Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。
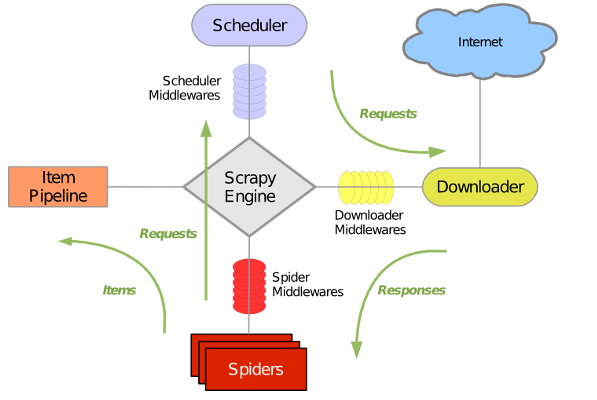
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心)
- 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
创建工程:
scrapy startproject xxx
cd xxx
scrapy genspider (xxxx)meiju (xxxx.com)meijutt.com使用CrawlSpider类改写:
# 创建项目
scrapy startproject TencentSpider
# 进入项目目录下,创建爬虫文件
scrapy genspider -t crawl tencent tencent.com案例:
spider文件:
# -*- coding: utf-8 -*-
import scrapy
from copy import deepcopy
#全站抓取:
class Dy2018Spider(scrapy.Spider):
name = 'dy2018'
allowed_domains = ['dy2018.com']
start_urls = ['https://www.dy2018.com/0/']
def parse(self, response):
href=response.xpath('//*[@class="co_content2"]/ul//td[2]')
for i in href:
item={}
title=i.xpath('./a/text()').extract_first()
item['href'] = 'https://www.dy2018.com'+i.xpath('./a/@href').extract_first()
print(title,item['href'])
yield scrapy.Request(item['href'],callback=self.parse_book_list,meta={"item": deepcopy(item)})
def parse_book_list(self,response):
item = response.meta["item"]
href_list = response.xpath('//*[@class="co_content8"]/ul//a[2]')
for i in href_list:
title = i.xpath('./@title').extract_first()
href_a = 'https://www.dy2018.com' + i.xpath('./@href').extract_first()
#print(title, href_a)
next_page=response.xpath('//*[@class="x"]/p/text()').extract_first().split( )[0].split('/')[1]
for i in range(2,int(next_page)):
next_href = item['href']+'index_{}.html'.format(i)
print(next_href)
yield scrapy.Request(next_href, callback=self.parse_book_list,meta={"item": deepcopy(item)})
pipelines存到MongoDB:
from pymongo import MongoClient
import json
client = MongoClient('localhost',port=27017)
collection = client["jd"]["book1"]
class JdbookPipeline(object):
def process_item(self, item, spider):
collection.insert(dict(item))
return item
class JdbookPipeline1(object):
def process_item(self, item, spider):
with open('temp.txt','a',encoding='utf-8')as f :
f.write(json.dumps(dict(item),ensure_ascii=False,indent=2))
return item
middlewares下载中间件,主要是设置动态Uesr-Agent和代理IP:
import random
from lagou.settings import USER_AGENTS
#https://www.cnblogs.com/huwei934/p/6971426.html
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
request.headers.setdefault("User-Agent", useragent)
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
if proxy['user_passwd'] is None:
# 没有代理账户验证的免费代理的使用
request.meta['proxy'] = "http//" + proxy['ip_port']
else:
request.meta['proxy'] = "http//" + proxy['ip_port']
# 对账户密码进行base64编码转换
base64_userpasswd = base64.b64decode(proxy['user_passwd'])
# 对应到代理服务器的信令格式里
request.headers['Proxy-Authorization'] = 'Basic ' + base64_userpasswdsettings文件:
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52"
]
PROXIES = [
{'ip_port': '111.8.60.9:8123', 'user_passwd': ''},
{'ip_port': '101.71.27.120:80', 'user_passwd': 'user2:pass2'},
{'ip_port': '122.96.59.104:80', 'user_passwd': 'user3:pass3'},
{'ip_port': '122.224.249.122:8088', 'user_passwd': 'user4:pass4'},
]
DOWNLOADER_MIDDLEWARES = { 'douban.middlewares.RandomUserAgent': 100,
'douban.middlewares.RandomProxy': 200, }腾讯招聘CrawlSpider