目录
讲一下你知道的java.util.concurrent包下的类
一面
java类加载过程
一个Java文件从编码完成到最终执行,一般主要包括两个过程:编译和运行。而我们所说的类加载过程是指JVM虚拟机把.class文件中类信息加载进内存,并进行解析生成对应的class对象的过程。JVM不是一开始就把所有的类都加载进内存中,而是只有第一次遇到 某个需要运行的类时才会加载,且只加载一次。
类加载的过程主要分为三个部分:加载、链接、初始化。链接又可以细分为验证、准备和解析三个小部分。
加载
简单来说,加载指的是把class字节码文件从各个来源通过类加载器装载入内存中。
这里有两个重点:
字节码来源。一般的加载来源包括从本地路径下编译生成的.class文件,从jar包中的.class文件,从远程网络,以及动态代理实时编译。
类加载器。一般包括启动类加载器,扩展类加载器,应用类加载器,以及用户的自定义类加载器。
注:为什么会有自定义类加载器?
一方面是由于java代码很容易被反编译,如果需要对自己的代码加密的话,可以对编译后的代码进行加密,然后再通过实现自己的自定义类加载器进行解密,最后再加载。
另一方面也有可能从非标准的来源加载代码,比如从网络来源,那就需要自己实现一个类加载器,从指定源进行加载。
验证
主要是为了保证加载进来的字节流符合虚拟机规范,不会造成安全错误。
包括对于文件格式的验证,比如常量中是否有不被支持的常量?文件中是否有不规范的或者附加的其他信息?
对于元数据的验证,比如该类是否继承了被final修饰的类?类中的字段,方法是否与父类冲突?是否出现了不合理的重载?
对于字节码的验证,保证程序语义的合理性,比如要保证类型转换的合理性。
对于符号引用的验证,比如校验符号引用中通过全限定名是否能够找到对应的类?校验符号引用中的访问性(private,public等)是否可被当前类访问?
准备
主要是为类变量(注意,不是实例变量)分配内存,并且赋予初值。
特别需要注意,初值,不是代码中具体写的初始化的值,而是Java虚拟机根据不同变量类型的默认初始值。
比如8种基本类型的初值,默认为0;引用类型的初值则为null;常量的初值即为代码中设置的值,final static tmp = 456, 那么该阶段tmp的初值就是456
解析
将常量池内的符号引用替换为直接引用的过程。
两个重点:
符号引用。即一个字符串,但是这个字符串给出了一些能够唯一性识别一个方法,一个变量,一个类的相关信息。
直接引用。可以理解为一个内存地址,或者一个偏移量。比如类方法,类变量的直接引用是指向方法区的指针;而实例方法,实例变量的直接引用则是从实例的头指针开始算起到这个实例变量位置的偏移量
举个例子来说,现在调用方法hello(),这个方法的地址是1234567,那么hello就是符号引用,1234567就是直接引用。
在解析阶段,虚拟机会把所有的类名,方法名,字段名这些符号引用替换为具体的内存地址或偏移量,也就是直接引用。
初始化
这个阶段主要是对类变量初始化,是执行类构造器的过程。
换句话说,只对static修饰的变量或语句进行初始化。
如果初始化一个类的时候,其父类尚未初始化,则优先初始化其父类。
如果同时包含多个静态变量和静态代码块,则按照自上而下的顺序依次执行。
总结
类加载过程只是一个类生命周期的一部分,在其前,有编译的过程,只有对源代码编译之后,才能获得能够被虚拟机加载的字节码文件;在其后还有具体的类使用过程,当使用完成之后,还会在方法区垃圾回收的过程中进行卸载。如果想要了解Java类整个生命周期的话,可以自行上网查阅相关资料,这里不再多做赘述。
在面试过程中类加载过程虽然是一个老生常谈的问题,但是往往从这个问题还可以衍生出很多其他重要的知识点,已经罗列在下文中,如果大家感兴趣的话,可以自行学习,小编也会在之后的文章中,对其中的一些问题进行解答和总结。
相关扩展知识点:
-
Java虚拟机的基本机构?
-
什么是类加载器?
-
简单谈一下类加载的双亲委托机制?
-
普通Java类的类加载过程和Tomcat的类加载过程是否一样?区别在哪?
-
简单谈一下Java堆的垃圾回收机制?
数据库索引怎么实现的
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常用B_TREE。B_TREE索引加速了数据访问,因为存储引擎不会再去扫描整张表得到需要的数据;相反,他从根节点开始,根节点保存了子节点的指针,存储引擎会根据指针快速寻找数据。
B_TREE(来源于数据结构,做个收藏)
1、B_TREE的定义
B_TREE是一种平衡多叉排序树,是一种动态查找效率很高的树形结构。B_TREE中所有结点的孩子结点的最大值称为B_TREE的阶,B_TREE的阶通常用m表示,简称为m叉树。一般来说,应该是m>=3。一颗m阶的B_TREE或是一颗空树,或者是满足下列条件的m叉树:
- 树中每个结点最多有m个孩子结点;
- 除根结点外,其它结点至少有(int)m/2+1个孩子结点;
- 若根结点不是叶子节点,则根结点至少有2个孩子结点;
- 结点的结构:
 其中,n为结点中关键字个数,(int)m/2<=n<m;di(1<=i<=n)为该结点的n个关键字值的第i个,且di<d(i+1);ci(0<=i<=n)为该结点孩子结点的指针,且ci所指向的节点的关键字均大于或等于di且小于d(i+1);
其中,n为结点中关键字个数,(int)m/2<=n<m;di(1<=i<=n)为该结点的n个关键字值的第i个,且di<d(i+1);ci(0<=i<=n)为该结点孩子结点的指针,且ci所指向的节点的关键字均大于或等于di且小于d(i+1); - 所有的叶结点都在同一层上。
一棵4阶B_TREE的示例。4叉树结点的孩子结点的个数范围[2,4]。其中,有2个结点有4个孩子结点,有1个结点有3个孩子结点,有5个结点有2个孩子结点。

图 一棵4阶B_TREE
2、B_TREE的查找
在B_TREE上查找x,现将x的关键字与根结点的n个关键字di逐个比较,然后做如下处理:
- 若x.key==di,则查找成功返回;
- 若x.key<d1,则沿着指针c0所指的子树继续查找;
- 若di<x.key<d(i+1),则沿着指针ci所指的子树继续查找;
- 若x.key>dn,则沿着指针cn所指的子树继续查找。
3、B_TREE的插入
将元素x插入到B_TREE的过程为:
- 查找到x应该插入的结点(插入结点一定是叶结点);
- 判断该结点是否还有空位置,即判断该结点是否满足结点关键字的个数n小于m-1这个条件。若n<m-1,则说明该结点还有空位置,直接把数据插入(注意插入时要满足B_TREE结点结构定义);若n=m-1,则需要分裂该结点,即以中间关键字为界(包括要插入的关键字)把结点分为两个结点,并把中间元素向上插入到双亲结点,若双亲结点未满,则把它插入到双亲结点合适的位置,否则,继续往上分裂(直到根结点分裂可能会有树的高度增1的可能)。
4、B_TREE的删除
定义要删除结点x的关键字的个数为n,l=(int)m/2;
- 查找x是否存在,若不存在,则返回;若存在,则继续;
- 对于叶结点上的删除,分为3种情况:1、n>l则直接删除该数据元素;2、n=l且该结点左(右)兄弟结点关键字个数大于l,把删除数据元素结点的左(右)兄弟结点中最大(小)的元素上移到双亲结点上,同时把双亲结点中大于(小于)上移关键字的关键字下移到要删除数据元素的结点上;3、n=l且该结点左(右)兄弟结点关键字个数等于l,把要删除数据元素的结点的左(右)兄弟结点以及双亲结点上分割二者的数据元素合并成一个结点;
- 对于非叶结点的删除,可以转换为叶结点上的删除:假设要删除的元素为di,首先寻找要删除数据元素的结点的ci所指向子树中的最小关键字,设为d(min),然后把k(min)复制到ki,最后删除关键字为k(min)的元素(此时的k(min)必为某个叶结点上的元素)。
b树和b+树的区别
一,b树
b树(balance tree)和b+树应用在数据库索引,可以认为是m叉的多路平衡查找树,但是从理论上讲,二叉树查找速度和比较次数都是最小的,为什么不用二叉树呢?
因为我们要考虑磁盘IO的影响,它相对于内存来说是很慢的。数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘页(对应索引树的节点)。所以我们要减少IO次数,对于树来说,IO次数就是树的高度,而“矮胖”就是b树的特征之一,它的每个节点最多包含m个孩子,m称为b树的阶,m的大小取决于磁盘页的大小。
█一个M阶的b树具有如下几个特征:
- 定义任意非叶子结点最多只有M个儿子,且M>2;
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M],向上取整;
- 非叶子结点的关键字个数=儿子数-1;
- 所有叶子结点位于同一层;
- k个关键字把节点拆成k+1段,分别指向k+1个儿子,同时满足查找树的大小关系。
█有关b树的一些特性,注意与后面的b+树区分:
- 关键字集合分布在整颗树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束;
- 其搜索性能等价于在关键字全集内做一次二分查找;
█如图是一个3阶b树,顺便讲一下查询元素5的过程: 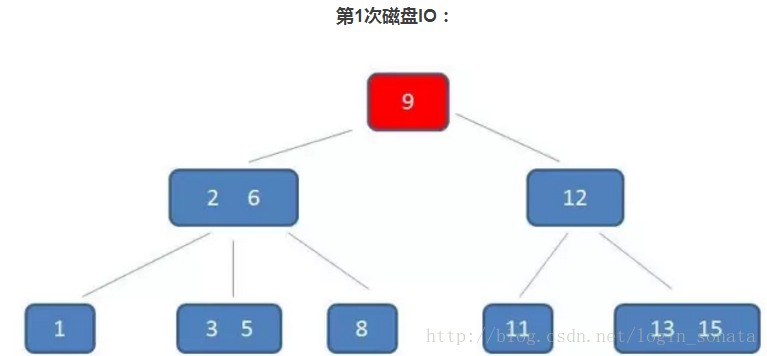
1,第一次磁盘IO,把9所在节点读到内存,把目标数5和9比较,小,找小于9对应的节点;
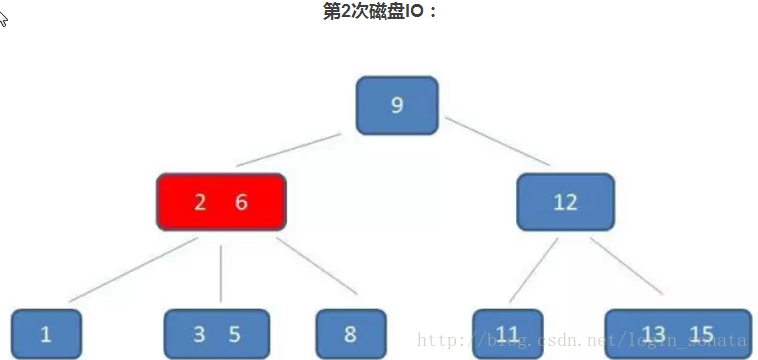
2,第二次磁盘IO,还是读节点到内存,在内存中把5依次和2、6比较,定位到2、6中间区域对应的节点;
3,第三次磁盘IO就不上图了,跟第二步一样,然后就找到了目标5。
可以看到,b树在查询时的比较次数并不比二叉树少,尤其是节点中的数非常多时,但是内存的比较速度非常快,耗时可以忽略,所以只要树的高度低,IO少,就可以提高查询性能,这是b树的优势之一。
█b树的插入删除元素操作:
比如我们要在下图中插入元素4: 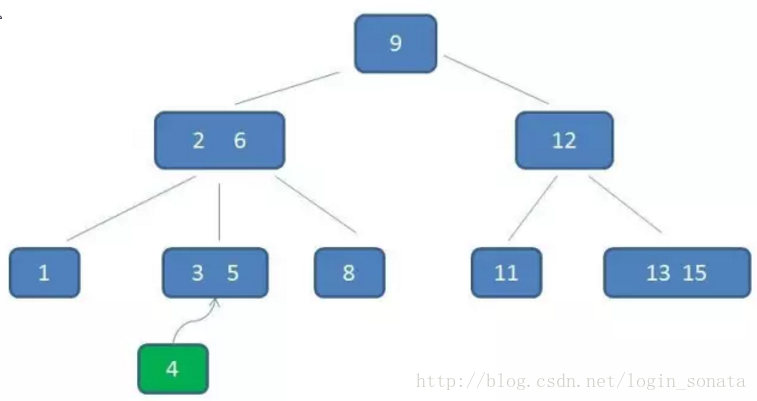
1,首先自顶向下查询找到4应该在的位置,即3、5之间;
2,但是3阶b树的节点最多只能有2个元素,所以把3、4、5里面的中间元素4上移(中间元素上移是插入操作的关键);
3,上一层节点加入4之后也超载了,继续中间元素上移的操作,现在根节点变成了4、9;
4,还要满足查找树的性质,所以对元素进行调整以满足大小关系,始终维持多路平衡也是b树的优势,最后变成这样: 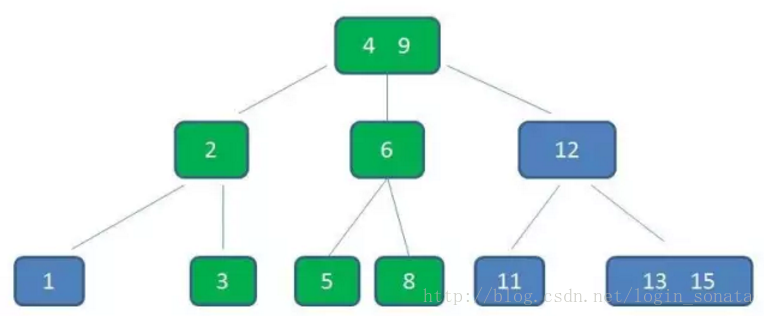
再比如我们要删除元素11:
1,自顶向下查询到11,删掉它;
2,然后不满足b树的条件了,因为元素12所在的节点只有一个孩子了,所以我们要“左旋”,元素12下来,元素13上去: 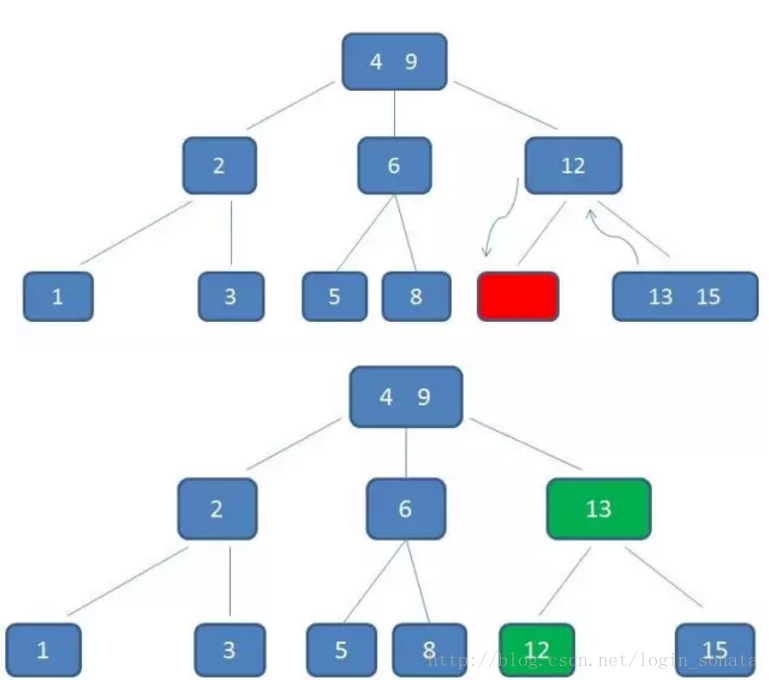
这时如果再删除15呢?很简单,当元素个数太少以至于不能再旋转时,12直接上去就行了。
二,b+树
b+树,是b树的一种变体,查询性能更好。m阶的b+树的特征:
- 有n棵子树的非叶子结点中含有n个关键字(b树是n-1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(b树是每个关键字都保存数据)。
- 所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
- 所有的非叶子结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
- 通常在b+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
- 同一个数字会在不同节点中重复出现,根节点的最大元素就是b+树的最大元素。
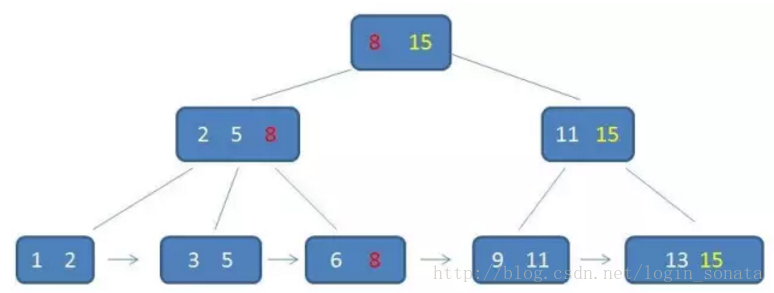
█b+树相比于b树的查询优势:
- b+树的中间节点不保存数据,所以磁盘页能容纳更多节点元素,更“矮胖”;
- b+树查询必须查找到叶子节点,b树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢);
- 对于范围查找来说,b+树只需遍历叶子节点链表即可,b树却需要重复地中序遍历,如下两图:
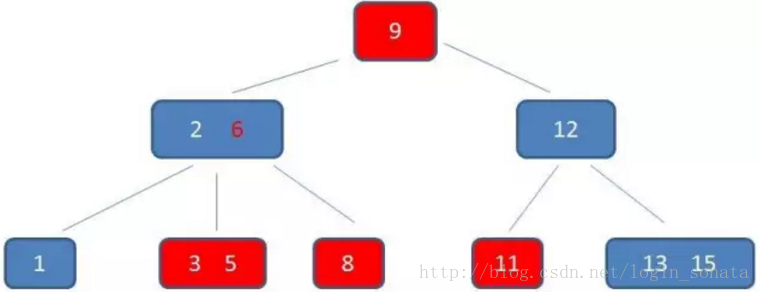
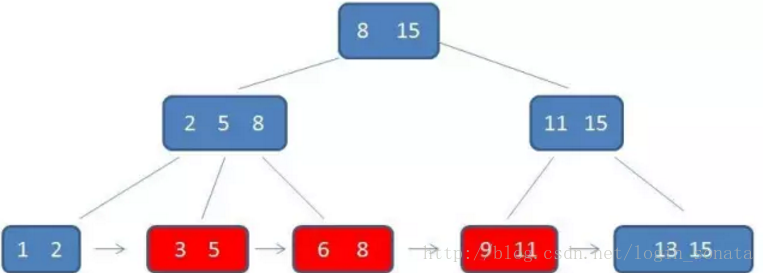
画一个b+树
讲一下你知道的java.util.concurrent包下的类
1.Callable<V>
Callable<V>与Runnable类似,理解Callable<V>可以从比较其与Runnable的区别开始:
1)从使用上:实现的Callable<V>的类需要实现call()方法,此方法有返回对象V;而Runnable的子类需要实现run()方法,但没有返回值;
2)如果直接调用Callable<V>的子类的call()方法,代码是同步顺序执行的;而Runnable的子类是线程,是代码异步执行。
3)将Callable子类submit()给线程池去运行,那么在时间上几个Callable的子类的执行是异步的。
即:如果一个Callable执行需要5s,那么直接调用Callable.call(),执行3次需要15s;
而将Callable子类交个线程执行3次,在池可用的情况下,只需要5s。这就是基本的将任务拆分异步执行的做法。
4)callable与future的组合用法:
(什么是Future?Future 表示异步计算的结果。其用于获取线程池执行callable后的结果,这个结果封装为Future类。详细可以参看Future的API,有示例。)
一种就像上面所说,对一个大任务进行分制处理;
另一种就是对一个任务的多种实现方法共同执行,任何一个返回计算结果,则其他的任务就没有执行的必要。选取耗时最少的结果执行。
2.Semaphore
一个计数信号量,主要用于控制多线程对共同资源库访问的限制。
典型的实例:1)公共厕所的蹲位……,10人等待5个蹲位的测试,满员后就只能出一个进一个。
2)地下车位,要有空余才能放行
3)共享文件IO数等
与线程池的区别:线程池是控制线程的数量,信号量是控制共享资源的并发访问量。
实例:Semaphore avialable = new Semaphore(int x,boolean y);
x:可用资源数;y:公平竞争或非公平竞争(公平竞争会导致排队,等待最久的线程先获取资源)
用法:在获取工作资源前,用Semaphore.acquire()获取资源,如果资源不可用则阻塞,直到获取资源;操作完后,用Semaphore.release()归还资源
代码示例:(具体管理资源池的示例,可以参考API的示例)
[java] view plain copy
public class SemaphoreTest {
private static final int NUMBER = 5; //限制资源访问数
private static final Semaphore avialable = new Semaphore(NUMBER,true);
public static void main(String[] args) {
