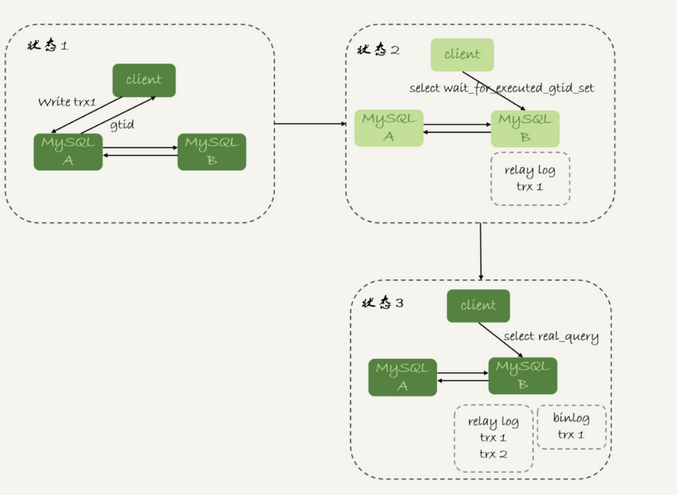
一:读写分离架构如下图,
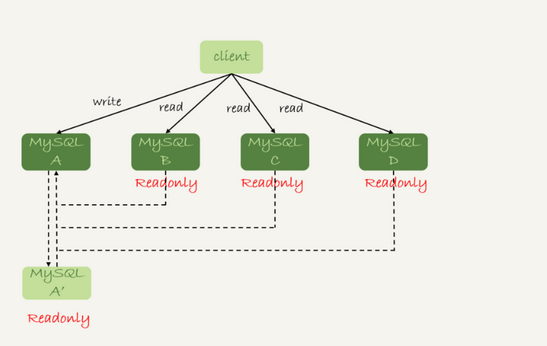
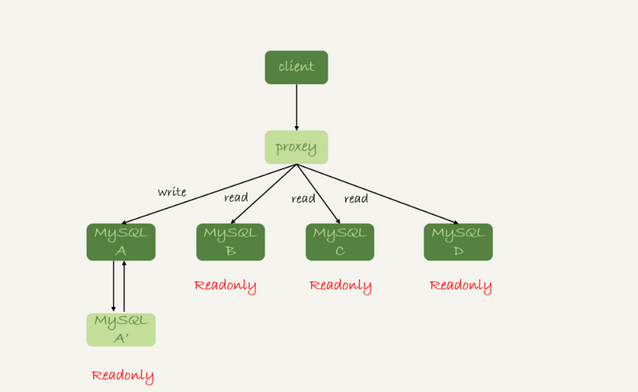
也可以加个proxy层
不论哪种架构,都会有主从延迟。客户端执行完一个更新事务后马上发起查询,如果查询选择的是从库的话,就可能读到刚刚的事务更新之前的状态
这种情况我们称为当前读。
方案包括:
强制走主库;
强一致性要求的走主库,不要求的走从库
sleep 方案;
等待一会
判断主备无延迟方案;、
有三种做法:
1:每次从库执行查询请求前,判断seconds_behind_master 是否等于0.。单位是秒,不够精确
show slave satus:
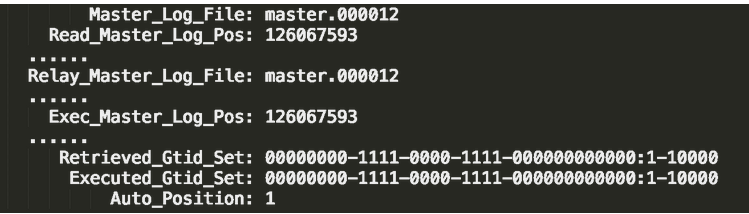
2:对比位点
3:对比gtid集合
虽然精确了但是还有问题:

配合semi-sync

但是还有俩个问题:
问题1:

问题2:
如果业务高峰期,主库位点或gitid集合更新很快,那么俩个位点等值判断一直不成立,很可能从库迟迟无法响应查询请求的情况。
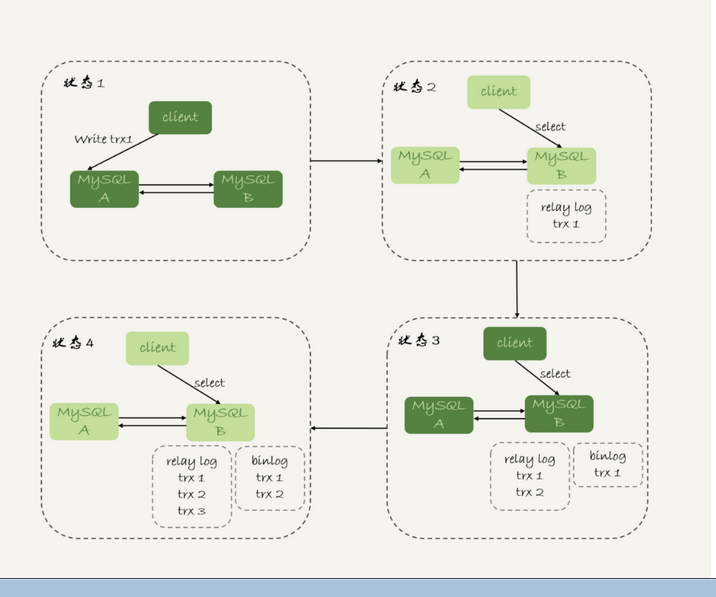
其实也不需要必须同步,在情况三就可以了。
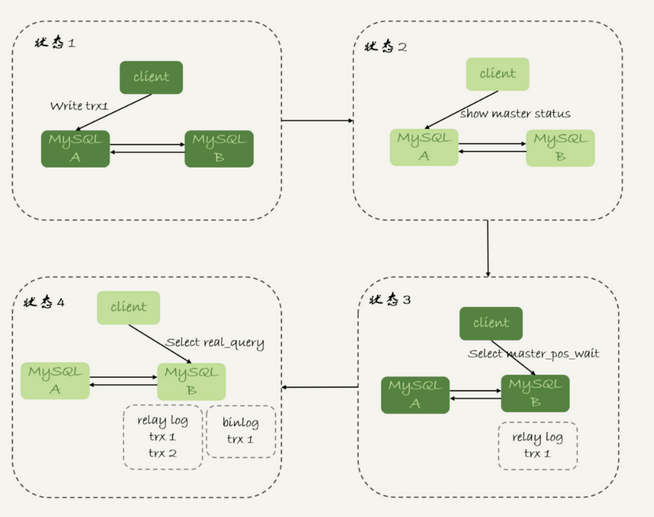
等主库位点方案;
select master_pos_wait(file, pos[, timeout]);
1.它是从库执行的;
2.参数file和pos指的是主库上的文件名和位置;
3.timeout 可选,设置为正整数n表示这个函数最多等待n秒。
它的执行逻辑:

等gtid方案;
select wait_for_executed_gtid_set(gtid_set, 1);
执行流程: