#######文本处理######
1)grep,egrep 的用法 建议使用egrep 都是以一行为单位的

正则表达式

grep '^r' /etc/passwd //显示/etc/passwd文件中,以r开头

grep '^root' /etc/passwd //显示/etc/passwd文件中,以root开头

egrep '^root|^daemon' /etc/passwd //显示/etc/passwd文件中,以root或者daemon开头

-q ##静默,无任何输出

egrep -m10 '/sbin/nologin' /etc/passwd //选取前十行

egrep -m1 '/sbin/nologin' /etc/passwd //统计含有/sbin/nologin的行数
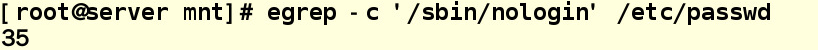
egrep -m10 'sbin$' wsp // 查看wsp中以sbin结尾的

基本元字符:' . ' ##过滤非空行

过滤空行:-v是取反的意思 ^$ 一开始就结束了,也是取反的意思


基本元字符: + ? * *就是所有的意思
+)

?)

egrep '(we){3}' 1.sh //连续的三个we
egrep '(we){2,4}' 1.sh // 2-4个we
egrep '(we){3,}' 1.sh // 至少三个we
egrep '(we)[ab]' 1.sh //wea或者web
egrep '[A-Z]' 1.sh // A-Z之间的大写字母

cut命令

练习1:获取主机ip 只要那一串数字,其他的都不要
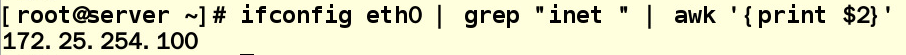

练习2:检测网络
1:编写脚本

4)sort命令:排序
sort
-n ##纯数字排序
-r ##倒序
-u ##去掉重复数字
-o ##输出到指定文件中
-t ##指定分隔符
-k ##指定要排序的列
[root@server ~]# sort westos //什么参数都不加时,默认第一列进行排序

[root@server ~]# sort -n westos // 纯数字排序

[root@server ~]# sort -u westos // 去掉重复数字

[root@server ~]# sort -t : -k 2 westos //-t指定分隔符 - k指定要排序的列

[root@server ~]# sort -nt : -k 2 westos //-t指定分隔符 - k指定要排序的列

5)uniq命令:对重复字符处理
uniq
-u ##显示唯一的行
-d ##显示重复的行

-c ##每行显示一次并统计重复次数

练习:将/tmp目录中的文件取出最大的
方法1:使用cut
ls命令,-S能进行排序

[kiosk@foundation0 ~]$ ls -Sl /tmp/ | head -2 | cut -d " " -f 9
方法2:使用awk
![]()