ExecutorService pool = Executors.newCachedThreadPool();
Runnable r = new Runnable(){
public void run(){
try {
avialable.acquire(); //此方法阻塞
Thread.sleep(10*1000);
System.out.println(getNow()+"--"+Thread.currentThread().getName()+"--执行完毕");
avialable.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
System.out.println(avialable.availablePermits());
for(int i=0;i<10;i++){
pool.execute(r);
}
System.out.println(avialable.availablePermits());
pool.shutdown();
}
public static String getNow(){
SimpleDateFormat sdf = new SimpleDateFormat("mm:ss");
return sdf.format(new Date());
}
}
3.ReentrantLock与Condition
1.ReentrantLock:可重入互斥锁。使用上与synchronized关键字对比理解:
1.1)synchronized示例:
[java] view plain copy
synchronized(object){
//do process to object
}
1.2)ReentrantLock示例:(api)
[java] view plain copy
private final ReentrantLock lock = new ReentrantLock();
public void m() {
lock.lock(); // block until condition holds
try {
// ... method body
} finally {
lock.unlock()
}
}
由1.1)和1.2)的示例很好理解,ReetantLock也就是一个锁,线程执行某段代码时,需要争用此类实例的锁,用完后要显示的释放此锁。
至于具体区别,后面在说……
2.Condition:此类是同步的条件对象,每个Condition实例绑定到一个ReetrantLock中,以便争用同一个锁的多线程之间可以通过Condition的状态来获取通知。
注意:使用Condition前,首先要获得ReentantLock,当条件不满足线程1等待时,ReentrantLock会被释放,以能让其他线程争用,其他线程获得reentrantLock,然后满足条件,唤醒线程1继续执行。
这与wait()方法是一样的,调用wait()的代码块要被包含在synchronized块中,而当线程r1调用了objectA.wait()方法后,同步对象的锁会释放,以能让其他线程争用;其他线程获取同步对象锁,完成任务,调用objectA.notify(),让r1继续执行。代码示例如下。
代码示例1(调用condition.await();会释放lock锁):
[java] view plain copy
public class ConditionTest {
private static final ReentrantLock lock = new ReentrantLock(true);
//从锁中创建一个绑定条件
private static final Condition condition = lock.newCondition();
private static int count = 1;
public static void main(String[] args) {
Runnable r1 = new Runnable(){
public void run(){
lock.lock();
try{
while(count<=5){
System.out.println(Thread.currentThread().getName()+"--"+count++);
Thread.sleep(1000);
}
condition.signal(); //线程r1释放条件信号,以唤醒r2中处于await的代码继续执行。
} catch (InterruptedException e) {
e.printStackTrace();
}finally{
lock.unlock();
}
}
};
Runnable r2 = new Runnable(){
public void run(){
lock.lock();
try{
if(count<=5){
System.out.println("----$$$---");
condition.await(); //但调用await()后,lock锁会被释放,让线程r1能获取到,与Object.wait()方法一样
System.out.println("----------");
}
while(count<=10){
System.out.println(Thread.currentThread().getName()+"--"+count++);
Thread.sleep(1000);
}
} catch (InterruptedException e) {
e.printStackTrace();
}finally{
lock.unlock();
}
}
};
new Thread(r2).start(); //让r2先执行,先获得lock锁,但条件不满足,让r2等待await。
try {
Thread.sleep(100); //这里休眠主要是用于测试r2.await()会释放lock锁,被r1获取
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(r1).start();
}
}
代码示例2(此例子来自于Condition的API):
[java] view plain copy
public class ConditionMain {
public static void main(String[] args) {
final BoundleBuffer buf = new ConditionMain().new BoundleBuffer();
new Thread(new Runnable(){
public void run() {
for(int i=0;i<1000;i++){
try {
buf.put(i);
System.out.println("入值:"+i);
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
new Thread(new Runnable(){
public void run() {
for(int i=0;i<1000;i++){
try {
int x = buf.take();
