1.1算法简介
决策树一种经典的机器学习分类算法,主要的代表算法有ID3、C4.5、CARD,原理可以简单理解为通过对数据总结、归纳得到一系列分类规则,举个简单的例子:
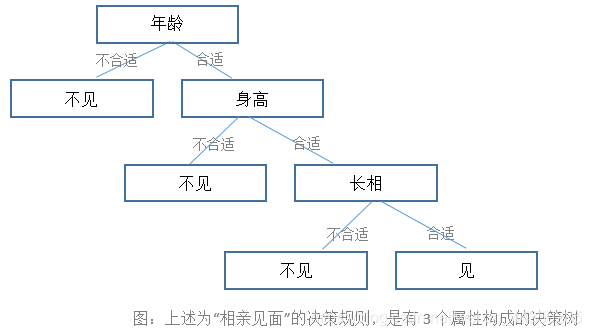
在决策树中,一个叶子节点表示一条决策规则(通常叶子节点的类目等于该节点样本最多的类目),决策树算法的目标是得到准确率高的规则,而决策规则的准确率可以用叶子节点的复杂度来衡量。
1.2复杂度计算
下面列举2种常用复杂度的计算方法, 假设有样本集X,总共的类目有n个,pi表示第i个类目的占比。
(1) 信息熵:
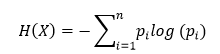
上式中,信息熵的值越高,复杂度越高,样本 的不确定性越大。
(2)基尼指数:
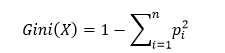
上式中,基尼指数越大,复杂度越高,样本的不确定性也就越大。
1.3裂分指标
在决策树的生成过程中,每一个节点的裂分都需要考虑选择哪个属性裂分使得系统的复杂度降低越多。不同算法选用的裂分方法有所不同。
(1)ID3:信息增益

其中H(x)表示裂分前系统的复杂度,表示裂分后系统的复杂度。该值越大表示裂分方式使得系统更为有序。
(2)C4.5:信息增益率
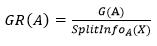
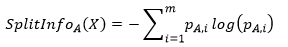
表示A属性的第i个取值占比,其中表示的意思是属性A的复杂度,该公式除了考虑系统纯度的增量的同时,也考虑了属性A的复杂度。该值越大表示裂分方式使得系统更为有序。(在ID3算法中,由于选择的是信息增益计算系统纯度增量,往往会选择复杂度高的属性进行裂分,复杂度高的属性取值分段会有很多,导致裂分后某些节点只有少量样本而不具备用于预测的统计意义,C4.5基于这个问题加以改进)。
(3)CARD:基尼系数
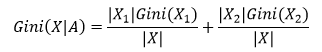
CARD算法生成的决策树是一个二叉树,每次裂分只裂分两个节点,Gini(X|A)表示裂分后的复杂度,该值越高样本无序性越大,X1,X2是X的裂分后的两个样本集(裂分方法为遍历所有裂分可能,找出Gini(X|A)最小的那个点)。该值越小表示裂分方式使得系统更为有序。

1.4决策树生成
输入: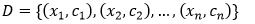
裂分指标:选择一种裂分指标(信息增益、信息增益率、Gini系数)。
节点裂分终止条件:选择节点最小样本数及最大深度。
Step1:选择一个可裂分的节点Di,循环计算所有属性的裂分指标,选取最优的指标使得系统最为有序那个属性作为裂分点,得到数据集Di+1,Di+2,…
Step2:所有叶子节点是否都达到了裂分的终止条件,是则执行
Step3,否则执行step1。
Step3:减枝
Step4:返回决策树T
1.5业务实践
业务场景:以应用商店中应用个性化推荐为例。
Step1:构造用户画像,收集用户历史下载应用记录、已安装应用记录、用户社会属性(年龄、性别、学历、所在城市)。
Step2:构造应用画像,应用画像包括应用ID,应用类型、应用标签、应用安装量排名、应用CTR等。
Step3:样本收集,收集用户历史曝光下载应用记录(字段:用户ID、应用ID、是否下载),并通关用户ID、应用ID与用户画像、应用画像关联起来得到样本数据,得到样本数据(用户ID,应用ID,用户画像,应用画像,是否下载)。
Step4:构造模型训练样本,定义用户画像与应用画像不同类型特征的交叉规则生成模型特征,运用定义好的交叉规则对所有样本生成模型特征,得到模型训练样本(模型特征,是否下载)。
Step5:模型训练,模型训练样本训练CARD算法,得到预测模型。
Step6:模型使用,给定一个用户和应用,根据上述方法生成用户的用户画像及应用的应用画像,然后运用定义好的交叉特征规则生成模型特征,把模型特征代入模型得到预测值。
1.6 实例代码