定义
REST即表述性状态传递(英文:Representational State Transfer,简称REST)是Roy Fielding博士在2000年他的博士论文中提出来的一种软件架构风格(software architecture style)。它是一种针对网络应用的设计和开发方式,可以降低开发的复杂性,提高系统的可伸缩性。
REST密切相关的两个名词:资源和状态。可以说,资源是REST系统的核心概念。所有的设计都会以资源为中心,包括如何对资源进行添加,更新,查找以及修改等。而资源本身则拥有一系列状态。在每次对资源进行添加 ,删除或修改的时候,资源就将从一个状态转移到另外一个状态。
REST(多用Json)模式的Web服务与复杂的SOAP(多用XML)和XML-RPC对比来讲明显的更加简洁,越来越多的web服务开始采用REST风格设计和实现。例如:
- Amazon.com提供接近REST风格的Web服务进行图书查找;
- 雅虎提供的Web服务也是REST风格的。
表述性状态转移是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是RESTful。REST是设计风格而不是标准。REST通常基于使用HTTP,URI,和XML(标准通用标记语言下的一个子集)以及HTML(标准通用标记语言下的一个应用)这些现有的广泛流行的协议和标准。这些原则设计以系统资源为中心的 Web 服务,REST 近年来已经成为最主要的 Web 服务设计模式。 事实上,REST 对 Web 的影响非常大,由于其使用相当方便,已经普遍地取代了基于 SOAP 和 WSDL 的接口设计。
一、资源(Resources)
REST的名称"表现层状态转化"中,省略了主语。"表现层"其实指的是"资源"(Resources)的"表现层"。
所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实在。你可以用一个URI(统一资源定位符)指向它,每种资源对应一个特定的URI。要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或独一无二的识别符。
所谓"上网",就是与互联网上一系列的"资源"互动,调用它的URI。
二、表现层(Representation)
"资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)。
比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
URI只代表资源的实体,不代表它的形式。严格地说,有些网址最后的".html"后缀名是不必要的,因为这个后缀名表示格式,属于"表现层"范畴,而URI应该只代表"资源"的位置。它的具体表现形式,应该在HTTP请求的头信息中用Accept和Content-Type字段指定,这两个字段才是对"表现层"的描述。
三、状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。
互联网通信协议HTTP协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转化"(State Transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。
客户端用到的手段,只能是HTTP协议。具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
使用方法
关键在于如何抽象资源,抽象得越精确,对REST的应用就越好。如何抽象资源:
(1)动作的宾语作为资源;
(2)动作所影响的实体的状态变化(该实体就是资源);
(3)把动作抽象成一种资源。
约束
- 使用客户/服务器模型。客户和服务器之间通过一个统一的接口来互相通讯。
- 层次化的系统。在一个REST系统中,客户端并不会固定地与一个服务器打交道。
- 无状态。在一个REST系统中,服务端并不会保存有关客户的任何状态。也就是说,客户端自身负责用户状态的维持,并在每次发送请求时都需要提供足够的信息。
- 可缓存。REST系统需要能够恰当地缓存请求,以尽量减少服务端和客户端之间的信息传输,以提高性能。
- 统一的接口。一个REST系统需要使用一个统一的接口来完成子系统之间以及服务与用户之间的交互。这使得REST系统中的各个子系统可以独自完成演化。
其中1,2,4是先有的WEB服务都能满足的要求。第三条在很多移动端应用中也进行了设计。第五条则是最复杂的,最需要进行约束和规范。第五条又包含子约束:
- 每个资源都拥有一个资源标识。每个资源的资源标识可以用来唯一地标明该资源。URI的设计。
- 消息的自描述性。在REST系统中所传递的消息需要能够提供自身如何被处理的足够信息。例如该消息所使用的MIME类型,是否可以被缓存等。响应头和请求头。
- 资源的自描述性。一个REST系统所返回的资源需要能够描述自身,并提供足够的用于操作该资源的信息,如如何对资源进行添加,删除以及修改等操作。也就是说,一个典型的REST服务不需要额外的文档对如何操作资源进行说明。返回的JSON消息及响应头。