System.out.println("出值:"+x);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
}
public class BoundleBuffer {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Integer[] items = new Integer[10];
int putptr, takeptr, count;
public void put(int x) throws InterruptedException {
System .out.println("put wait lock");
lock.lock();
System .out.println("put get lock");
try {
while (count == items.length){
System.out.println("buffer full, please wait");
notFull.await();
}
items[putptr] = x;
if (++putptr == items.length)
putptr = 0;
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
public int take() throws InterruptedException {
System .out.println("take wait lock");
lock.lock();
System .out.println("take get lock");
try {
while (count == 0){
System.out.println("no elements, please wait");
notEmpty.await();
}
int x = items[takeptr];
if (++takeptr == items.length)
takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
}
4.BlockingQueue
简单介绍。这是一个阻塞的队列超类接口,concurrent包下很多架构都基于这个队列。BlockingQueue是一个接口,此接口的实现类有:ArrayBlockingQueue, DelayQueue, LinkedBlockingDeque, LinkedBlockingQueue, PriorityBlockingQueue, SynchronousQueue 。每个类的具体使用可以参考API。
这些实现类都遵从共同的接口定义(一目了然,具体参考api):
[html] view plain copy
抛出异常 特殊值 阻塞 超时
插入 add(e) offer(e) put(e) offer(e, time, unit)
移除 remove() poll() take() poll(time, unit)
检查 element() peek() 不可用 不可用
5.CompletionService
1.CompletionService是一个接口,用来保存一组异步求解的任务结果集。api的解释是:将新生产的异步任务与已完成的任务结果集分离开来。
2.CompletionService依赖于一个特定的Executor来执行任务。实际就是此接口需要多线程处理一个共同的任务,这些多线程由一个指定的线程池来管理。CompletionService的实现类ExecutorCompletionService。
3.api的官方代码示例参考ExecutorCompletionService类的api(一个通用分制概念的函数)。
4.使用示例:如有时我们需要一次插入大批量数据,那么可能我们需要将1w条数据分开插,异步执行。如果某个异步任务失败那么我们还要重插,那可以用CompletionService来实现。下面是简单代码:
(代码中1w条数据分成10份,每次插1000条,如果成功则返回true,如果失败则返回false。那么忽略数据库的东西,我们假设插1w条数据需10s,插1k条数据需1s,那么下面的代码分制后,插入10条数据需要2s。为什么是2s呢?因为我们开的线程池是8线程,10个异步任务就有两个需要等待池资源,所以是2s,如果将下面的8改为10,则只需要1s。)
[java] view plain copy
public class CompletionServiceTest {
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(8); //需要2s,如果将8改成10,则只需要1s
CompletionService<Boolean> cs = new ExecutorCompletionService<Boolean>(pool);
Callable<Boolean> task = new Callable<Boolean>(){
public Boolean call(){
try {
Thread.sleep(1000);
System.out.println("插入1000条数据完成");
} catch (InterruptedException e) {
e.printStackTrace();
}
return true;
};
};
System.out.println(getNow()+"--开始插入数据");
for(int i=0;i<10;i++){
cs.submit(task);
}
for(int i=0;i<10;i++){
try {
//ExecutorCompletionService.take()方法是阻塞的,如果当前没有完成的任务则阻塞
System.out.println(cs.take().get());
//实际使用时,take()方法获取的结果可用于处理,如果插入失败,则可以进行重试或记录等操作
} catch (InterruptedException|ExecutionException e) {
e.printStackTrace();
}
}
System.out.println(getNow()+"--插入数据完成");
pool.shutdown();
}
public static String getNow(){
SimpleDateFormat sdf = new SimpleDateFormat("mm:ss");
return sdf.format(new Date());
}
}
5.CompletionService与Callable<V>+Future的对比:
在上面的Callable中说过,Callable+Future能实现任务的分治,但是有个问题就是:不知道call()什么时候完成,需要人为控制等待。
而jdk通过CompetionService已经将此麻烦简化,通过CompletionService将异步任务完成的与未完成的区分开来(正如api的描述),我们只用去取即可。
CompletionService有什么好处呢?
如上所说:1)将已完成的任务和未完成的任务分开了,无需开发者操心;2)隐藏了Future类,简化了代码的使用。真想点个赞!
