版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/shallcheek/article/details/40210867
这是自己做的一个校园APP里面的一个小模块拿出来分享,有做类似的可以参考 转载请注明出处
我模拟的数据是我们学校的学校图书管理系统:http://222.180.192.5:8989/opac2/open/searchResults.htm?action=simpleSearch
一:抓取搜索列表页面
首先先打开这个网址使用Chrome F12打开调试, 在在输入框输入 ‘php’ 点击搜索 会出现下面的结果与请求数据
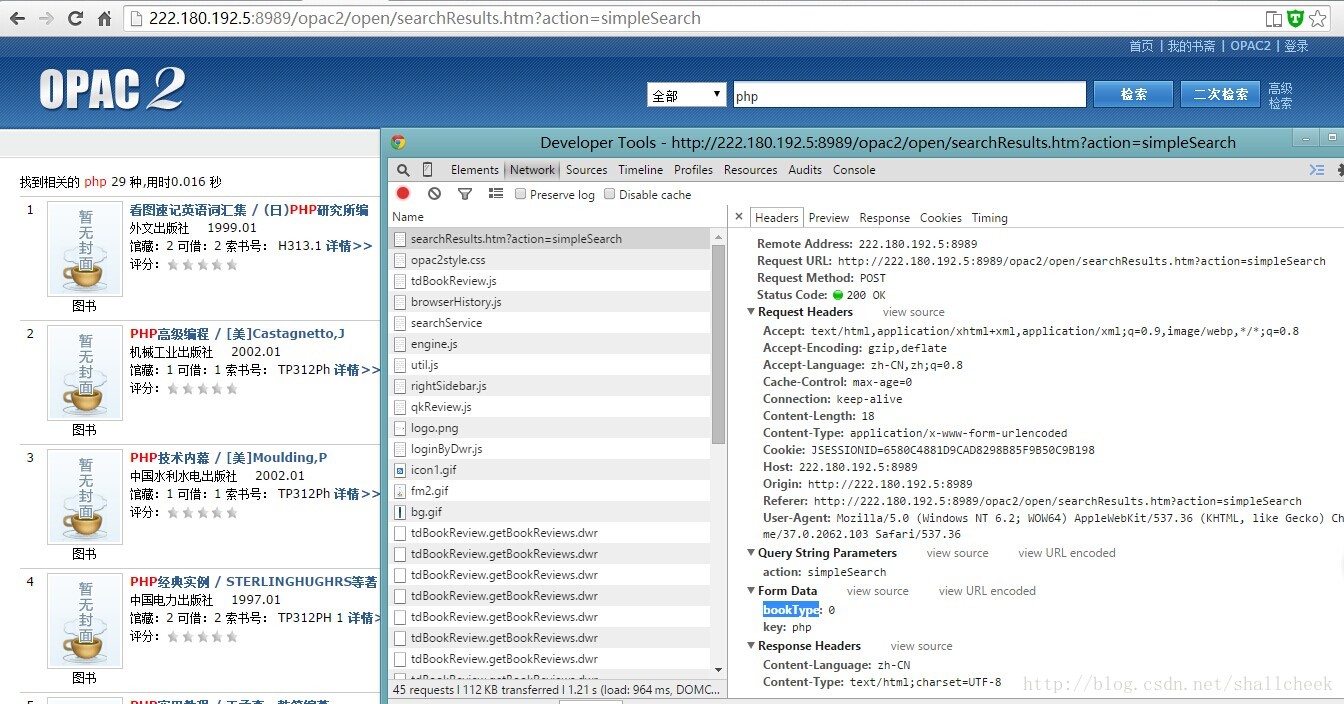
Ps:从调试中结果看是使用的POST请求 提交了两个数据 参数分别是 boolType:0 key:php 但是我点击第二页却是使用的GET所以后面我就用GET模拟搜索
http://222.180.192.5:8989/opac2/open/searchResults.htm?action=simpleSearch&bookType=0&location=&key=php¤tPage=1这样
参数有action=simpleSearch&bookType=0&location=&key=php¤tPage=1 一样的只需要把key=你要搜索的内容 currentPage则是换成你要查看的页数0代表第一以此后推
所以代码有这样就可以模拟搜索出搜索页面了
$str=array(
"action"=>"simpleSearch",
"bookType"=>0,
"key"=>"你要搜索的内容",
"currentPage"=>"你要查看的页面",
"location"=>""
);
$ch = curl_init ( "http://222.180.192.5:8989/opac2/open/searchResults.htm?".http_build_query($str));
$data = curl_exec ( $ch );
echo $data;二:解析搜索页面
上面模拟搜索出来在查看网页源代码进行解析抓取自己需要的数据就可以了 我是使用的正表达式搜索的解析还是很复杂的
查看源代码可可以发现搜索的列表都有一定的规律
<table width="100%" border="0" cellspacing="0" cellpadding="0">
<tr><td class="biaoti">
<!-- 书名 开始 -->
<a href="javascript:void(0)" target= "_blank" onclick="hrefHandler(this, 'http://222.180.192.5:8989/opac2/open/book/bookInfo.htm?bookId=2501329885041996&bookTitle=PHP%2BMySQL%E5%BC%80%E5%8F%91%E5%AE%9E%E4%BE%8B%E6%95%99%E7%A8%8B&bookType=1') " target= "_blank"><FONT COLOR='RED'>PHP</FONT>+MySQL开发实例教程
<!-- 书名 结束 -->
<!-- 作者 开始 -->
/ 丛书编委会
</a>
<!-- 作者 结束 -->
</td></tr>
<tr><td>中国电力出版社 2008.08 </td></tr>
<tr><td></td></tr>
<tr><td>
馆藏:5 可借:5
索书号: TP312PH
<!-- 详情开始 -->
<div id="tip2501329885041996" onmouseover="tipOver();" onmouseout="tipOut();" class="wdk_list_01" style="display:none"></div>
<span class="biaoti" style="cursor:pointer" onmouseout="tipOut();" onmouseover="showTip('2501329885041996');"> 详情>></span>
<!-- 详情结束 -->
</td></tr>
<tr>
<table width="100%" border="0" cellspacing="0" cellpadding="0">开始解析所以有正表达式
检索出所以 tbale的列表
preg_match_all ( '/<table[\w\W]*?width="100%" border="0" cellspacing="0" cellpadding="0">([\w\W]*?)<\/table>/', $data, $m );
