在linux的代码中,经常可以看到这样的写法:
__setup("root=", root_dev_setup);其中__setup为宏,root_dev_setup为函数名,这样的写法是什么意义呢?
查找宏的定义
#define __setup_param(str, unique_id, fn, early) \
static const char __setup_str_##unique_id[] __initconst \
__aligned(1) = str; \
static struct obs_kernel_param __setup_##unique_id \
__used __section(.init.setup) \
__attribute__((aligned((sizeof(long))))) \
= { __setup_str_##unique_id, fn, early }
#define __setup(str, fn) \
__setup_param(str, fn, fn, 0)把宏展开:
static const char __setup_str_root_dev_setup[] __initconst __aligned(1) = "root=";
static struct obs_kernel_param __setup_root_dev_setup __used __section(.init.setup) __attribute__((aligned((sizeof(long)))))
= { __setup_str_root_dev_setup, root_dev_setup, 0 }定义了2个变量:
1)字符串数组__setup_str_root_dev_setup[]
2)结构体struct obs_kernel_param __setup_root_dev_setup
其中结构体类型定义为:
struct obs_kernel_param {
const char *str;
int (*setup_func)(char *);
int early;
};包含一个字符指针,函数指针和一个标记位。
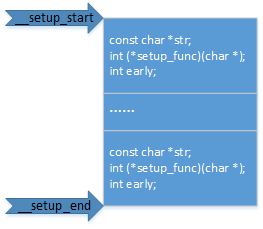
数据__setup_root_dev_setup放置在__section(.init.setup)段,在vmlinux.lds.h中定义:
#define INIT_SETUP(initsetup_align) \
. = ALIGN(initsetup_align); \
__setup_start = .; \
KEEP(*(.init.setup)) \
__setup_end = .;代码中所有使用__setup("XXXX", XXXXX);经过编译后放置在.init.setup段中,构成一个struct obs_kernel_param类型的数组, 同样:
#define early_param(str, fn) __setup_param(str, fn, fn, 1)
同__setup定义的结构提只是字段early初始化的值不同,如下图所示:
在linux的初始化阶段可以通过结构体中的字符指针,查找调用。
1): early options
start_kernel--->setup_arch--->parse_early_parm ---> parse_early_options --->parse_args --->parse_one ---> do_early_param
static int __init do_early_param(char *param, char *val,
const char *unused, void *arg)
{
const struct obs_kernel_param *p;
/*查找字符指针同入参parm相同,且early为1(即early_param宏定义的数据)
或者参数parm为”console”或者宏定义的str为”earlycon”*/
for (p = __setup_start; p < __setup_end; p++) {
if ((p->early && parameq(param, p->str)) ||
(strcmp(param, "console") == 0 &&
strcmp(p->str, "earlycon") == 0)
) {
if (p->setup_func(val) != 0)
pr_warn("Malformed early option '%s'\n", param);
}
}
/* We accept everything at this stage. */
return 0;
}2)booting kernel
start_kernel--->parse_args--->parse_one ---> unknown_bootoption ---> obsolete_checksetup
static bool __init obsolete_checksetup(char *line)
{
const struct obs_kernel_param *p;
bool had_early_param = false;
p = __setup_start;
/*执行参数匹配成功,且标记early为0的函数*/
do {
int n = strlen(p->str);
if (parameqn(line, p->str, n)) {
if (p->early) {
if (line[n] == '\0' || line[n] == '=')
had_early_param = true;
} else if (!p->setup_func) {
pr_warn("Parameter %s is obsolete, ignored\n",
p->str);
return true;
} else if (p->setup_func(line + n))
return true;
}
p++;
} while (p < __setup_end);
return had_early_param;
}
类似还有pure_initcall, __initcall都是一套相同的实现机制,在编码中可以根据业务划分,将代码放入对应的业务模块,在编译阶段将这些代码构造为一个表,可以集中调用或按需查找调用。这很好的体现了linux机制与策略分离的思想,在这里采用了一种编程策略:表驱动法,按照《CODE COMPLETE》的说法:
表驱动法是一种编程策略(scheme)-- 从表里面查找信息而不使用逻辑语句。事实上,凡是能通过逻辑语句来选择的事物,都可以通过查表来选择。简单情况使用逻辑语句更为容易直白。但随着逻辑链越来越复杂,查表就显得更具有吸引力。
查表的方式主要有:
- 直接访问
- 索引访问
- 阶梯访问
直接访问
即直接通过下标,找到要访问的内容,比较常用的场景如,报文处理回调函数。
如定义的报文格式为:
![]()
报文了类型可以用枚举表示:
Enum type{
Type_1,
Type_2.
…
Type_ALL
}定义报文的处理函数:
Int process_type1(int len, char*data)
{
….
}定义表:
Typedef struct tagP_F{
Int int (*setup_func)(int, char *);
}P_F;以报文类型下标为索引
P_F table = {f1, f2};可以直接通过table[Type_1](len, data); 调用对应的报文处理函数。
索引访问
要建立索引表,比直接建立主表要节约内存。
如上面描述的setup宏。
阶梯访问
也称为分段访问,是通过对某表中数据分段,根据分段再进行查找的过程。比较常见的是绩点查询
无论什么编程模式,都只是提供一个思路,而不是特定的模式,要根据实际情况灵活运用,适当调整。对应表驱动法要注意两点:1)如何去访问 以及 2)把什么放在表中。