6.CountDownLatch
1.CountDownLatch:api解释:一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。个人理解是CountDownLatch让可以让一组线程同时执行,然后在这组线程全部执行完前,可以让另一个线程等待。
就好像跑步比赛,10个选手依次就位,哨声响才同时出发;所有选手都通过终点,才能公布成绩。那么CountDownLatch就可以控制10个选手同时出发,和公布成绩的时间。
CountDownLatch 是一个通用同步工具,它有很多用途。将计数 1 初始化的 CountDownLatch 用作一个简单的开/关锁存器,或入口:在通过调用 countDown() 的线程打开入口前,所有调用 await 的线程都一直在入口处等待。用 N 初始化的 CountDownLatch 可以使一个线程在 N 个线程完成某项操作之前一直等待,或者使其在某项操作完成 N 次之前一直等待。
CountDownLatch startSignal = new CountDownLatch(1);
CountDownLatch doneSignal = new CountDownLatch(N);
代码示例可参考api的示例。(重要)
2.代码示例:
参考链接中的示例:http://blog.csdn.net/xsl1990/article/details/18564097
个人示例:
[java] view plain copy
public class CountDownLatchTest {
private static SimpleDateFormat sdf = new SimpleDateFormat("mm:ss");
public static void main(String[] args) {
final CountDownLatch start = new CountDownLatch(1); //用一个信号控制一组线程的开始,初始化为1
final CountDownLatch end = new CountDownLatch(10); //要等待N个线程的结束,初始化为N,这里是10
Runnable r = new Runnable(){
public void run(){
try {
start.await(); //阻塞,这样start.countDown()到0,所有阻塞在start.await()处的线程一起执行
Thread.sleep((long) (Math.random()*10000));
System.out.println(getNow()+"--"+Thread.currentThread().getName()+"--执行完成");
end.countDown();//非阻塞,每个线程执行完,让end--,这样10个线程执行完end倒数到0,主线程的end.await()就可以继续执行
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
for(int i=0;i<10;i++){
new Thread(r).start(); //虽然开始了10个线程,但所有线程都阻塞在start.await()处
}
System.out.println(getNow()+"--线程全部启动完毕,休眠3s再让10个线程一起执行");
try {
Thread.sleep(3*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getNow()+"--开始");
start.countDown(); //start初始值为1,countDown()变成0,触发10个线程一起执行
try {
end.await(); //阻塞,等10个线程都执行完了才继续往下。
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getNow()+"--10个线程都执行完了,主线程继续往下执行!");
}
private static String getNow(){
return sdf.format(new Date());
}
}
7.CyclicBarrier
1.一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点。也就是说,这一组线程的执行分几个节点,每个节点往下执行,都需等待其他线程,这就需要这种等待具有循环性。CyclicBarrier在这样的情况下就很有用。
2.CyclicBarrier与CountDownLacth的区别:
1)CountDownLacth用于一个线程与一组线程之间的相互等待。常用的就是一个主线程与一组分治线程之间的等待:主线程发号令,一组线程同时执行;一组线程依次执行完,再唤醒主线程继续执行;
CyclicBarrier用于一组线程执行时,每个线程执行有多个节点,每个节点的处理需要相互等待。如:对5个文件进行处理,按行将各个文件数字挑出来合并成一行,排序,并输出到另一个文件,那每次处理都需要等待5个线程读入下一行。(api示例可供参考)
2)CountDownLacth的处理机制是:初始化一个值N(相当于一组线程有N个),每个线程调用一次countDown(),那么cdLatch减1,等所有线程都调用过countDown(),那么cdLatch值达到0,那么线程从await()处接着玩下执行。
CyclicBarrier的处理机制是:初始化一个值N(相当于一组线程有N个),每个线程调用一次await(),那么barrier加1,等所有线程都调用过await(),那么barrier值达到初始值N,所有线程接着往下执行,并将barrier值重置为0,再次循环下一个屏障;
3)由2)可以知道,CountDownLatch只可以使用一次,而CyclicBarrier是可以循环使用的。
3.个人用于理解的示例:
[java] view plain copy
public class CyclicBarrierTest {
private static final CyclicBarrier barrier = new CyclicBarrier(5,
new Runnable(){
public void run(){ //每次线程到达屏障点,此方法都会执行
System.out.println("\n--------barrier action--------\n");
}
});
public static void main(String[] args) {
for(int i=0;i<5;i++){
new Thread(new CyclicBarrierTest().new Worker()).start();
}
}
class Worker implements Runnable{
public void run(){
try {
System.out.println(Thread.currentThread().getName()+"--第一阶段");
Thread.sleep(getRl());
barrier.await(); //每一次await()都会阻塞,等5个线程都执行到这一步(相当于barrier++操作,加到初始化值5),才继续往下执行
System.out.println(Thread.currentThread().getName()+"--第二阶段");
Thread.sleep(getRl());
barrier.await(); //每一次5个线程都到达共同的屏障节点,会执行barrier初始化参数中定义的Runnable.run()
System.out.println(Thread.currentThread().getName()+"--第三阶段");
Thread.sleep(getRl());
barrier.await();
System.out.println(Thread.currentThread().getName()+"--第四阶段");
Thread.sleep(getRl());
barrier.await();
System.out.println(Thread.currentThread().getName()+"--第五阶段");
Thread.sleep(getRl());
barrier.await();
System.out.println(Thread.currentThread().getName()+"--结束");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}
public static long getRl(){
return Math.round(10000);
}
}
4.参考api的示例。
api的示例自己看,就是加深印象。
但是api中有一点描述:如果屏障操作在执行时不依赖于正挂起的线程,则线程组中的任何线程在获得释放时都能执行该操作。为方便此操作,每次调用 await() 都将返回能到达屏障处的线程的索引。然后,您可以选择哪个线程应该执行屏障操作,例如:
[java] view plain copy
if (barrier.await() == 0) {
<span style="white-space:pre"> </span> // log the completion of this iteration
}
就是说,barrier.await()还会返回一个int值。这个返回值到底是什么呢?不是返回的线程的索引,返回的是:N-进入等待线程数,如5个线程,5线程都进入等待,那返回值就是0(具体可以参看源码)。那么barrier.await()==0也可以看做是一个N线程都达到公共屏障的信号,然后在此条件下处理原本需要放在Runnable参数中的逻辑。不用担心多线程会多次执行此逻辑,N个线程只有一个线程barrier.await()==0。
8.Exchanger
1.Exchanger可以在对中对元素进行配对和交换的线程的同步点。api上不是太好理解,个人理解说白了就是两个线程交换各自使用的指定内存数据。
2.场景:
api中有示例,两个线程A、B,各自有一个数据类型相同的变量a、b,A线程往a中填数据(生产),B线程从b中取数据(消费)。具体如何让a、b在内存发生关联,就由Exchanger完成。
api中说:Exchanger 可能被视为 SynchronousQueue 的双向形式。怎么理解呢?传统的SynchronousQueue存取需要同步,就是A放入需要等待B取出,B取出需要等待A放入,在时间上要同步进行。而Exchanger在B取出的时候,A是同步在放入的。即:1)A放入a,a满,然后与B交换内存,那A就可以操作b(b空),而B可以操作a;2)等b被A存满,a被B用完,再交换;3)那A又填充a,B又消费b,依次循环。两个内存在一定程度上是同时被操作的,在时间上不需要同步。
再理解就是:如果生产需要5s,消费需要5s。SynchronousQueue一次存取需要10s,而Exchanger只需要5s。4.注意事项:
目前只知道Exchanger只能发生在两个线程之间。但实际上Exchanger的源码是有多个插槽(Slot),交换是通过线程ID的hash值来定位的。目前还没搞懂?待后续。
如果一组线程aGroup操作a内存,一组线程bGroup操作b内存,如何交换?能不能交换?
3.代码示例:
[java] view plain copy
public class ExchangerTest {
private SimpleDateFormat sdf = new SimpleDateFormat("mm:ss");
private static Exchanger<Queue<Integer>> changer = new Exchanger<Queue<Integer>>();
public static void main(String[] args) {
new Thread(new ExchangerTest().new ProducerLoop()).start();
new Thread(new ExchangerTest().new ConsumerLoop()).start();
}
class ProducerLoop implements Runnable{
private Queue<Integer> pBuffer = new LinkedBlockingQueue<Integer>();
private final int maxnum = 10;
@Override
public void run() {
try{
for(;;){
Thread.sleep(500);
pBuffer.offer((int) Math.round(Math.random()*100));
if(pBuffer.size() == maxnum){
System.out.println(getNow()+"--producer交换前");
pBuffer = changer.exchange(pBuffer);
System.out.println(getNow()+"--producer交换后");
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
class ConsumerLoop implements Runnable{
private Queue<Integer> cBuffer = new LinkedBlockingQueue<Integer>();
@Override
public void run() {
try{
for(;;){
if(cBuffer.size() == 0){
System.out.println("\n"+getNow()+"--consumer交换前");
cBuffer = changer.exchange(cBuffer);
System.out.println(getNow()+"--consumer交换后");
}
System.out.print(cBuffer.poll()+" ");
Thread.sleep(500);
}
}catch(Exception e){
e.printStackTrace();
}
}
}
private String getNow(){
return sdf.format(new Date());
}
}
4.注意事项:
目前只知道Exchanger只能发生在两个线程之间。但实际上Exchanger的源码是有多个插槽(Slot),交换是通过线程ID的hash值来定位的。目前还没搞懂?待后续。
如果一组线程aGroup操作a内存,一组线程bGroup操作b内存,如何交换?能不能交换?