- HATEOAS。即客户只可以通过服务端所返回各结果中所包含的信息来得到下一步操作所需要的信息,如到底是向哪个URL发送请求等。也就是说,一个典型的REST服务不需要额外的文档标示通过哪些URL访问特定类型的资源,而是通过服务端返回的响应来标示到底能在该资源上执行什么样的操作。一个REST服务的客户端也不需要知道任何有关哪里有什么样的资源这种信息。Hypermedia API。
原则(1)URI
请求 API 的 URL 表示用来定位资源。
1、URL 用来定位资源,跟要进行的操作区分开,这就意味这 URL 不该有任何动词;
URL 中不应该出现任何表示操作的动词,链接只用于对应资源;
这样的弊端在于:首先加上了动词,肯定是使 URL 更长了;其次对一个资源实体进行不同的操作就是一个不同的 URL,造成 URL 过多难以管理。
URL 的意思是统一资源定位符,这个术语已经清晰的表明,一个 URL 应该用来定位资源,而不应该掺入对操作行为的描述。
如果某些动作是HTTP动词表示不了的,你就应该把动作做成一种资源。
2、URL 中应该单复数区分,推荐的实践是永远只用复数;
在stackoverflow上的一个常见观点是:如果一个URL所对应的资源是使用复数表示的,那么该类型的资源可能有多个。对该URL发送Get请求可能返回该资源的一个列表。反之,如果一个URL所对应的资源是使用单数表示的,那么该类型的资源将只有一个,因此对该URL发送Get请求将只返回该资源的一个实例。
比如 GET /api/users 表示获取用户的列表;如果获取单个资源,传入 ID,比如 /api/users/123 表示获取单个用户的信息;
3、相对路径与请求参数的选择
一个经常导致疑惑的地方就是针对资源的某一种特征,我们到底是将其定义为URL中相对路径的一部分还是作为请求参数。
在判断到底是使用请求参数还是相对路径时,我们一般分为下面几步。
首先,可选参数一般都应置于请求参数中。以购物中的手机为例。在选择手机时,用户可以选择品牌以及颜色。如果将品牌和颜色都定义在相对URL中,那么具有特定品牌和颜色的手机将可以通过两个不同的URL访问:/api/mobiles/brand/{brand}/color/{color}以及/api/mobiles/color/{color}/brand/{brand}。就用户而言,其并无法了解这两个URL所表示的是同一类资源还是不同类型的资源。当然,您可以说,我们只用/api/mobiles/brand/{brand}/color/{color}。但是该URL将无法处理用户仅仅选择了颜色,却没有选择品牌的情况。
其次,不是所有字符都可以在URL中被使用,如汉字,标点。为了处理这种情况,包含这些字符的筛选条件需要置于请求参数中。
最后,如果该特征下包含子资源,那么它自身也就是一个资源,因此需要以相对路径的方式展现它。例如在购物网站中,每件商品所属于的分类仅仅是它的一个特征。但是一个分类更包含了属于它的各个品牌以及热搜关键字等众多信息。因此它其实是一个资源,需要在URI路径中表示它。
总的来说,既然使用HTTP来构建REST系统,那么我们就需要遵守URL各组成中的含义:URL中的相对路径将用来标示“What I want”,也既对应着资源;而请求参数则用来标示“How I want”,即查看资源的方式。
4、按照资源的逻辑层级,对 URL 进行嵌套;
比如一个用户属于某个团队,而这个团队也是众多团队之一;那么获取这个用户的接口可能是这样:
GET /api/teams/123/members/234 表示获取 id 为 123 的小组下,id 为234 的成员信息5、不要在URI中加入版本号;
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URI。版本号可以在HTTP请求头信息的Accept字段中进行区分:
Accept: vnd.example-com.foo+json; version=1.0
Accept: vnd.example-com.foo+json; version=1.1
Accept: vnd.example-com.foo+json; version=2.0原则(2)METHOD
请求的 METHOD 表示对这个资源进行的操作。
在很多系统中,几乎只用 GET 和 POST 方法来完成了所有的接口操作;这个行为类似于全用 DIV 来布局。实际上,我们不只有GET 和 POST 可用,在 REST 架构中,有以下几个重要的请求方法:GET,POST,PUT,PATCH,DELETE。这几个方法都可以与对数据的 CRUD 操作对应起来(CRUD 是指在做计算处理时的增加(Create)、读取查询(Retrieve)、更新(Update)和删除(Delete)几个单词的首字母简写。即增删改查)。
1、【Read】,资源的读取,用 GET 请求;
GET /api/users ( 表示读取用户列表)The GET method means retrieve whatever information (in the form of an entity) is identified by the Request-URI.
GET 应当实现为一个安全方法。用于获取数据而不应该产生副作用。并且可以重复进行请求,不会产生不同的结果,具有幂等性。
2、【Created】,资源的创建,用 POST 方法;
The POST method is used to request that the origin server accept the entity enclosed in the request as a new subordinate of the resource identified by the Request-URI in the Request-Line
POST 是一个非幂等的方法,多次调用会造成不同效果;(幂等(Idempotent):如果对服务器资源的多次请求与一次请求造成的副作用是一样的的话,那这个请求方法可以被认为是幂等。)
比如下面的请求会在服务器上创建一个 name 属性为 ‘John Snow’ 的用户;多次请求就会创建多个这样的用户。
3、【Update】,资源的更新。用于更新的 HTTP 方法有两个,PUT 和 PATCH。
他们都应当被实现为幂等方法,即多次同样的更新请求应当对服务器产生同样的副作用。
PUT 和 PATCH 有各自不同的使用场景:
PUT 用于更新资源的全部信息,在请求的 body 中需要传入修改后的全部资源主体;
The PUT method requests that the enclosed entity be stored under the supplied Request-URI. If the Request-URI refers to an already existing resource, the enclosed entity SHOULD be considered as a modified version of the one residing on the origin server. If the Request-URI does not point to an existing resource, and that URI is capable of being defined as a new resource by the requesting user agent, the origin server can create the resource with that URI."
而 PATCH 用于局部更新,在 body 中只需要传入需要改动的资源字段。
早期的很多HttpClient不支持PATCH,只支持 GET POST PUT DELETE。
PATCH 的作用在于如果一个资源有很多字段,在进行局部更新时,只需要传入需要修改的字段即可。否则在用 PUT 的情况下,你不得不将整个资源模型全都发送回服务器,造成网络资源的极大浪费。
4、【Delete】,资源的删除,相应的请求 HTTP 方法就是 DELETE。
这个也应当被实现为一个幂等的方法。如:
DELETE /api/users/123The DELETE method requests that the origin server delete the resource identified by the Request-URI.
用于删除服务器上 ID 为 123 的资源,多次请求产生副作用都是,是服务器上 ID 为 123 的资源不存在。
还有两个不常用的HTTP动词:
- HEAD:获取资源的元数据。
- OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
原则(3)分页、过滤(接受参数)
REST 风格的接口地址,表示的可能是单个资源,也可能是资源的集合;当我们需要访问资源集合时,设计良好的接口应当接受参数,允许只返回满足某些特定条件的资源列表。
比如支持以 offset 和 limit 参数来进行分页;
GET /api/users?offset=0&limit=20支持提供关键词进行搜索,以及排序
GET /api/users?keyword=john&sort=age支持根据字段进行过滤:
GET /api/users?gender=male原则(4)状态码
服务器向用户返回的状态码和提示信息,常见的有以下一些(方括号中是该状态码对应的HTTP动词)。
- 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
- 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
- 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
- 204 NO CONTENT - [DELETE]:用户删除数据成功。
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
- 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
- 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
- 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
- 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
- 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
- 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
详细的RFC文档描述如下:
http://www.iana.org/assignments/http-status-codes/http-status-codes.xhtml
错误处理
如果状态码是4xx,就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
HTTP/1.1 400 Bad Request
Content-Type: application/json
Content-Length: xxx
{
"error_id" : "100045",
"header" : "Reset password failed",
"description" : "The original password is not correct"
}- 服务端响应的状态码。页面逻辑可以通过判断该状态码是否是4XX或5XX来判断是否请求出错,从而在页面中展示一个警告对话框。
- 服务所提供的内部错误ID。通常情况下,该内部错误ID也需要在警告对话框中展示出来。从而允许软件用户根据内部错误ID来获取支持服务。
- 错误的标题及简述。通过该错误的标题及简述,软件用户能够了解系统内部到底发生了什么,并在是用户输入错误的时候允许用户自行修改错误并重新发送正确的请求。
返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
- GET /collection:返回资源对象的列表(数组)
- GET /collection/resource:返回单个资源对象
- POST /collection:返回新生成的资源对象
- PUT /collection/resource:返回完整的资源对象
- PATCH /collection/resource:返回完整的资源对象
- DELETE /collection/resource:返回一个空文档
原则(5)Hypermedia API
RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。HATEOAS(Hypermedia As The Engine Of Application State)特性。
比如,当用户向api.example.com的根目录发出请求,会得到这样一个文档。
{"link": {
"rel": "collection https://www.example.com/zoos",
"href": "https://api.example.com/zoos",
"title": "List of zoos",
"type": "application/vnd.yourformat+json"
}}上面代码表示,文档中有一个link属性,用户读取这个属性就知道下一步该调用什么API了。rel表示这个API与当前网址的关系(collection关系,并给出该collection的网址),href表示API的路径,title表示API的标题,type表示返回类型。
Hypermedia API的设计被称为HATEOAS。Github的API就是这种设计,访问api.github.com会得到一个所有可用API的网址列表。
{
"current_user_url": "https://api.github.com/user",
"authorizations_url": "https://api.github.com/authorizations",
// ...
