说到GC, 可能很多人都倾向于使用新潮的G1垃圾收集器, 特别是intel的那几个兄弟在databrick发表了篇用G1调优Spark应用的博文后, 就更多人热衷于尝试G1了.
但其实我们再去年就对G1和老牌的CMS+NewPar进行过对比测试, 发现G1根本没有比CMS好, 有时候还会导致更多的FullGC, 而实际上连Oracle官方都觉得G1还没有production ready. 当然了, 我们是在JDK7上测试的, 而intel的哥们是在那个JDK版本上测试就不得而知了, 可能JDK8对G1的改进会好些吧, 但由于我们几乎所有应用都在用JDK7, 因此也不可能在JDK8上进行测试. 另外, intel的兄弟使用优化过的G1与没优化的CMS进行对比测试, 结果能否采用也是需要谨慎考虑的.
我们还是比较倾向于CMS+NewPar的GC配置, 因此在LinkedIn团队所提供的CMS GC参数的基础上进行了一下修改: ” -server -XX:PermSize=256m -XX:MaxPermSize=256m -XX:NewSize=1536m -XX:MaxNewSize=1536m -XX:SurvivorRatio=8 -XX:+UseParNewGC -XX:MaxTenuringThreshold=31 -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+ParallelRefProcEnabled -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSFullGCsBeforeCompaction=3 -XX:ParallelGCThreads=16 -XX:ConcGCThreads=12 -XX:+ExplicitGCInvokesConcurrent -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses -XX:+AlwaysPreTouch -XX:-OmitStackTraceInFastThrow -XX:+UseCompressedStrings -XX:+UseStringCache -XX:+OptimizeStringConcat -XX:+UseCompressedOops -XX:+CMSScavengeBeforeRemark -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime -verbose:gc -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintHeapAtGC”, 尝试一下后, 发现效果不好, 依然有一些executor容易被YARN NodeManager给kill掉.
猜测原因可能是由于我们各个节点的机子配置过于多样化, 一些高配, 一些低配, 而且节点也会时不时增加和减少. 但是LinkedIn团队的参数是基于他们普遍高配置的节点而调试出来的, JVM HEAP的各个区都可以人为固定, 使用多少线程进行GC和Remark也是可以算出来的, 而同样的方法在我们这儿就不成立了, 这台节点上Eden区可以用2个G, 另一台节点可能剩余内存都没有2个G, 因此, 我们需要去掉一些硬性对JVM HEAP进行手工配置的选项, 也就是变成了这样: "spark.executor.extraJavaOptions= -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+ParallelRefProcEnabled -XX:+CMSClassUnloadingEnabled -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -XX:+HeapDumpOnOutOfMemoryError -verbose:gc ".
同时为了减少进入Old Gen的对象数, 扩大Eden的使用率, 加上了” -XX:MaxTenuringThreshold=31 -XX:SurvivorRatio=8”.
优化后除了executor被kill的情况不在发生外, 连Full GC的影子都看不着.
加大Kafka流入的数据量到每3秒162000条消息, 也就是每秒近6万的消息流入, 与从HDFS加载的2300万条数据进行inner join.
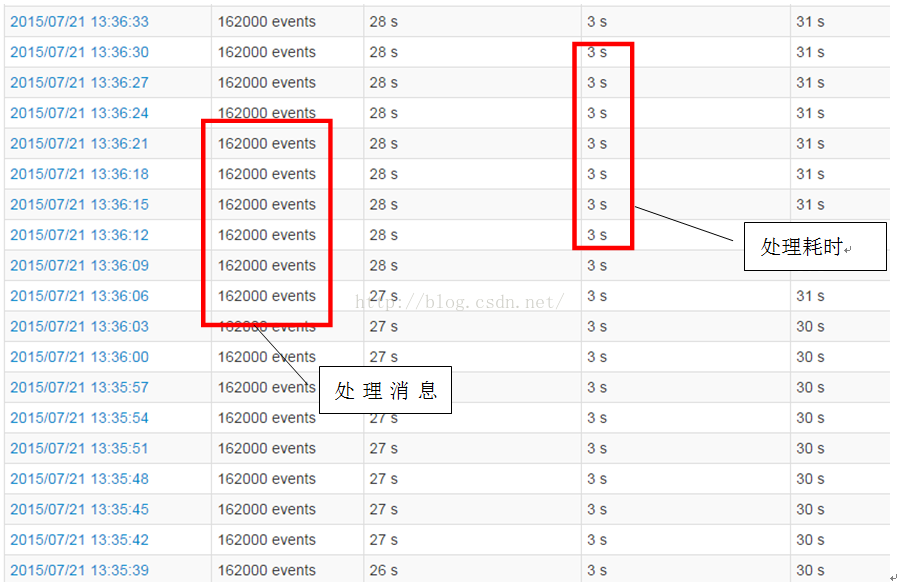
162000条消息都能在规定的3秒内处理完, 也就是每秒处理近 6万 * 2千3百万条记录的inner join.