9.Phaser
Phaser是jdk1.7的新特性。其功能类似CyclicBarrier和CountDownLatch,但其功能更灵活,更强大,支持动态调整需要控制的线程数。不重复了。
---------------------
作者:afanti222
来源:CSDN
原文:https://blog.csdn.net/afanti222/article/details/80278329
版权声明:本文为博主原创文章,转载请附上博文链接!
treemap了解吗
第1部分 TreeMap介绍
TreeMap 简介
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
TreeMap的构造函数

// 默认构造函数。使用该构造函数,TreeMap中的元素按照自然排序进行排列。 TreeMap() // 创建的TreeMap包含Map TreeMap(Map<? extends K, ? extends V> copyFrom) // 指定Tree的比较器 TreeMap(Comparator<? super K> comparator) // 创建的TreeSet包含copyFrom TreeMap(SortedMap<K, ? extends V> copyFrom)
TreeMap的API
Entry<K, V> ceilingEntry(K key) K ceilingKey(K key) void clear() Object clone() Comparator<? super K> comparator() boolean containsKey(Object key) NavigableSet<K> descendingKeySet() NavigableMap<K, V> descendingMap() Set<Entry<K, V>> entrySet() Entry<K, V> firstEntry() K firstKey() Entry<K, V> floorEntry(K key) K floorKey(K key) V get(Object key) NavigableMap<K, V> headMap(K to, boolean inclusive) SortedMap<K, V> headMap(K toExclusive) Entry<K, V> higherEntry(K key) K higherKey(K key) boolean isEmpty() Set<K> keySet() Entry<K, V> lastEntry() K lastKey() Entry<K, V> lowerEntry(K key) K lowerKey(K key) NavigableSet<K> navigableKeySet() Entry<K, V> pollFirstEntry() Entry<K, V> pollLastEntry() V put(K key, V value) V remove(Object key) int size() SortedMap<K, V> subMap(K fromInclusive, K toExclusive) NavigableMap<K, V> subMap(K from, boolean fromInclusive, K to, boolean toInclusive) NavigableMap<K, V> tailMap(K from, boolean inclusive) SortedMap<K, V> tailMap(K fromInclusive)
第2部分 TreeMap数据结构
TreeMap的继承关系
java.lang.Object
↳ java.util.AbstractMap<K, V>
↳ java.util.TreeMap<K, V>
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable {}
TreeMap与Map关系如下图:

从图中可以看出:
(01) TreeMap实现继承于AbstractMap,并且实现了NavigableMap接口。
(02) TreeMap的本质是R-B Tree(红黑树),它包含几个重要的成员变量: root, size, comparator。
root 是红黑数的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
红黑数排序时,根据Entry中的key进行排序;Entry中的key比较大小是根据比较器comparator来进行判断的。
size是红黑数中节点的个数。
关于红黑数的具体算法,请参考"红黑树(一) 原理和算法详细介绍"。
第3部分 TreeMap源码解析(基于JDK1.6.0_45)
为了更了解TreeMap的原理,下面对TreeMap源码代码作出分析。我们先给出源码内容,后面再对源码进行详细说明,当然,源码内容中也包含了详细的代码注释。读者阅读的时候,建议先看后面的说明,先建立一个整体印象;之后再阅读源码。
 View Code
View Code
说明:
在详细介绍TreeMap的代码之前,我们先建立一个整体概念。
TreeMap是通过红黑树实现的,TreeMap存储的是key-value键值对,TreeMap的排序是基于对key的排序。
TreeMap提供了操作“key”、“key-value”、“value”等方法,也提供了对TreeMap这颗树进行整体操作的方法,如获取子树、反向树。
后面的解说内容分为几部分,
首先,介绍TreeMap的核心,即红黑树相关部分;
然后,介绍TreeMap的主要函数;
再次,介绍TreeMap实现的几个接口;
最后,补充介绍TreeMap的其它内容。
TreeMap本质上是一颗红黑树。要彻底理解TreeMap,建议读者先理解红黑树。关于红黑树的原理,可以参考:红黑树(一) 原理和算法详细介绍
第3.1部分 TreeMap的红黑树相关内容
TreeMap中于红黑树相关的主要函数有:
1 数据结构
1.1 红黑树的节点颜色--红色
private static final boolean RED = false;
1.2 红黑树的节点颜色--黑色
private static final boolean BLACK = true;
1.3 “红黑树的节点”对应的类。
static final class Entry<K,V> implements Map.Entry<K,V> { ... }
Entry包含了6个部分内容:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)
Entry节点根据key进行排序,Entry节点包含的内容为value。
2 相关操作
2.1 左旋
private void rotateLeft(Entry<K,V> p) { ... }
2.2 右旋
private void rotateRight(Entry<K,V> p) { ... }
2.3 插入操作
public V put(K key, V value) { ... }
2.4 插入修正操作
红黑树执行插入操作之后,要执行“插入修正操作”。
目的是:保红黑树在进行插入节点之后,仍然是一颗红黑树
private void fixAfterInsertion(Entry<K,V> x) { ... }
2.5 删除操作
private void deleteEntry(Entry<K,V> p) { ... }
2.6 删除修正操作
红黑树执行删除之后,要执行“删除修正操作”。
目的是保证:红黑树删除节点之后,仍然是一颗红黑树
private void fixAfterDeletion(Entry<K,V> x) { ... }
关于红黑树部分,这里主要是指出了TreeMap中那些是红黑树的主要相关内容。具体的红黑树相关操作API,这里没有详细说明,因为它们仅仅只是将算法翻译成代码。读者可以参考“红黑树(一) 原理和算法详细介绍”进行了解。
第3.2部分 TreeMap的构造函数
1 默认构造函数
使用默认构造函数构造TreeMap时,使用java的默认的比较器比较Key的大小,从而对TreeMap进行排序。
public TreeMap() {
comparator = null;
}
2 带比较器的构造函数
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
3 带Map的构造函数,Map会成为TreeMap的子集
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
该构造函数会调用putAll()将m中的所有元素添加到TreeMap中。putAll()源码如下:
public void putAll(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
从中,我们可以看出putAll()就是将m中的key-value逐个的添加到TreeMap中。
4 带SortedMap的构造函数,SortedMap会成为TreeMap的子集
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
该构造函数不同于上一个构造函数,在上一个构造函数中传入的参数是Map,Map不是有序的,所以要逐个添加。
而该构造函数的参数是SortedMap是一个有序的Map,我们通过buildFromSorted()来创建对应的Map。
buildFromSorted涉及到的代码如下:
View Code
要理解buildFromSorted,重点说明以下几点:
第一,buildFromSorted是通过递归将SortedMap中的元素逐个关联。
第二,buildFromSorted返回middle节点(中间节点)作为root。
第三,buildFromSorted添加到红黑树中时,只将level == redLevel的节点设为红色。第level级节点,实际上是buildFromSorted转换成红黑树后的最底端(假设根节点在最上方)的节点;只将红黑树最底端的阶段着色为红色,其余都是黑色。
第3.3部分 TreeMap的Entry相关函数
TreeMap的 firstEntry()、 lastEntry()、 lowerEntry()、 higherEntry()、 floorEntry()、 ceilingEntry()、 pollFirstEntry() 、 pollLastEntry() 原理都是类似的;下面以firstEntry()来进行详细说明
我们先看看firstEntry()和getFirstEntry()的代码:
public Map.Entry<K,V> firstEntry() {
return exportEntry(getFirstEntry());
}
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
从中,我们可以看出 firstEntry() 和 getFirstEntry() 都是用于获取第一个节点。
但是,firstEntry() 是对外接口; getFirstEntry() 是内部接口。而且,firstEntry() 是通过 getFirstEntry() 来实现的。那为什么外界不能直接调用 getFirstEntry(),而需要多此一举的调用 firstEntry() 呢?
