虽然docker、kubernetes的命令集并非十分复杂,后台操作也比较快捷,但是对于大多数徘徊在容器化门口的企业和个人用户来说,仍旧是一块心病,docker or not docker, that's a question,SWR服务通过提供界面化的操作,屏蔽原生命令行,简化用户操作和技术门槛,为企业和个人用户提供极简的容器化交付平台,我们接下来会通过一系列的文章,向大家介绍SWR的这些功能特性。
今天要为大家介绍的是用户0命令行,通过WEB界面实现镜像的上传及实现原理剖析。
我们从这个最为常用并极为简单的docker push功能开始讲,为什么呢?由于我们在与客户交流过程中发现,大多数都未接触过容器化管理系统,甚至镜像,对后端操作不熟悉的他们,对页面操作是有一定需求的。目前主流的PaaS平台基本都支持通过页面操作构建镜像、创建集群、创建应用等等,它们都在不断地封装底层集群管理系统(如kubernetes)的接口,设计一款对于云下用户友好的前端页面,让尽可能多的后端复杂操作可以通过鼠标的几次点击完成。
我们可以将这个趋势解释为,用户的业务云化的成本(包括金钱成本和时间成本)越低,上云的倾向也就越大。如今,我们支持用户在页面上完成构建、部署等操作,如果可以实现镜像上传下载都在页面上完成,用户就可以在尝试云化的早期尽可能避开后端操作,将尽可能多的时间成本花在业务调试上,普通运维人员不需要熟悉docker命令,也可以从内网或者第三方镜像仓库下载镜像,上传并完成升级操作。
接下来,我们从镜像上传逻辑和镜像结构开始讲起,阐述如何去实现页面上传镜像的功能。
后端上传镜像流程分析
我们的目的是实现另一种镜像上传方式,首先要了解原生的镜像上传流程是怎样的。
上传镜像层
docker push时,最先被上传的是镜像层文件。如下面的busybox,每一行的short ID都表示着一个镜像层的sha256值,它有两个镜像层:

上传元数据文件
由于层之间有顺序依赖关系,我们可以想到,上传的层文件是不足以完备地描述整个镜像的。除了镜像层文件外,docker push的时候还额外会上传一个镜像的元数据文件。该文件主要保存了镜像的环境变量、层结构、构建信息等等,并且它的sha256值就是镜像的ID。由于字段太多,在此不详细列出各字段的含义,感兴趣的朋友可以使用docker inspect命令查看,参阅docker官方文档了解一下。
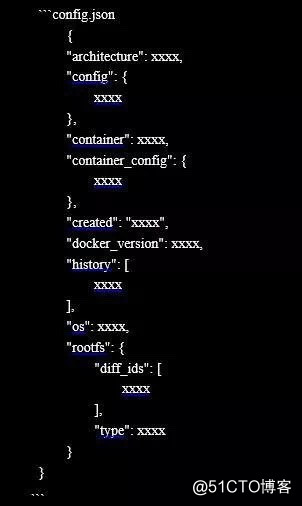
上传manifest
你们是否注意到,每个镜像在上传结束之后,屏幕上都会多一行xxx: digest: xxx size: xxx,最后一行信息的打印,标识着镜像最后一部分数据上传完成,这部分数据就是manifest,而digest后面的长ID,就是manifest的sha256值。
manifest主要是负责关联镜像的元数据文件和镜像层。在所有层都上传结束后,它才被传到仓库端的,用于校验是否所有实体文件都上传完成。通过抓包或者查阅官方文档,我们可以得知,manifest的结构是这样的:

