这里是MySQL一些常用操作的命令注释和摘要(数据库介绍和安装之类等真正写DB的时候在详细写(牵扯多种安装方式,主从同步,增量和全量备份、多实例等等)
其实现在使用原生的需求不多,基本上使用ORM操作,所以这里就不实战,这里我们把一些常用出走操作命令注释下,
系统平台:Linux
Mysql版本:5.5.32
基本了解
Field字段: 列名
type:
mysql数据库字符串类型是:char
Python 字符串类型是:str
mysql\python 数字类型:int
mysql:enum(‘N’,’Y’):值可以输入yes 或者no
Null: 是否允许该表示空
KEY 查看该字段的key是什么类型
PRI:主键或者复合键
MUT:普通索引
UNI:唯一索引
Default :填写一个默认值
Extra:额外的要求
SLQ结构化语言包含6个部分
DQL数据查询语言
select #查询最常用
DML数据操作语言
insert #插入
update #修改
delete #删除
#这3个命令都是针对表中的数据
TPL事务处理语言
begin
transaction
commit #提交到数据库里面(oracle默认每次操作修改数据库表都需要加这个命令才更新到数据库)(而mysql模式的开启的自动更新进入数据库,可关闭,关闭后每次执行修改,需要生效就必须加上该命令)
rollback
#接触不多 TPL是通过DML数据操作语言对表中影响的数据能够更新到数据库里面,或者让他失效
DCL数据控制语言
grant #授权
revoke #收回权限
DDL数据定义语言
greate #创建库和表
drop #删除库了表
#不同于DML数据操作语言,因为DML只针对表中的数据
CCL指针控制语言(一般用不到)
declare cursor
fetch into
update where current
小结:SQL语句最常见的分类一般就是3类:
DDL数据定义语言(CREATE,ALTER,DROP) 运维
DCL数据控制语言(GRANT,REVOKE,COMMIT,ROLLBACK) 运维
DML 数据操作语言(SELECT,INSERT,DELETE,UPDATE) 开发
一些常用的命令
[root@python ~]# cat /etc/my.cnf #mysql配置文件路径
[root@python ~]# mysql -uroot -p123 #登录数据库
mysql> use mysql; #切换数据库
mysql> show tables; #查看该数据库的表
mysql> desc user; #查看表结构
mysql> select * from user\G; #查看该表的所有数据
mysql> select User from user; #查看该表的用户
mysql> use test;
mysql> grant all on test.* to 'burgess'@'%' identified by 'burgess1314'; #授权:用户:burgess、访问主机:所有、密码:burgess 1314、只可管理test数据库的所有表,%号:本地主机不可以登录,所有其他主机可登录
mysql> select user,host from mysql.user; #查看用户和以及用户允许登录的主机名(主机IP)
mysql> show grants for burgess; #查看该用户权限
mysql> flush privileges; #从缓存把数据刷入磁盘
mysql> show columns from user; #desc一样的效果查看表结构
mysql> create database burgessdb; #创建数据库
mysql> show create database burgessdb; #查看建库语句,默认latinl (不可写中文)
mysql> drop database burgessdb; #删除数据库
mysql> create database burgessdb charset utf8; #创建数据库指定字符集
mysql> show create database burgessdb; #查看建库语句, (字符集是utf-8可写中文)
mysql> create table student( #创建一张student表
-> id int auto_increment,
-> name char(32) not null,
-> age int not null,
-> register_date date not null,
-> primary key (id));
mysql> desc student; #查看表结构
mysql> show create table student\G #查看建表语句,\G排序好看点
mysql> insert into student(name,age,register_date) values("burgess",3,"2016-06-22"); #插入语句进入表中 前面括号里面是字段每个字段以冒号分隔 ,后面values括号里面一一对应前面的字段进入插入到尾部
mysql> select * from student; #查看该表所有字段数据
mysql> select * from student limit 2 #limit 2显示2条数据(如有id1-id10十条数据,此时显示id1和id2两条数据)
mysql> select * from student limit 2 offset 1; #limit2:显示2条数据 offset1:从第1条数据后面开始显示(显示id2和id3两条数据)
mysql> select * from student limit 2,1; # 效果一样上面的简写(显示id2和id3两条数据)
mysql> select * from student where id >3 and age <20; #where 条件(满足字段的条件的数据显示)
mysql> select * from student where register_date like "2016-06%"; #like %: 模糊匹配 %:匹配任意
mysql> update student set name="Burgess",age=33 where id=4; #修改匹配的数据
mysql> delete from student where name="Burgess"; #删除匹配数据
mysql> select * from student order by id; #根据ID字段升序排列
mysql> select name,count(*) from student; #显示name字段,统计所有数据次数
mysql> select name,count(*) from student group by name; #显示name字段 ,统计name字段里相同值的次数(分组统计)
mysql> select register_date,count(*) from student group by register_date; #显示register_date字段 ,统计register_date字段相同的数据的次数(分组统计)
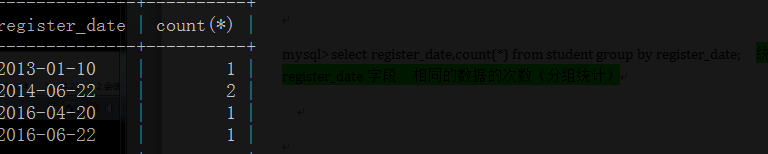
mysql> select register_date,count(*) as stu_num from student group by register_date;#count(*)名字修改成 stu_num名字(分组统计)