先告诉大家原因,再进行详细说明。这么做的目的是:防止用户修改返回的Entry。getFirstEntry()返回的Entry是可以被修改的,但是经过firstEntry()返回的Entry不能被修改,只可以读取Entry的key值和value值。下面我们看看到底是如何实现的。
(01) getFirstEntry()返回的是Entry节点,而Entry是红黑树的节点,它的源码如下:
// 返回“红黑树的第一个节点”
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
从中,我们可以调用Entry的getKey()、getValue()来获取key和value值,以及调用setValue()来修改value的值。
(02) firstEntry()返回的是exportEntry(getFirstEntry())。下面我们看看exportEntry()干了些什么?
static <K,V> Map.Entry<K,V> exportEntry(TreeMap.Entry<K,V> e) {
return e == null? null :
new AbstractMap.SimpleImmutableEntry<K,V>(e);
}
实际上,exportEntry() 是新建一个AbstractMap.SimpleImmutableEntry类型的对象,并返回。
SimpleImmutableEntry的实现在AbstractMap.java中,下面我们看看AbstractMap.SimpleImmutableEntry是如何实现的,代码如下:
View Code
从中,我们可以看出SimpleImmutableEntry实际上是简化的key-value节点。
它只提供了getKey()、getValue()方法类获取节点的值;但不能修改value的值,因为调用 setValue() 会抛出异常UnsupportedOperationException();
再回到我们之前的问题:那为什么外界不能直接调用 getFirstEntry(),而需要多此一举的调用 firstEntry() 呢?
现在我们清晰的了解到:
(01) firstEntry()是对外接口,而getFirstEntry()是内部接口。
(02) 对firstEntry()返回的Entry对象只能进行getKey()、getValue()等读取操作;而对getFirstEntry()返回的对象除了可以进行读取操作之后,还可以通过setValue()修改值。
第3.4部分 TreeMap的key相关函数
TreeMap的firstKey()、lastKey()、lowerKey()、higherKey()、floorKey()、ceilingKey()原理都是类似的;下面以ceilingKey()来进行详细说明
ceilingKey(K key)的作用是“返回大于/等于key的最小的键值对所对应的KEY,没有的话返回null”,它的代码如下:
public K ceilingKey(K key) {
return keyOrNull(getCeilingEntry(key));
}
ceilingKey()是通过getCeilingEntry()实现的。keyOrNull()的代码很简单,它是获取节点的key,没有的话,返回null。
static <K,V> K keyOrNull(TreeMap.Entry<K,V> e) {
return e == null? null : e.key;
}
getCeilingEntry(K key)的作用是“获取TreeMap中大于/等于key的最小的节点,若不存在(即TreeMap中所有节点的键都比key大),就返回null”。它的实现代码如下:
View Code
第3.5部分 TreeMap的values()函数
values() 返回“TreeMap中值的集合”
values()的实现代码如下:
public Collection<V> values() {
Collection<V> vs = values;
return (vs != null) ? vs : (values = new Values());
}
说明:从中,我们可以发现values()是通过 new Values() 来实现 “返回TreeMap中值的集合”。
那么Values()是如何实现的呢? 没错!由于返回的是值的集合,那么Values()肯定返回一个集合;而Values()正好是集合类Value的构造函数。Values继承于AbstractCollection,它的代码如下:
View Code
说明:从中,我们可以知道Values类就是一个集合。而 AbstractCollection 实现了除 size() 和 iterator() 之外的其它函数,因此只需要在Values类中实现这两个函数即可。
size() 的实现非常简单,Values集合中元素的个数=该TreeMap的元素个数。(TreeMap每一个元素都有一个值嘛!)
iterator() 则返回一个迭代器,用于遍历Values。下面,我们一起可以看看iterator()的实现:
public Iterator<V> iterator() {
return new ValueIterator(getFirstEntry());
}
说明: iterator() 是通过ValueIterator() 返回迭代器的,ValueIterator是一个类。代码如下:
final class ValueIterator extends PrivateEntryIterator<V> {
ValueIterator(Entry<K,V> first) {
super(first);
}
public V next() {
return nextEntry().value;
}
}
说明:ValueIterator的代码很简单,它的主要实现应该在它的父类PrivateEntryIterator中。下面我们一起看看PrivateEntryIterator的代码:
View Code
说明:PrivateEntryIterator是一个抽象类,它的实现很简单,只只实现了Iterator的remove()和hasNext()接口,没有实现next()接口。
而我们在ValueIterator中已经实现的next()接口。
至此,我们就了解了iterator()的完整实现了。
第3.6部分 TreeMap的entrySet()函数
entrySet() 返回“键值对集合”。顾名思义,它返回的是一个集合,集合的元素是“键值对”。
下面,我们看看它是如何实现的?entrySet() 的实现代码如下:
public Set<Map.Entry<K,V>> entrySet() {
EntrySet es = entrySet;
return (es != null) ? es : (entrySet = new EntrySet());
}
说明:entrySet()返回的是一个EntrySet对象。
下面我们看看EntrySet的代码:
View Code
说明:
EntrySet是“TreeMap的所有键值对组成的集合”,而且它单位是单个“键值对”。
EntrySet是一个集合,它继承于AbstractSet。而AbstractSet实现了除size() 和 iterator() 之外的其它函数,因此,我们重点了解一下EntrySet的size() 和 iterator() 函数
size() 的实现非常简单,AbstractSet集合中元素的个数=该TreeMap的元素个数。
iterator() 则返回一个迭代器,用于遍历AbstractSet。从上面的源码中,我们可以发现iterator() 是通过EntryIterator实现的;下面我们看看EntryIterator的源码:
final class EntryIterator extends PrivateEntryIterator<Map.Entry<K,V>> {
EntryIterator(Entry<K,V> first) {
super(first);
}
public Map.Entry<K,V> next() {
return nextEntry();
}
}
说明:和Values类一样,EntryIterator也继承于PrivateEntryIterator类。
第3.7部分 TreeMap实现的Cloneable接口
TreeMap实现了Cloneable接口,即实现了clone()方法。
clone()方法的作用很简单,就是克隆一个TreeMap对象并返回。
View Code
第3.8部分 TreeMap实现的Serializable接口
TreeMap实现java.io.Serializable,分别实现了串行读取、写入功能。
串行写入函数是writeObject(),它的作用是将TreeMap的“容量,所有的Entry”都写入到输出流中。
而串行读取函数是readObject(),它的作用是将TreeMap的“容量、所有的Entry”依次读出。
readObject() 和 writeObject() 正好是一对,通过它们,我能实现TreeMap的串行传输。
View Code
说到这里,就顺便说一下“关键字transient”的作用
transient是Java语言的关键字,它被用来表示一个域不是该对象串行化的一部分。
Java的serialization提供了一种持久化对象实例的机制。当持久化对象时,可能有一个特殊的对象数据成员,我们不想用serialization机制来保存它。为了在一个特定对象的一个域上关闭serialization,可以在这个域前加上关键字transient。
当一个对象被串行化的时候,transient型变量的值不包括在串行化的表示中,然而非transient型的变量是被包括进去的。
第3.9部分 TreeMap实现的NavigableMap接口
firstKey()、lastKey()、lowerKey()、higherKey()、ceilingKey()、floorKey();
firstEntry()、 lastEntry()、 lowerEntry()、 higherEntry()、 floorEntry()、 ceilingEntry()、 pollFirstEntry() 、 pollLastEntry();
上面已经讲解过这些API了,下面对其它的API进行说明。
1 反向TreeMap
descendingMap() 的作用是返回当前TreeMap的反向的TreeMap。所谓反向,就是排序顺序和原始的顺序相反。
我们已经知道TreeMap是一颗红黑树,而红黑树是有序的。
TreeMap的排序方式是通过比较器,在创建TreeMap的时候,若指定了比较器,则使用该比较器;否则,就使用Java的默认比较器。
而获取TreeMap的反向TreeMap的原理就是将比较器反向即可!