显示出来是这样的 是从数组第三个开始的
所以要<table width="100%" border="0" cellspacing="0" cellpadding="0">开始 借宿所以有正表达式
检索出所以 tbale的列表 preg_match_all ( '/<table[\w\W]*?width="100%" border="0" cellspacing="0" cellpadding="0">([\w\W]*?)<\/table>/', $data, $m );
显示出来是这样的 是从数组第三个开始的
所以要

</pre></div><p></p><p>并且数组好耍隔几个就偶数就不是所以需要把数组中的空白去除</p><p></p><pre name="code" class="php"> $i = 1;
unset ( $shuzu [0] );
unset ( $shuzu [1] );
foreach ( $shuzu as $c ) {
$i ++;
if ($i % 2 == 0) {
unset ( $shuzu [$i] );
}
}

就出现大概的了
现在开始真正的解析了
$jsonstr = array ();
foreach ( $shuzu as $a ) {
preg_match_all ( '/<td[\w\W]*?>([\w\W]*?)<\/td>/', $a, $arr );
$tushuname = $arr [1] [0];
str_replace ( " ", "", $tushuname );
preg_match_all ( '#<a.+?onclick="(.+?)".*?>[\w\W]*?(.+?)</a>#', trim ( $tushuname ), $ur );
$name = trim ( strip_tags ( $tushuname ) );
$tushuurl = $ur [1] [0];
preg_match_all ( '/(http)(.)*([a-z0-9\-\.\_])+/i', $tushuurl, $u );
$tushuurl = $u [0] [0];
//提取出出版社
$chubanshe = strip_tags ( $arr [1] [1] );
//其它信息 汇总
$info = trim ( $arr [1] [3] );
$z = explode ( "/", $name );
$name = $z [0];
$zuozhe = $z [1];
$c = explode ( " ", $chubanshe );
$chubanshe = trim($c [0]);
$chubantime = trim($c [1]);
$x = explode ( " ", $info );
$guanchang = $x [0];
$num=explode ( ":", $guanchang );
$guanchang=$num[1];
$kejie = $x[1];
$num=explode ( ":", $kejie );
$k = explode ( ": ", $kejie );
$kejie = trim(substr($num[1], 0,4));
$jiansuo =$k[1];
$jsonstr [] = array (
"title" => ( trim ( $name ) ),
"author" => ( $zuozhe ),
"url" => ( $tushuurl ),
"press" => ( $chubanshe ),
"presstime" => ( $chubantime ),
"collect" => ( $guanchang ),
"kejie" => ( $kejie ),
"jiansuo" => ( trim ( $jiansuo ) ) ,
"result"=>($numstr)
);
}
$ret=( json_encode ( $jsonstr ) ) ;
三,完整代码
<?php
/*
* 分析图书馆搜索界面界面
*/
header ( "Content-type: text/html; charset='utf-8'" );
error_reporting ( 0 );
$data = $_GET;
$name = $data ['name'];
$page = $data ['page'];
$str=array(
"action"=>"simpleSearch",
"bookType"=>0,
"key"=>$name,
"currentPage"=>$page,