}从上面可以看到,如果想获取当前用户的信息,应该去访问api.github.com/user , 然后就得到了下面结果。
{
"message": "Requires authentication",
"documentation_url": "https://developer.github.com/v3"
}原则(6)无状态
We next add a constraint to the client-server interaction: communication must be stateless in nature … such that each request from client to server must contain all of the information necessary to understand the request, and cannot take advantage of any stored context on the server. Session state is therefore kept entirely on the client.
从上面的陈述中可以看到,在一个REST系统中,用户的状态(并不与传统的WEB服务相同,保存在服务器端)会随着请求在客户端和服务端之间来回传递。这也便是REST这个缩写中ST(State Transfer)的来历。
为REST系统添加这个约束有什么好处呢?主要还是基于集群扩展性的考虑。如果REST服务中记录了用户相关的状态,那么在集群中,这些用户相关的状态就需要及时地在集群中的各个服务器之间同步。对用户状态的同步将会是一个非常棘手的问题:当一个用户的相关状态在一个服务器上发生了更改,那么在什么时候,什么情况下对这些状态进行同步?如果该状态同步是同步进行的,那么同时刷新多个服务器上的用户状态将导致对用户请求的处理变得异常缓慢。如果该同步是异步的,那么用户在发送下一个请求时,其它服务器将可能由于用户状态不同步的原因无法正确地处理用户的请求。除此之外,如果集群进行了不停机的横向扩展,那么用户状态的同步需要如何完成?这些实际上都是非常难以处理的问题。
但是现有的很多较为流行的技术及规范实际上都没有限制用户的请求是无状态的。以搭建基于HTTP的REST服务为例。在HTTP中,一个重要的功能就是Cookie和Session的使用(RFC6265)。该功能会在服务器里保留一个状态。因此在一个基于HTTP的REST系统中,我们常常需要避免使用这些在服务器里面保留状态的技术。但是某些技术,如用户的登陆,实际上常常需要在服务器中添加一个状态。
有专门的认证协议OAuth 2.0来解决该问题,也有自定义的token方案来解决。
原则(7)Authentication
无状态约束给REST实现带来的麻烦:用户的状态是需要全部保存在客户端的。当用户需要执行某个操作的时候,其需要将所有的执行该请求所需要的信息(包括身份和权限认证信息)添加到请求中。该请求将可能被REST服务集群中的任意服务器处理,而不需要担心该服务器中是否存有用户相关的状态。
但是在现有的各种基于HTTP的Web服务中,我们常常使用会话来管理用户状态,至少是用户的登陆状态。因此,REST系统的无状态约束实际上并不是一个对传统用户登录功能友好的约束:在传统登陆过程中,其本身就是通过用户所提供的用户名和密码等在服务端创建一个用户的登陆状态,而REST的无状态约束为了横向扩展性却不想要这种状态。而这也就是为基于HTTP的REST服务添加身份验证功能的困难之处。
为了解决该问题,最为经典也最符合REST规范的实现是在每次发送请求的时候都将用户的用户名和密码都发送给服务器。而服务器将根据请求中的用户名和密码调用登陆服务,以从该服务中得到用户所对应的Identity和其所具有的权限。接下来,在REST服务中根据用户的权限来访问资源。更一般的是不发送用户名和密码,而是利用一个token来维持客户端状态。