理解了descendingMap()的反向原理之后,再讲解一下descendingMap()的代码。
// 获取TreeMap的降序Map
public NavigableMap<K, V> descendingMap() {
NavigableMap<K, V> km = descendingMap;
return (km != null) ? km :
(descendingMap = new DescendingSubMap(this,
true, null, true,
true, null, true));
}
从中,我们看出descendingMap()实际上是返回DescendingSubMap类的对象。下面,看看DescendingSubMap的源码:
View Code
从中,我们看出DescendingSubMap是降序的SubMap,它的实现机制是将“SubMap的比较器反转”。
它继承于NavigableSubMap。而NavigableSubMap是一个继承于AbstractMap的抽象类;它包括2个子类——"(升序)AscendingSubMap"和"(降序)DescendingSubMap"。NavigableSubMap为它的两个子类实现了许多公共API。
下面看看NavigableSubMap的源码。
View Code
NavigableSubMap源码很多,但不难理解;读者可以通过源码和注释进行理解。
其实,读完NavigableSubMap的源码后,我们可以得出它的核心思想是:它是一个抽象集合类,为2个子类——"(升序)AscendingSubMap"和"(降序)DescendingSubMap"而服务;因为NavigableSubMap实现了许多公共API。它的最终目的是实现下面的一系列函数:
headMap(K toKey, boolean inclusive) headMap(K toKey) subMap(K fromKey, K toKey) subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) tailMap(K fromKey) tailMap(K fromKey, boolean inclusive) navigableKeySet() descendingKeySet()
第3.10部分 TreeMap其它函数
1 顺序遍历和逆序遍历
TreeMap的顺序遍历和逆序遍历原理非常简单。
由于TreeMap中的元素是从小到大的顺序排列的。因此,顺序遍历,就是从第一个元素开始,逐个向后遍历;而倒序遍历则恰恰相反,它是从最后一个元素开始,逐个往前遍历。
我们可以通过 keyIterator() 和 descendingKeyIterator()来说明!
keyIterator()的作用是返回顺序的KEY的集合,
descendingKeyIterator()的作用是返回逆序的KEY的集合。
keyIterator() 的代码如下:
Iterator<K> keyIterator() {
return new KeyIterator(getFirstEntry());
}
说明:从中我们可以看出keyIterator() 是返回以“第一个节点(getFirstEntry)” 为其实元素的迭代器。
KeyIterator的代码如下:
final class KeyIterator extends PrivateEntryIterator<K> {
KeyIterator(Entry<K,V> first) {
super(first);
}
public K next() {
return nextEntry().key;
}
}
说明:KeyIterator继承于PrivateEntryIterator。当我们通过next()不断获取下一个元素的时候,就是执行的顺序遍历了。
descendingKeyIterator()的代码如下:
Iterator<K> descendingKeyIterator() {
return new DescendingKeyIterator(getLastEntry());
}
说明:从中我们可以看出descendingKeyIterator() 是返回以“最后一个节点(getLastEntry)” 为其实元素的迭代器。
再看看DescendingKeyIterator的代码:
final class DescendingKeyIterator extends PrivateEntryIterator<K> {
DescendingKeyIterator(Entry<K,V> first) {
super(first);
}
public K next() {
return prevEntry().key;
}
}
说明:DescendingKeyIterator继承于PrivateEntryIterator。当我们通过next()不断获取下一个元素的时候,实际上调用的是prevEntry()获取的上一个节点,这样它实际上执行的是逆序遍历了。
至此,TreeMap的相关内容就全部介绍完毕了。若有错误或纰漏的地方,欢迎指正!
第4部分 TreeMap遍历方式
4.1 遍历TreeMap的键值对
第一步:根据entrySet()获取TreeMap的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是TreeMap对象
// map中的key是String类型,value是Integer类型
Integer integ = null;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
}
4.2 遍历TreeMap的键
第一步:根据keySet()获取TreeMap的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是TreeMap对象
// map中的key是String类型,value是Integer类型
String key = null;
Integer integ = null;
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
integ = (Integer)map.get(key);
}
4.3 遍历TreeMap的值
第一步:根据value()获取TreeMap的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是TreeMap对象
// map中的key是String类型,value是Integer类型
Integer value = null;
Collection c = map.values();
Iterator iter= c.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}
TreeMap遍历测试程序如下:
View Code
第5部分 TreeMap示例
下面通过实例来学习如何使用TreeMap
View Code
运行结果:
{one=8, three=4, two=2}
next : one - 8
next : three - 4
next : two - 2
size: 3
contains key two : true
contains key five : false
contains value 0 : false
tmap:{one=8, two=2}
tmap is empty
使用数组实现一个队列,写java代码
public class ArrayQueue <T>
{
private T[] queue;//队列数组
private int head=0;//头下标
private int tail=0;//尾下标
private int count=0;//元素个数
public ArrayQueue()
{
queue=(T[])new Object[10];
this.head=0;//头下标为零
this.tail=0;
this.count=0;
}
public ArrayQueue(int size)
{
queue=(T[])new Object[size];
this.head=0;
this.tail=0;
this.count=0;
}
//入队
public boolean inQueue(T t)
{
if(count==queue.length)
return false;
queue[tail++%(queue.length)]=t;//如果不为空就放入下一个
count++;
return true;
}
//出队
public T outQueue()
{
if(count==0)//如果是空的那就不能再出栈了
return null;
count--;
return queue[head++%(queue.length)];
}
//查队头
public T showHead()
{
if(count==0) return null;
return queue[head];
}
//判满
public boolean isFull()
{
return count==queue.length;
}
//判空
public boolean isEmpty()
{
return count==0;
}
//
}
测试:
public class ArrayQueueTest {
public static void main(String[] args) {
ArrayQueue<Integer> arrayQueue=new ArrayQueue<Integer>(10);
System.out.println("队空?"+arrayQueue.isEmpty());
// for(int i=0;!arrayQueue.isFull();i++)
// {
// arrayQueue.inQueue(i);
// }
for(int i=0;i<=10;i++)
{
System.out.println(arrayQueue.inQueue(i));
}
System.out.println("队满?"+arrayQueue.isFull());
for(int i=0;!arrayQueue.isEmpty();i++)
{
System.out.println(arrayQueue.showHead()+" "+arrayQueue.outQueue());
}
}
}
结果:
队空?true
队满?true
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9