"location"=>""
);
httpget ( "http://222.180.192.5:8989/opac2/open/searchResults.htm?", http_build_query($str), "" );
function httpget($url, $postring, $header) {
$ch = curl_init ( $url.$postring);
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $ch, CURLOPT_FOLLOWLOCATION, 1 );
$data = curl_exec ( $ch );
curl_close ( $ch );
preg_match_all ( '/<table[\w\W]*?width="100%" border="0" cellspacing="0" cellpadding="0">([\w\W]*?)<\/table>/', $data, $m );
$shuzu = $m [1];
$i = 1;
unset ( $shuzu [0] );
unset ( $shuzu [1] );
foreach ( $shuzu as $c ) {
$i ++;
if ($i % 2 == 0) {
unset ( $shuzu [$i] );
}
}
$jsonstr = array ();
foreach ( $shuzu as $a ) {
preg_match_all ( '/<td[\w\W]*?>([\w\W]*?)<\/td>/', $a, $arr );
$tushuname = $arr [1] [0];
str_replace ( " ", "", $tushuname );
preg_match_all ( '#<a.+?onclick="(.+?)".*?>[\w\W]*?(.+?)</a>#', trim ( $tushuname ), $ur );
$name = trim ( strip_tags ( $tushuname ) );
$tushuurl = $ur [1] [0];
preg_match_all ( '/(http)(.)*([a-z0-9\-\.\_])+/i', $tushuurl, $u );
$tushuurl = $u [0] [0];
//提取出出版社
$chubanshe = strip_tags ( $arr [1] [1] );
//其它信息 汇总
$info = trim ( $arr [1] [3] );
$z = explode ( "/", $name );
$name = $z [0];
$zuozhe = $z [1];
$c = explode ( " ", $chubanshe );
$chubanshe = trim($c [0]);
$chubantime = trim($c [1]);
$x = explode ( " ", $info );
$guanchang = $x [0];
$num=explode ( ":", $guanchang );
$guanchang=$num[1];
$kejie = $x[1];
$num=explode ( ":", $kejie );
$k = explode ( ": ", $kejie );
$kejie = trim(substr($num[1], 0,4));
$jiansuo =$k[1];
$jsonstr [] = array (
"title" => urlencode( trim ( $name ) ),
"author" => urlencode ( $zuozhe ),
"url" => urlencode( $tushuurl ),
"press" => urlencode ( $chubanshe ),
"presstime" => urlencode ( $chubantime ),
"collect" => urlencode ( $guanchang ),
"kejie" => urlencode ( $kejie ),
"jiansuo" => urlencode( trim ( $jiansuo ) ) ,
"result"=>urlencode($numstr)
);
}
$ret=( json_encode ( $jsonstr ) ) ;
echo urldecode($ret);
}
?>明天在发解析图书的详细信息的吧 第一次写可能写的有点乱,原谅有什么不懂欢迎提问,
转载请注明出处
http://blog.csdn.net/shallcheek/article/details/40210867