文章分析下tensorflow提供的官方Android工程的源码分析,后续涉及更改代码,因此有必要对其做深入理解。
首先工程文件路径为:tensorflow-master\tensorflow\examples\android
由于这个android工程中实现了目标检测,风格迁移,语音,图像分类四个功能,其中目标检测中有用到yolo检测,有用到ssd-mobilenet v1检测,还有就是用到multi-box做检测。本文将针对yolo做检测需要用到的TensorFlowYoloDetector.java代码部分进行详细讲解。
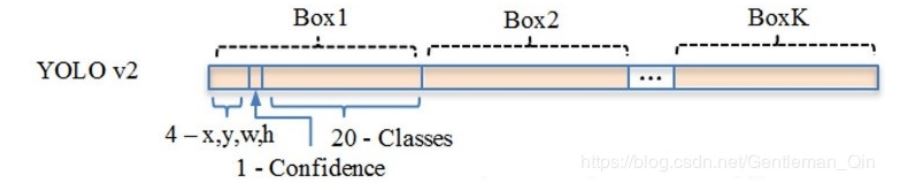
其中yolo v2在20类训练后得到的output上得到的结果按下图次序进行排列:
即【第一个框:x,y,w,h,confidence,class1,……,class20】【第二个框:x,y,w,h,confidence,class1,……,class20】……【第13x13x5个框:x,y,w,h,confidence,class1,……,class20】
TensorFlowYoloDetector.java部分代码如下:
/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
package org.tensorflow.demo; //包的名字,可随意更改
import android.content.res.AssetManager; //assets文件夹下的文件不会被映射到R.java中,访问的时候需要AssetManager类
import android.graphics.Bitmap; //导入安卓系统的图像处理类Bitmap ,以便进行图像剪切、旋转、缩放等操作,并可以指定格式保存图像文件
import android.graphics.RectF; //这个类包含一个矩形的四个单精度浮点坐标。矩形通过上下左右4个边的坐标来表示一个矩形
import android.os.Trace; // Android SDK中提供了`android.os.Trace#beginSection`和`android.os.Trace#endSection` 这两个接,我们可以在代码中插入这些代码来分析某个特定的过程:
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.PriorityQueue;
import org.tensorflow.contrib.android.TensorFlowInferenceInterface; //tf针对安卓封装的inference类
import org.tensorflow.demo.env.Logger; //定义的一个类用于报文生成便于分析
import org.tensorflow.demo.env.SplitTimer; //定义的一个类用于计算CPU时间
/** An object detector that uses TF and a YOLO model to detect objects. */
public class TensorFlowYoloDetector implements Classifier { //定义TensorFlowYoloDetector这个用TF版yolo的类,继承了Classifier
private static final Logger LOGGER = new Logger(); //实例化一个报文对象
// Only return this many results with at least this confidence.
private static final int MAX_RESULTS = 5; //根据概率刷选出的前5个结果
private static final int NUM_CLASSES = 80; //模型训练的类别数(根据实际更改,此处由于在coco上训练的80个类别)
private static final int NUM_BOXES_PER_BLOCK = 5; //yolo 2模型中采用锚点机制,因此每个特征图上的cell会预测5个锚点框
// TODO(andrewharp): allow loading anchors and classes
// from files.
