简介
the Crystal loss gains a significant improvement in the performance. It achieves new state-of-the-art results on IJB-A, IJB-B, IJB-C and LFW datasets, and competitive results on YouTube Face datasets. It surpasses the performance of several state-of-the-art systems, which use multiple networks or multiple loss functions or both. Moreover, the gains from Crystal Loss are complementary to metric learning (eg: TPE [42], joint-Bayes [7]) or auxiliary loss functions (eg: center loss [50], contrastive loss [44]). We show that applying these techniques on top of the Crystal Loss can further improve the verification performance.
Moreover, the center loss can also be used in conjunction with Crystal Loss, which performs better than center loss trained with regular softmax loss
Crystal loss 取得了很好的效果,对比当前使用 的softmax loss, 结合center loss 能够取得更好的提升
Crystal loss 只引入了一个参数 系数 a.
公式介绍
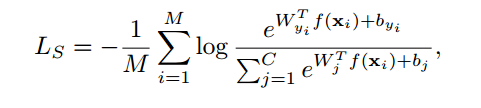

f(xi) 就是把 xi 归一化到一个半径为 a 的超球面上。

Crystal loss的好处
首先,在超球面上,软最大损失的最小化等价于正对余弦相似度的最大化和负对余弦相似度的最小化,增强了特征的验证信号。其次,由于所有的人脸特征都具有相同的l2范数,softmax损失能够更好地模拟极端和困难的人脸。
优点对比
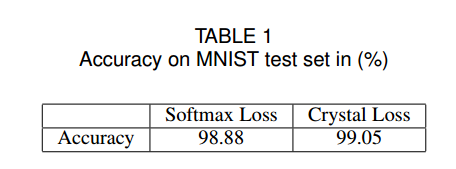
在mnist 数据集上面的测试结果

1.Crystal Loss 更细,所以整个类内角度更小,即类内间距更小
2.Crystal Loss 的模长 更小,因为归一化的原因。不那么像softmax 特征模长越长,置信度越高。这样有利于不清晰图片或者非正面人脸的训练。
训练人脸识别结果对比

实现
用caffe实现较简单:
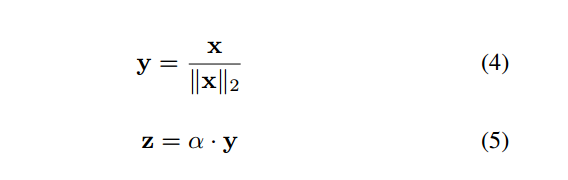
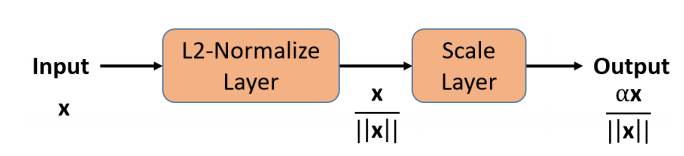
就是先使用 normalize 然后再用 scale 就能完成 归一化到特定超球面

系数a的设置问题
The scaling parameter α plays a crucial role in deciding the performance of L2-softmax loss. There are two ways to enforce the L2-constraint: 1) by keeping α fixed throughout the training, and 2) by letting the network to learn the parameter α. The second way is elegant and always improves over the regular softmax loss. But, the α parameter learned by the network is high which results in a relaxed L2-constraint. The softmax classifier aimed at increasing the feature norm for minimizing the overall loss, increases the α parameter instead, allowing it more freedom to fit to the easy samples. Hence, the α learned by the network forms an upper bound for the parameter. Improved performance is obtained by fixing α to a lower constant value.
1.固定为常量
2.使用在线学习的方式学习
在线学习的方式可能会存在问题导致系数变大,导致稀疏,所以可以给该系数设置各上界,来提高性能。
On the other hand, with a very low value of α, the training algorithm does not converge. For instance, α = 1 performs poorly on the LFW [20] dataset, achieving an accuracy of 86.37% (see Figure 11). The reason being that a hypersphere with small radius (α) has limited surface area for embedding features from the same class together and those from different classes far from each other
系数如果设置太小,模型会不容易收敛,因为超球面表面积减少
如果选择ca参数的大小

上图横坐标是 系数的大小, 纵坐标是 预测得分, C 是类别,所以 如果 我们希望 预测得分 大于 0.9时,我们应该让系数 大于a_low的最小值
人脸识别的结果对比

From the figure, the performance of Crystal loss is better for α >12 which is close to its lower bound computed using equation 9 for C = 13403 with a probability score of 0.9.
从图中可以看出 α >12 时,Crystal Loss 效果较好,该值也满足上面的α_low公式

可以看出 FAR =0.0001时,Crystal Loss 有明显的性能提升。
在大数据集有相同的表现,相应 α的值应该也会略有增大

使用 center loss 结合

近来不同的Loss 结果对比
The scaling parameter was kept fixed with a value of α = 50. Experimental results on different datasets show that Crystal loss works efficiently with deeper models.

根据图像的清晰度来优化人脸识别方案

quality pooling 是根据 人脸的质量来控制权重,例如在一系列清晰度不一样的同一个人脸图片中特征的取值计算方法。(这也是与直接取均值的区别)
quality attenuation 是根据 人脸的质量 来 动态调整 相似度得分,质量高的相似度得分可信,质量低的图像相似度得分不可信,所以大小进行了 gama缩放。