由上述分析可知,要完备地描述一个镜像,需要存储如下数据:
镜像层
元数据文件
Manifest
我们接下来分析一下,从docker save生成的镜像包里,我们是否能获取到这些数据。
镜像压缩包结构分析
通过docker save保存镜像压缩包,解压开之后,可以发现,它的文件结构是比较有序的。
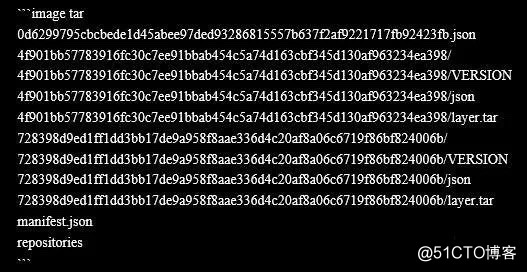
根目录下有这三个文件:

此外,包内还有多个以长ID命名的目录,每个目录下均有如下三个文件:

这里,有两个较为普遍的误区需要澄清一下:
误区一:manifest.json就是manifest
manifest里描述的是元数据文件名称,以及各个层的sha256值,此外,还有它们的大小。
而manifest.json里存放的不是完整的manifest信息,它仅仅记录了元数据文件的全路径名称,以及各个镜像层的全路径名称,没有记录各个层的sha256值和大小。
误区二:各个层所在的目录名就是镜像层的sha256值
其实目录名是用各个层的链ID(chain ID)和关联父层的链ID联合计算出来的一个特殊sha256值。这个特殊的sha256值,我们可以称之为v1 ID,它被设计于兼容较早版本(1.10之前)的docker镜像,早期版本,一个镜像中可能存在多个sha256值相同的层(如空层)。
顺带提一下,上面的链ID是docker daemon使用递归的方式将每一层与依赖的所有父层联合算出sha256得到的,它可以有效解决层相同导致目录重名的问题,具体计算方式在此就不赘述了。
明白了这两点之后,我们可以发现,镜像压缩包里是可以获取到与docker push同样完备的镜像数据的。其中,镜像层和元数据文件可以通过解压直接获取,而manifest则需要我们通过补充manifest.json获得。接下来我们看一看华为云容器镜像服务是怎么实现这一过程的。
页面上传是怎么实现的
解压并校验
镜像压缩包传至后端时,先对压缩包里的文件类型校验(普通文件、软链接、目录),确认无误之后,解压至临时目录并进行大小校验(前端上传目前有大小限制)。
此外,有一类镜像需要被过滤:通过docker save image_id > image.tar命令生成的镜像包。这类镜像是没有有效的镜像仓库和版本号信息的,我们无法判断要将其归于哪个仓库下,因此,这样的镜像可以认为是不合法的。对于页面上传而言,合法的镜像压缩包里必须有镜像仓库和版本号信息(如使用docker save repository:tag > image.tar的方式生成的镜像)。
保存实体文件
接下来,通过临时目录下的manifest.json,找到对应的元数据文件xxxx.json和各个目录下的镜像层文件进行存储。保存之前,通过元数据文件xxxx.json中各个层的sha256值,对实际镜像文件进行校验,保存过程中,我们在manifest.json的基础上,补充各个镜像层和元数据文件的sha256值、大小等信息,得到manifest。
在这里有个需要注意的地方,层文件一般都是普通文件,但是个别情况下(如docker1.10之前的版本),层文件可能是软链接,指向同镜像压缩包里的的另一个层文件,如果要兼容老版本,需要识别出这一部分特殊文件,跳过实体文件的保存。
保存元数据
最后,将镜像层元数据列表和manifest元数据在同一事务里存进数据库,保证镜像元数据的存储是一个原子操作,则镜像所有数据保存完成。该镜像可以通过docker pull的方式正常下载。
这只是华为云容器镜像服务基于优化用户体验的目的而开发的特性之一,我们一直致力于降低云容器技术的槛和使用成本,推进软件行业容器化的进程,希望有兴趣的朋友可以来体验一下,并提供你们宝贵的意见。
除此之外,我们最近还新上线了容器持续交付的工具,可以将您的源码快速编译、构建成镜像,省去本地编写Dockerfile、镜像制作、发布和部署的繁琐过程,后面文章我们将详细为您介绍。