private static final double[] ANCHORS = { //double型数组中存放5个锚点尺寸(是在数据集中聚类得到的)
1.08, 1.19,
3.42, 4.41,
6.63, 11.38,
9.42, 5.11,
16.62, 10.52
};
private static final String[] LABELS_VOC = { //字符串数组,用于标签索引,根据实际训练填写,此处为VOC的20类
"aeroplane",
"bicycle",
"bird",
"boat",
"bottle",
"bus",
"car",
"cat",
"chair",
"cow",
"diningtable",
"dog",
"horse",
"motorbike",
"person",
"pottedplant",
"sheep",
"sofa",
"train",
"tvmonitor"
};
private static final String[] LABELS = { //标签数组,此处为coco的80类
"person",
"bicycle",
"car",
"motorbike",
"aeroplane",
"bus",
"train",
"truck",
"boat",
"traffic light",
"fire hydrant",
"stop sign",
"parking meter",
"bench",
"bird",
"cat",
"dog",
"horse",
"sheep",
"cow",
"elephant",
"bear",
"zebra",
"giraffe",
"backpack",
"umbrella",
"handbag",
"tie",
"suitcase",
"frisbee",
"skis",
"snowboard",
"sports ball",
"kite",
"baseball bat",
"baseball glove",
"skateboard",
"surfboard",
"tennis racket",
"bottle",
"wine glass",
"cup",
"fork",
"knife",
"spoon",
"bowl",
"banana",
"apple",
"sandwich",
"orange",
"broccoli",
"carrot",
"hot dog",
"pizza",
"donut",
"cake",
"chair",
"sofa",
"pottedplant",
"bed",
"diningtable",
"toilet",
"tvmonitor",
"laptop",
"mouse",
"remote",
"keyboard",
"cell phone",
"microwave",
"oven",
"toaster",
"sink",
"refrigerator",
"book",
"clock",
"vase",
"scissors",
"teddy bear",
"hair drier",
"toothbrush"
};
// Config values.
private String inputName; //输入名
private int inputSize; //输入尺寸
// Pre-allocated buffers. //预先分配buffer
private int[] intValues; //整型数组(传入网络图像尺寸长x宽) 像素位置
private float[] floatValues; //浮点型数组 (传入网络图像尺寸长x宽x通道) 各通道像素值
private String[] outputNames; //输出名
private int blockSize; //网络缩放大小。yolo中为32
private boolean logStats = false; //log状态
private TensorFlowInferenceInterface inferenceInterface; //推理类 对象实例化
/** Initializes a native TensorFlow session for classifying images. */ //初始化一个本地TF会话用作图像分类
public static Classifier create(
final AssetManager assetManager, //资源管理类 对象实例
final String modelFilename, //模型名
final int inputSize, //输入尺寸
final String inputName, //输入名
final String outputName, //输出名
final int blockSize) { //特征图block大小
TensorFlowYoloDetector d = new TensorFlowYoloDetector(); //TF yolo检测类对象实例化
d.inputName = inputName;
d.inputSize = inputSize;
// Pre-allocate buffers.
d.outputNames = outputName.split(","); //对outputName字符串按‘,’分割后存入outputNames数组中
d.intValues = new int[inputSize * inputSize]; //输入尺寸x输入尺寸 (这里yolo2的话应该为416x416)
d.floatValues = new float[inputSize * inputSize * 3]; //输入尺寸x输入尺寸x3 (这里yolo2的话应该为416x416x3)
d.blockSize = blockSize; //网络缩放大小
d.inferenceInterface = new TensorFlowInferenceInterface(assetManager, modelFilename); //inference类实例化,并传入资源管理器类对象和模型文件名
return d; //返回一个TF Yolo检测器对象 ,并且开启以一个TF session,从assets中读取了模型文件
}
private TensorFlowYoloDetector() {}
private float expit(final float x) { //定义了一个sigmoid(x)函数
return (float) (1. / (1. + Math.exp(-x)));
}
private void softmax(final float[] vals) { //定义了一个softmax函数。传入一个float数组,返回做完sofamax后的数组
float max = Float.NEGATIVE_INFINITY; //初始化最大值为负无穷
for (final float val : vals) { //对vals数组中的值进行遍历,寻找最大值max
max = Math.max(max, val);
}
float sum = 0.0f;
for (int i = 0; i < vals.length; ++i) {
vals[i] = (float) Math.exp(vals[i] - max);
sum += vals[i];
}
for (int i = 0; i < vals.length; ++i) { //对数组中的值进行归一化
vals[i] = vals[i] / sum;
}
}
@Override //函数重写, recognizeImage在Classifier中没有具体函数操作内容,以下进行重写
public List<Recognition> recognizeImage(final Bitmap bitmap) { //返回的是一个list结果,list中的元素为Recognition格式
final SplitTimer timer = new SplitTimer("recognizeImage"); //识别图像计算器 实例化
// Log this method so that it can be analyzed with systrace. //报文分析用
Trace.beginSection("recognizeImage");
Trace.beginSection("preprocessBitmap"); //预处理图像过程开始
// Preprocess the image data from 0-255 int to normalized float based //以下是将输入图像数据进行预处理,将0-255值域归一化到浮点数0-1
// on the provided parameters.
