题目大概是有一串1-9组成的列表,数字代表优先级,数字越大优先级越高。从第一个数字开始判断,如果列表中没有优先级比它还高的数字,就执行它,如果后边有比它优先级还要高的数字,就把第一个数字放到列表尾端,依次往下判断,直至所有数据都被执行。然后题目要求输出这串列表中每个数字执行的顺序。
例如:
输入:
1,7,6,2,3,5,6,7,9
输出:
8,1,3,7,6,5,4,2,0
这个算法其实是先将原数据
做个标记,标记为

然后将数据对进行排序(降序,第一列为原数据,第二列为标记)

然后再对其进行一次顺序标记
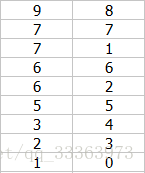
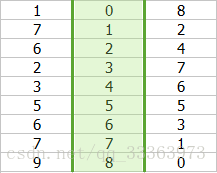
然后按照第二列(第一次的标记)进行排序
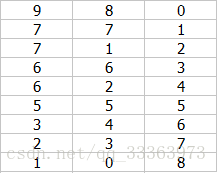
那么第三列就是我们要的结果了。
def test3(p):
a = [[p[i], i] for i in range(len(p))]
a.sort(reverse=True)
b = [a[i]+[i] for i in range(len(a))]
b = sorted(b, key=lambda x:x[1])
return [b[i][2] for i in range(len(b))]
这个算法其实并不完善,因为当原数据中有多个相同优先权的数值时,他们是按照出现的顺序执行的,而我的这个算法却正好会反过来。这个的解决办法其实也有很多,我就不一一列举了。
我在这里想再写一下我后来反思时的另一种算法。
代码如下:def test4(a):
res = [0 for i in range(len(a))]
b = sorted(a, reverse=True)
n = 0
for i in b:
if i in a:
j = a.index(i)
res[j] = n
n += 1
a[j] = -1
return res这个算法其实要比原先的算法好理解,而且也没有之前的相同值顺序反了的尴尬问题的出现。推荐第二种算法。