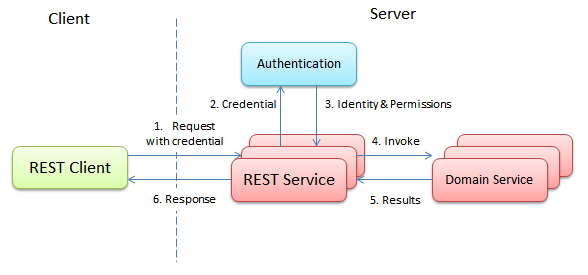
这里有一个问题就是登陆的性能。随着系统当前的加密算法越来越复杂,登陆已经不再是一个轻量级的操作。因此用户所发送的每次请求都要求一次登陆对于整个系统而言就是一个巨大的瓶颈。
在当前,解决该问题的方法主要是一个独立的缓存系统,如整个集群唯一的登陆服务器。但是缓存系统本身所存储的仍然是用户的登陆状态。因此该解决方案将仍然轻微地违反了REST的无状态约束。
还有一个类似的方法是通过添加一个代理来完成的。该代理会完成用户的登陆并获得该用户所拥有的权限。接下来,该代理会将与状态有关的信息从请求中删除,并添加用户的权限信息。在经过了这种处理之后,这些请求就可以转发到其后的各个服务器上了。转发目的地所在的服务器则会假设所有传入的请求都是合法的并直接对这些请求进行处理。
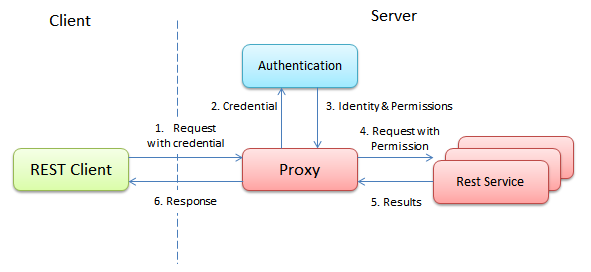
可以看到,无论是一个独立的登陆服务器还是为整个集群添加一个代理,系统中都将有一个地方保留了用户的登陆状态。这实际上和在集群中对会话集中进行管理并没有什么不同。也就是说,我们所尝试的通过禁止使用会话来达成完全的无状态并不现实。因此在一个基于HTTP的REST服务中,为登陆功能使用集中管理的会话是合理的。
既然我们放松了对REST系统的无状态约束,那么一个REST系统所可以使用的登陆机制将主要分为以下两种:
1. 基于HTTPS的Basic Access Authentication
其好处是其易于实现,而且主流的浏览器都提供了对该功能的支持。但是由于登陆窗口都是由浏览器所提供的,因此其与产品外观有很大不同。除此之外,浏览器都没有提供登出的功能,也没有提供找回密码等功能。
2. 基于Cookie及Session的管理
在使用Cookie来管理用户的注册状态的时候,其实际上就是将服务端所返回的Cookie在每次发送请求的时候添加到请求中。虽然说这个Cookie并非存储了用户应用的状态,但是其实际存储了用户的登陆状态。因此客户端的角度来讲,由服务端管理的Session并不符合REST所倡导的无状态的要求。
可以说,上面的两种方法各有优劣。可能第二种方法从客户端的角度看来并不是RESTful的,但是其优势则在于很多类库都直接提供了对该功能的支持,从而简化了会话管理服务器的实现。
总结
(1)设计合适的 API URL,以及选择合适的请求方法,可以语义化的描述一个 HTTP 请求的操作。当我们都熟悉且遵循这样的规范后,基本可以看到一个 REST 风格的接口就知道如何使用这个接口进行 CRUD 操作了。
(2)API的身份认证应该使用OAuth 2.0框架。
(3)服务器返回的数据格式可以是JSON和XML,应该尽量使用JSON,避免使用XML。
(4)前后端分离。前端拿到数据只负责展示和渲染,不对数据做任何处理。后端处理数据并以JSON格式传输出去,定义这样一套统一的接口,在web,ios,android三端都可以用相同的接口。
(5)没有要求一定要使用HTTP。其目标是为了创建具有良好扩展性的分布式系统。
(6)在stackoverflow中,我们常常会看到有人问:我现在使用了这样一种解决方案,这样实现是不是RESTful?此时一些人就会说,这不是RESTful。但是pure RESTful和almost RESTful之间的区别主要还是在于一个是理论,一个是工程。在工程中,轻微地违反了一个准则并不一定代表这个解决方案一无是处。而是要看遵守该准则和轻微地违反了该准则之后工作量的大小以及后期的维护成本:之所以提出一系列准则,那是因为遵守该准则拥有一定的好处。如果对该准则的轻微违反可以减少大量的工作量,而且遵守准则的好处并没有消失,或者是通过另一样技术可以快速地重新获得该好处,那么对准则的轻微违反是值得的。