1.Java中HashMap的数据结构
answer:Java中数据存储方式最底层的两种结构,一种是数组,另一种就是链表。
数组的特点:连续空间,寻址迅速,但是在删除或者添加元素的时候需要有较大幅度的移动,所以查询速度快,增删较慢。
链表正好相反,由于空间不连续,寻址困难,增删元素只需修改指针,所以查询慢、增删快。
HashMap:有没有一种数据结构来综合一下数组和链表,以便发挥他们各自的优势?答案是肯定的!就是:哈希表。哈希表具有较快(常量级)的查询速度,及相对较快的增删速度,所以很适合在海量数据的环境中使用。一般实现哈希表的方法采用“拉链法”,我们可以理解为“链表的数组”。
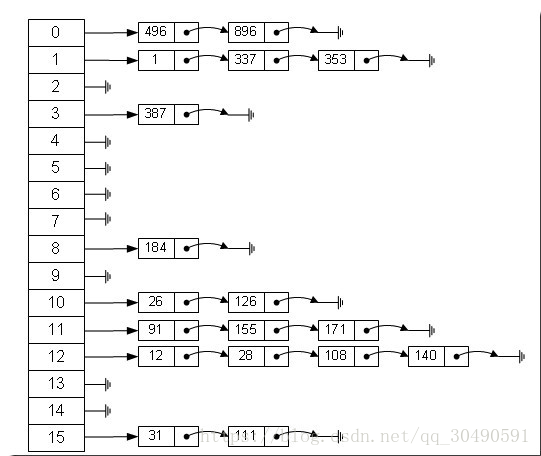
从上图中,我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。它的内部其实是用一个Entity数组来实现的,属性有key、value、next。接下来我会从初始化阶段详细的讲解HashMap的内部结构。
a、初始化
首先来看三个常量:
static final int DEFAULT_INITIAL_CAPACITY = 16; 初始容量:16
static final int MAXIMUM_CAPACITY = 1 << 30; 最大容量:2的30次方:1073741824
static final float DEFAULT_LOAD_FACTOR = 0.75f; 装载因子(下面有该参数的作用)
来看个无参构造方法,也是我们最常用的:
- public HashMap() {
- this.loadFactor = DEFAULT_LOAD_FACTOR;
- threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
- table = new Entry[DEFAULT_INITIAL_CAPACITY];
- init();
- }
2.Java中HashMap的put方法的底层实现
answer:HashMap初始化的时候我们可以这样理解:一个数组,每一个位置存储的是一个链表,链表里面的每一个元素才是我们记录的元素
底层源码:
- public V put(K key, V value) {
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key.hashCode());
- int i = indexFor(hash, table.length);
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- addEntry(hash, key, value, i);
- return null;
- }
描述:
a.当key为空的时候,通过putForNullKey方法,把元素放到最开始的位置。注意:HashMap是允许Key为空的。
b.当key不为空的时候,需要计算key的hashcode,因为hashCode()方法是继承Object,因此每一个key都有这样的方法。
注意:其中有一个hash()方法,就是把Key的hashCode再一次hash,这样做主要是为了使这个hash码更加的平均分布.
c.然后,通过indexFor方法计算,该元素大概放在大table的位置。
d.当计算完链表在table上面的位置,我们就需要遍历上面的元素,检查key是否存在,若存在就更新value值,若不存在就新增一条键值对,因此出现了for循环。
注意:table指的是初始化的那个数组,table的大小可变,当数据增加的一定程度时,会触发resize方法。(从新创建一个table,然后把就的数据copy一份到新的里面去)
一定程度:即参数装载因子(DEFAULT_LOAD_FACTOR=0.75)。装载因子是初始化的值,代表当Map的容量达到0.75的时候,将触发resize方法,重新扩展Map的大小。这个因子的数值决定了一大部分Map 的性能。
resize源码:
- void resize(int newCapacity) {
- Entry[] oldTable = table;
- int oldCapacity = oldTable.length;
- if (oldCapacity == MAXIMUM_CAPACITY) {
- threshold = Integer.MAX_VALUE;
- return;
- }
- Entry[] newTable = new Entry[newCapacity];
- transfer(newTable);
- table = newTable;
- threshold = (int)(newCapacity * loadFactor);
- }
综上所述,Map的put 的流程是:
(1)检查key是否为空,若为空,将元素放到最开始的位置。
(2)计算key的hashcode和在table里面的index(位置)。
(3)找到table上面的元素即该index所在的链表。
(4)遍历该链表,检查该key是否存在,如果没有就put进去,有就更新。
3.HashTable和ConcurrentHashMap的区别?
answer:它们都可以用于多线程的环境,但是当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。因为ConcurrentHashMap引入了分割(segmentation),不论它变得多么大,仅仅需要锁定map的某个部分,而其它的线程不需要等到迭代完成才能访问map。简而言之,在迭代的过程中,ConcurrentHashMap仅仅锁定map的某个部分,而Hashtable则会锁定整个map。