mysql> select name,count(*) from student group by name with rollup; #分组统计+总统计
mysql> select name,sum(age) from student; #显示name字段,计算age字段里总和
mysql> select name,sum(age) from student group by name;; #显示name字段,计算age字段里相同名字各自的age总和
mysql> select name,sum(age) from student group by name with rollup; #显示name字段,计算age字段里相同名字各自的总和,统计age所有总和
mysql> alter table student add sex enum("M","F"); #增加sex该字段,且该字段只能输入M 或 F 输入其他变空。
mysql> alter table student drop age; #删除age该字段
mysql> alter table student modify sex enum("M","F") not null; #修改sex该字段,字符串不可以为空
mysql> alter table student change sex gender char(32) not null default "X"; #修改sex字段名:gender,字符串类型: char(32), null:不为空 默认参数:X
在创建多一张考勤表关联
mysql> create table study_record(
-> id int(11) not null auto_increment,
-> day int not null,
-> status char(32) not null,
-> stu_id int(11) not null, #建立一个stu_id作为引用其他表的ID
-> primary key (id),
-> key fk_student_key (stu_id), #把该stu_id作为索引
-> constraint fk_student_key foreign key (stu_id) references student (id)
#强制一个索引外键stu_id 引用 student表的id
-> );
mysql> alter table study_record modify id int auto_increment; #修改增加该id字段状态自增
mysql> insert into study_record (day,status,stu_id) values(2,'no',5); #由于引入关联表没有该ID就报错 也就是student表没有ID5就会报错
Mysql (left join, right join, inner join ,full join)
我们已经学会了如果在一张表中读取数据,这是相对简单的,但是在真正的应用中经常需要从多个数据表中读取数据。
本章节我们将向大家介绍如何使用 MySQL 的 JOIN 在两个或多个表中查询数据。
你可以在SELECT, UPDATE 和 DELETE 语句中使用 Mysql 的 JOIN 来联合多表查询。
JOIN 按照功能大致分为如下三类:
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。 取交集
LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。取差集
RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。取差集
Full join: mysql 并不直接支持full join,but 总是难不到我们 取并集
创建两个表(Linux上mysql试验)
mysql> create table A (
-> a int not null);
mysql> create table B (
-> b int not null);
mysql> insert into A (a) values(1); #在A表的a字段插入数据
mysql> insert into A (a) values(2); #在A表的a字段插入数据
mysql> insert into A (a) values(3); #在A表的a字段插入数据
mysql> insert into A (a) values(4); #在A表的a字段插入数据
mysql> select * from A;