在加大Kafka流入的数据量到每3秒180000条, 结果如下:
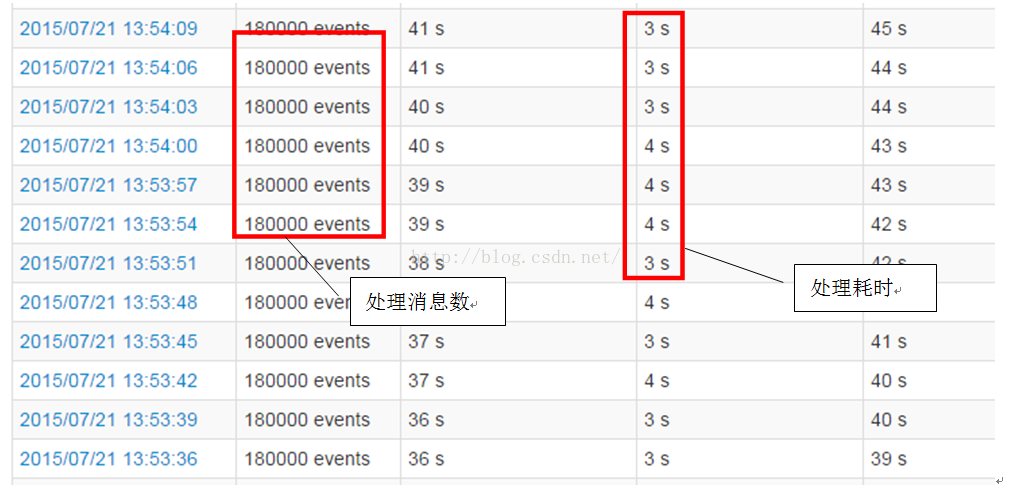
180000条记录大部分能在3s内处理完, 但有一些job需要4秒. 结合上一次测试结果, 也就是该Spark Streaming应用的处理极限大概是在17万到18万条Kafka输入消息之间, 也就是解决 18万 * 2千3百万条记录, 共3G+左右数据的inner join.
下面我们稍微用G1垃圾收集器进行一下对比, 参数是在intel给的G1优化参数的基础上修改的: "spark.executor.extraJavaOptions= -XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:+AlwaysPreTouch -XX:InitiatingHeapOccupancyPercent=30 -XX:ParallelGCThreads=20 -XX:-OmitStackTraceInFastThrow -XX:+UseCompressedStrings -XX:+UseStringCache -XX:+OptimizeStringConcat -XX:+UseCompressedOops -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -verbose:gc ", 结果如下:
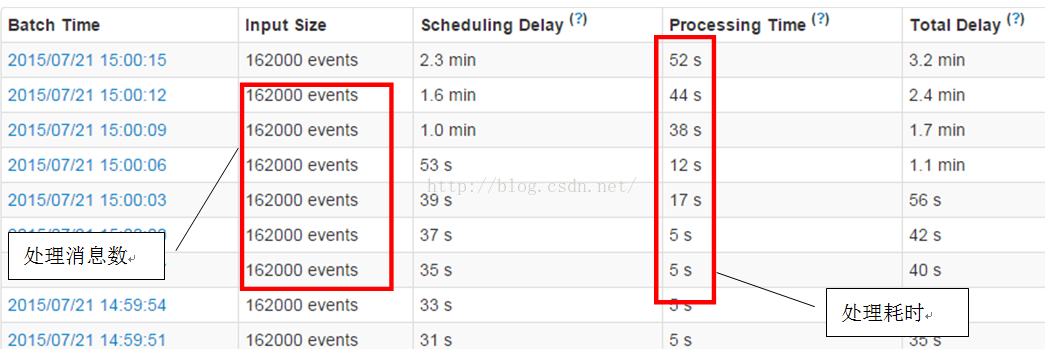
即使对于较少数据的162000条Kafka输入消息, 也出现了几十秒的延迟, 这是无法接收的, 因此在production环境, 还是建议用CMS+NewPar的设置, 并且如果不能保证每台节点的硬件配置一致的话, 最好就不要去人为规定JVM HEAP各个空间的大小以及GC线程的数量.
12. 使用shuffle service和i-CMS GC
其实大家可以看到, 上一节在每3秒处理18万条消息, 每秒处理6万条消息的场景中, 偶尔会出现处理时间超过3秒的情况, 因此我们决定进一步优化, 把shuffle service给用上 进一步加快shuffle阶段的效率和稳定性; 并根据服务器的配置差异巨大的现实情况, 使用i-CMS GC, 此GC能减少Full GC的次数, 适用于无法硬性规定JVM Heap各区大小以及GC发生阈值的情况, 当然, 它会耗费一些CPU时间.
Shuffle Service的安装, 详情请看逛网. 大概的说就是要把spark的shuffle service jar包copy到yarn的lib目录, 然后在yarn的aux service配置中加入该shuffler service. 同时要在Spark应用中配置” spark.shuffle.service.enabled=true”.
而打开i-CMS GC, 则需要在JVM配置中加入” -XX:+CMSIncrementalMode -XX:+CMSIncrementalPacing -XX:CMSIncrementalDutyCycleMin=0 -XX:CMSIncrementalDutyCycle=10”.
本该说这次的测试用了黄金配置, 应该比上一节的测试效果要好, 但任何事情都不能想当然, 结果让我们大跌眼睛, 这次的测试效果与上一节差不多, 但悲惨的是在十几分钟后出现了GC时间超5秒的情况, 发生了executor被kill事件. 通过查看GC日志可知, 在spark应用运行是会出现频繁的同步mark, 这是为了减少Full GC而产生的, 但问题是GC时间却会渐渐的加大, 估计是没有Full GC会导致一些没被Young GC回收的对象造成的积压吧, 这一点上我没有深究, 就先把i-CMS GC撤掉试试吧, 毕竟practice speaks lounder than words.
撤掉i-CMS GC后, 果然效率与稳定性大增, 对18万Kafka消息, 18万 * 2千3百万条记录, 共3G+左右数据的inner join的场景的处理稳定在3秒的处理速度. (木有截图,不好意思啊)