bitmap.getPixels(intValues, 0, bitmap.getWidth(), 0, 0, bitmap.getWidth(), bitmap.getHeight()); //传入像素位置数组intValues,将bitmap彩色图像对应位置处的像素值赋值,那么intValues[i]中应是24bit的数
for (int i = 0; i < intValues.length; ++i) { //遍历图像所有像素位置点,读取像素值
floatValues[i * 3 + 0] = ((intValues[i] >> 16) & 0xFF) / 255.0f; //给图像浮点型数组一一赋归一化到0-1后的值
floatValues[i * 3 + 1] = ((intValues[i] >> 8) & 0xFF) / 255.0f;
floatValues[i * 3 + 2] = (intValues[i] & 0xFF) / 255.0f;
}
Trace.endSection(); // preprocessBitmap //预处理图像过程结束
// Copy the input data into TensorFlow. //将预处理后的图像数据传入网络,即feed
Trace.beginSection("feed"); //feed过程开启
inferenceInterface.feed(inputName, floatValues, 1, inputSize, inputSize, 3); //传入;输入网络的tensor名,float buffer(即上面预处理后浮点数组的图像),...longs参数表述输入tensor的尺寸[1,w,h,3],最后底层会将浮点数组中的值按tensor尺寸进行重新存放后送入网络
Trace.endSection(); //feed过程结束
timer.endSplit("ready for inference"); //开始做inference计时
// Run the inference call. //运行inference调用
Trace.beginSection("run"); //开始run
inferenceInterface.run(outputNames, logStats); // 需要指定网络输出tensor名数组(可以是多个输出名,用‘,’分隔)
Trace.endSection(); //run结束
timer.endSplit("ran inference"); //做inference计时结束
// Copy the output Tensor back into the output array. //将输出的tensor拷贝到输出数组中
Trace.beginSection("fetch");
final int gridWidth = bitmap.getWidth() / blockSize; // 网格宽度=输入网络图像宽 / 网络缩放大小 (yolo 2的是 416/32=13)
final int gridHeight = bitmap.getHeight() / blockSize; //网格高度=输入网络图像高/ 网络缩放大小 (yolo 2的是 416/32=13)
final float[] output = //定义输出结果的维度为output:[13x13x(80+5)x5] 根据实际训练进行更改
new float[gridWidth * gridHeight * (NUM_CLASSES + 5) * NUM_BOXES_PER_BLOCK];
inferenceInterface.fetch(outputNames[0], output); //将 outputNames[0]中的结果按照output的维度进行赋值填充
Trace.endSection();
// Find the best detections. //寻找最好的检测结果,将队列中的元素按照置信度大小从大到小排列
final PriorityQueue<Recognition> pq = //优先队列 对象实例化,队列中的元素为Recognition格式
new PriorityQueue<Recognition>(
1, //初始容器大小;
new Comparator<Recognition>() {
@Override
public int compare(final Recognition lhs, final Recognition rhs) {
// Intentionally reversed to put high confidence at the head of the queue. 将置信度高的放在队列最前面
return Float.compare(rhs.getConfidence(), lhs.getConfidence());
}
});
for (int y = 0; y < gridHeight; ++y) { //对特征图grid高进行遍历,yolo 2中为13 ,先行后列进行遍历13x13大小的特征图
for (int x = 0; x < gridWidth; ++x) { //对特征图grid宽进行遍历,yolo 2中为13
for (int b = 0; b < NUM_BOXES_PER_BLOCK; ++b) { //对特征图每个pixcel上的5个预测框进行遍历,寻找与GT IOU最大的预测框
final int offset = // 预测结果存放形式是: 第一个框先4个坐标,后1个置信度,第二个框……如此遍历13x13x5个框,每个框5个信息
(gridWidth * (NUM_BOXES_PER_BLOCK * (NUM_CLASSES + 5))) * y
