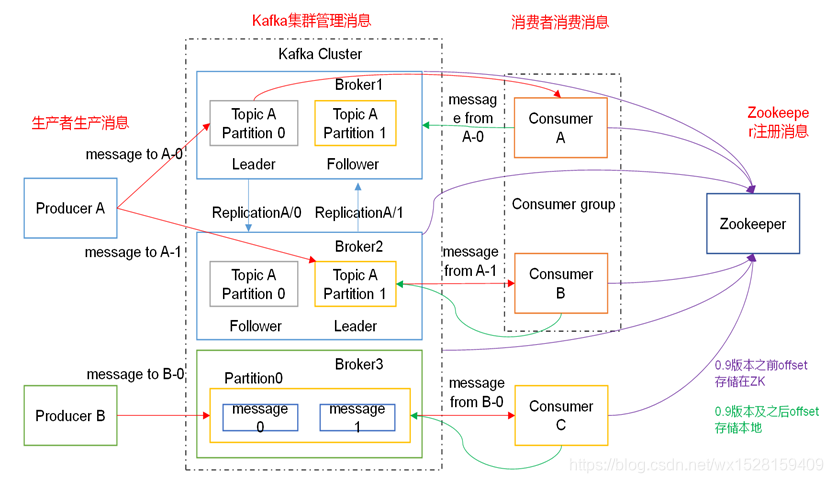
Broker:一个kafka节点(一台物理机)就是一个broker,一个或多个broker组成一个kafka集群;
Topic:逻辑概念,kafka根据Topic主题对消息进行分类,发布到kafka集群的每条消息都需要指定一个Topic;
Partition:物理概念,一个Topic可以分成多个Partition,且可分别存在于多个不同broker中,一个Partition就是一个有序的消息队列,对应一个物理的文件夹;
kafka会往Zookeeper中发送topics、partitions等元数据;consumer会往Zookeeper或本地(0.9版本以后)存储offset;
一个Broker可以有多个Topic,一个Topic分为多个Partition,同一Topic下不同的Partition存储在不同的Broker中,消息数据依据Topic进行归类后,存储在Partition中。
eg:Broker、Topic和Partition分别用B、T、P表示,
B1:存储TA-P0、TB-P0、TC-P0
B2:存储TA-P1、TB-P1、TC-P1
B3:存储TA-P2、TB-P2、TC-P2
然后在B1、B2和B3中又分别备份TA~TB - P0~P2的备份,分别从中选举出一个Leader,其余为Follower。
0. Kafka的存储结构和原理
存储位置:
(1)Producer生产的数据,
brokerId、topics、partitions这些元数据信息存储在Zookeeper节点中;
生产出来的数据,按照broker的topic分类,存放在partition中;
而partition分区的数据,分为index和数据本身,两者物理存放在logs目录下,不同的topic-数字文件夹中;
(2)Consumer消费的数据:0.9版本以后,存储在本地/opt/module/kafka/logs目录下
offset偏移量,存放在logs目录下,__consumer_offsets主题的分区文件夹中(默认50个分区)
offset是一个long类型的整数。
ps:在0.9版本以前kafka的offset存储在Zookeeper上,0.9版本之后存在本地,避免了消费者频繁与Zookeeper进行交互,提高效率,消费者直接与本地的logs文件夹数据交互,速度得到提高。
原理:
(1)Producer生产的数据,元数据存放在Zookeeper中,数据存放在本地logs文件夹下,
Consumer就从kafka/logs目录下,按照topic和partition去相应的topic-数字(分区)文件夹下读取数据,然后输出。
ps:任意Partition在某一个时刻只能被一个Consumer Group内的一个Consumer消费(反过来一个Consumer则可以同时消费多个Partition)。
(2)Conusmer读取的数据,可以输出到kafka封装的控制台中,也可以输出到Spark、Flume、HBase中。
(3)之所以有offset这个设定,因为Kafka处理的是流式数据,
一个状态点产生的实时数据,被消费后,会在分区中产生一个offset标记当前消费位置;
下一个状态点,又生成一个新的消息,consumer会从当前offset往后继续消费新消息,消费完后再产生一个新的offset,
避免重复消费之前已经消费完的数据。
(4)消费完毕的数据,整体无序,分区内有序。
流程示意:
由于是流式数据,消费完当前实时数据产生一个offset标记
offset存放在本地logs目录下
Producer生产流式数据 - > kafka的broker中 - > Consumer从logs目录下读取数据 - > 输出数据 - > Spark 、 Flume 、HBase
按照Topic归类并分区,分区中存放数据,
分区物理存放在logs目录下
1. ProducerA
(1)ProducerA生产出消息后,根据Topic进行分类,存储在Broker1的TopicA中;
(2)此时若Topic消息太多,以至于Broker1内存不够装不下,这样kafka存储能力受到Broker1存储能力的限制,为了解决这个问题,把同一Topic分为多个存储数据的Partition(分区),
(3)这样,同一个Topic、不同Partation分布到多个Broker中,实现同一个Topic数据的分布式存储;
(4)为了数据安全,对Broker1中的TopicA-Partition0在Broker2中进行备份,防止Broker1挂掉后存储在Partition0中的数据丢失;
(5)同理,TopicA-Partition1存储在Broker2中,在Broker1中完成备份;
(6)kafka会在多份Partition0和1的副本中选举出一个Leader,进行读写数据操作;其余的是Follower,仅用于备份(这里Leader和Follower的选举是依托Zookeeper的选举机制实现的);
(7)最后,ConsumerA和ConsumerB逻辑组成一个Consumer group,去消费同一个主题TopicA的数据,
ConsumerA去消费TopicA-Partition0的数据,
ConsumerB去消费TopicA-Partition1的数据,
这样消费同一主题不同分区的数据,就实现了并发,一个Consumer group可以看作一个大的Consumer,大大提高消费效率
ps:同一个Consumer group中不同Consumer不能消费同一个Partition的数据,这样会造成数据的重复消费,不合理。
ps:同一个Consumer group的不同Consumer消费不同分区的数据,是并发的,
单个Consumer消费不同分区,是消费完一个分区的数据后,再消费下一个分区的数据。
2. ProducerB
ProducerB生产出消息后,全部放入Broker3的一个消息队列Partition0中,只有一个ConsumerC去获取。
3. kafka分区的优势
对比ProducerA和ProducerB的生产—消费模式,可以看出kafka中对Topic进行分区的优势:
(1)扩展kafka存储消息的能力,避免一个主题的消息全部堆在同一台物理机上;
(2)同一个Consumer group中的不同Consumer能按照分区,去消费同一个Topic下不同Partition的消息,获取数据效率更高,提高消费能力。
三、kafka依赖于Zookeeper,体现在三个方面
(1)Broker依赖于Zookeeper,每个Broker的id和Topic、Partition这些元数据信息都会写入Zookeeper的ZNode节点中;
(2)Consumer依赖于Zookeeper,Consumer在消费消息时,每消费完一条消息,会将产生的offset保存到Zookeeper中,下次消费在当前offset往后继续消费;
ps:kafka0.9之前Consumer的offset存储在Zookeeper中,kafka0,9以后offset存储在本地。
(3)Partition依赖于Zookeeper,Partition完成Replication备份后,选举出一个Leader,这个是依托于Zookeeper的选举机制实现的;
所以,在启动kafka之前,需要先启动Zookeeper。