mysql> insert into B (b) values(3); #在B表的b字段插入数据
mysql> insert into B (b) values(4); #在B表的b字段插入数据
mysql> insert into B (b) values(5); #在B表的b字段插入数据
mysql> insert into B (b) values(6); #在B表的b字段插入数据
mysql> insert into B (b) values(7); #在B表的b字段插入数据
mysql> select * from B;

mysql> select * from A inner join B on A.a = B.b; #取A表的a字段和B表的b字段的交集(重复的数据)) inner join:内连接
mysql> select A.*,B.* from A,B where A.a=B.b; #和上面的效果一样的

mysql> select * from A left join B on A.a = B.b; #eft(显示A表a字段的数据,取B表b字段是否有相同的数据,有显示相同,没有显示null(先入为主)(求差集)
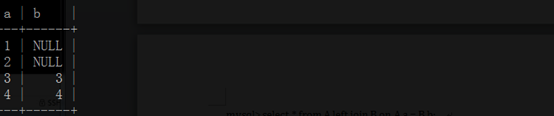
mysql> select * from B right join A on A.a = B.b; #right(显示A表a字段的数据,取B表b字段是否有相同的数据,有显示相同,没有显示null(后入为主) (求差集)

mysql> select * from B left join A on A.a = B.b; #left(显示B表b字段的数据,取A表a字段是否有相同的数据,有显示相同,没有显示null(先入为主) (求差集)

mysql> select * from A right join B on A.a = B.b; #right(显示B表b字段的数据,取A表a字段的数据,是否有相同的数据,有显示相同,没有显示null(后入为主) (求差集)

mysql> select * from A left join B on A.a = B.b union select * from A right join B on A.a = B.b; #通过这种方法实现查并集

事务
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
在MySQL中只有使用了Innodb数据库引擎的数据库或表才支持事务
事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要么全部不执行
事务用来管理insert,update,delete语句
一般来说,事务是必须满足4个条件(ACID): Atomicity(原子性)、Consistency(稳定性)、Isolation(隔离性)、Durability(可靠性)
1、事务的原子性:一组事务,要么成功;要么撤回。
2、稳定性 : 有非法数据(外键约束之类),事务撤回。
3、隔离性:事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
4、可靠性:软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得, innodb_flush_log_at_trx_commit选项 决定什么时候吧事务保存到日志里。
在Mysql控制台使用事务来操作
Linux上mysql试验事务
数据回滚
mysql> begin; #事务的开始
mysql> insert into student (name,register_date,gender) values("Burgess","2014-05-21","M"); #插入数据
mysql> insert into student (name,register_date,gender) values("Jack","2014-05-21","M"); #插入数据
mysql> rollback; #手动回滚 事务结束 (也就是上面两条数据是没有写入数据库的)
数据提交
mysql> begin; #事务开始
mysql> insert into student (name,register_date,gender) values("Alex","2014-05-21","M"); #插入数据
mysql> insert into student (name,register_date,gender) values("Jlex","2014-05-21","M"); #插入数据
mysql> insert into student (name,register_date,gender) values("Rain","2014-05-21","M"); #插入数据
mysql> commit; #事务提交(提交以后才数据才算是真正写入数据库)
索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。
Linux上mysql试验事务
mysql> show index from student\G; #查看该表的索引 主键就是一种默认索引

mysql> create index index_name on student(name); #该表name字段建立普通索引名:index_name
mysql> show index from student; #查看该表的索引

mysql> drop index index_name on student; #删除该表index_name索引
唯一索引的要求就是 该字段的数据不能重复..保证唯一 创建唯一索引和普通索引一样 格式:create unique index index_name on student(name);
索引的作用:
假如有id字段,name字段 你想通过name字段找指定的名字burgess
1.如果name 字段不是索引,那么找的顺序是从第一列开始往下查找(id列第一个值开始找,直到id列的所有值都找寻完毕,如果没有找到burgess名字,那么就开始从第二列name开始找,直到找到)
2.如果name设置了索引,那么找burgess的时候,直接从name字段开始找
还有很多如连表查询,联合索引等等,等到后期专门写MYSQL的时候在详细介绍(这里主要还是以Python开发需要了解为准)