+ (NUM_BOXES_PER_BLOCK * (NUM_CLASSES + 5)) * x
+ (NUM_CLASSES + 5) * b;
//说明下:output中推理得到的位置信息需要进行sigmoid后得到相对所在cell的偏移值(归一化到0-1), blockSize表示最后特征图一个点对应原图区域大小
final float xPos = (x + expit(output[offset + 0])) * blockSize; //预测框在原图实际中心横坐标xPos=(相对13x13的特征图左上角的横向偏移坐标)*32
final float yPos = (y + expit(output[offset + 1])) * blockSize; //预测框在原图实际中心纵坐标yPos=(相对13x13的特征图左上角的纵向偏移坐标)*32
final float w = (float) (Math.exp(output[offset + 2]) * ANCHORS[2 * b + 0]) * blockSize; //预测框在原图实际宽 w=(相对特征图pixcel宽* 预先聚类锚点宽比例)*32
final float h = (float) (Math.exp(output[offset + 3]) * ANCHORS[2 * b + 1]) * blockSize; //预测框在原图实际高 h=(相对特征图pixcel高* 预先聚类锚点高比例)*32
final RectF rect = //RectF 对象实例 rect(xmin,ymin,xmax,ymax)
new RectF(
Math.max(0, xPos - w / 2), //实际框xmin
Math.max(0, yPos - h / 2), //实际框ymin
Math.min(bitmap.getWidth() - 1, xPos + w / 2), //实际框xmax
Math.min(bitmap.getHeight() - 1, yPos + h / 2)); //实际框ymax
final float confidence = expit(output[offset + 4]); //置信度归一化后的值
int detectedClass = -1; //定义一个检测到的类ID
float maxClass = 0; //定义一个概率值最大类对应的概率
final float[] classes = new float[NUM_CLASSES]; //定义一个float类型的数组,长度是类别总数;
for (int c = 0; c < NUM_CLASSES; ++c) {
classes[c] = output[offset + 5 + c]; //将output中对应位置处的类别概率值赋给classes数组;
}
softmax(classes); //对NUM_CLASSES个分布概率进行softmax归一化;
for (int c = 0; c < NUM_CLASSES; ++c) { //寻找概率值最大的类ID detectedClass以及对应的概率值maxClass;
if (classes[c] > maxClass) {
detectedClass = c;
maxClass = classes[c];
}
}
final float confidenceInClass = maxClass * confidence; //属于某类别概率confidenceInClass=类别概率*存在目标的置信度;
if (confidenceInClass > 0.01) { //如果某类概率>0.01,则打印报文
LOGGER.i(
"%s (%d) %f %s", LABELS[detectedClass], detectedClass, confidenceInClass, rect);
pq.add(new Recognition("" + offset, LABELS[detectedClass], confidenceInClass, rect)); //将框对应的offset,框所属类别名,类别概率,框坐标 加入Recognition;
}
}
}
}
timer.endSplit("decoded results"); //将output的结果进行解码输出;
final ArrayList<Recognition> recognitions = new ArrayList<Recognition>(); //用于将识别解码的结果放入ArrayList;
for (int i = 0; i < Math.min(pq.size(), MAX_RESULTS); ++i) {
recognitions.add(pq.poll()); //将pq中的识别结果概率从大到小排列,选取最多5个结果保存
}
Trace.endSection(); // "recognizeImage"
timer.endSplit("processed results"); //结果处理结束;
return recognitions; //将概率结果值较大的识别框结果列表recognitions返回;
}
@Override
public void enableStatLogging(final boolean logStats) {
this.logStats = logStats;
}
@Override
public String getStatString() {
return inferenceInterface.getStatString();
}
@Override
public void close() {
inferenceInterface.close(); //关闭feed,fetch,session
}
}