版权声明:路漫漫其修远兮,吾将上下而求索。 https://blog.csdn.net/Happy_Sunshine_Boy/article/details/85338851
什么是Hive
- 把SQL语句转换成map-reduce任务,并完成数据封装【解释器、编译器、优化器】Hive是大数据生态系统中的数据仓库。
Hive架构
- Hive就是大数据中的数据仓库,擅长处理格式良好的结构化数据。对非结构化并不适合;
- Hive能够把结构良好的数据文件映射成一张关系数据库的表,并提供类似SQL(HQL)的查询功能;
- Hive会把SQL语句转换成MapReduce任务运行;
- 提供ETL的工具;
- Hive运行时,元数据存储在关系型数据库中。
优缺点
- 成本低,入手快
- 不需要学习MapReduce开发
- 不支持实时查询
Hive vs RDBMS
| 比较项 | SQL | HiveQL |
|---|---|---|
| ANSI SQL | 支持 | 不完全支持 |
| 更新 | UPDATE\INSTERT\DELETE | insert OVERWRITE\INTO TABLE |
| 事物 | 支持 | 不支持 |
| 模式 | 写模式 | 读模式 |
| 数据保存 | 块设备,本地文件系统 | HDFS |
| 延时 | 低 | 高 |
| 多表插入 | 不支持 | 支持 |
| 子查询 | 完全支持 | 只能用在Form子句中 |
| 视图 | Updatable | Read-only |
| 可扩展性 | 低 | 高 |
| 数据规模 | 小 | 大 |
| …… | …… | …… |
数据类型
- 原子数据类型(常规数据类型)
- 复杂数据类型
- ARRAY
- MAP
- STRUCT
表
- 托管表(managed table)(内部表)
- 外部表
简单示例
- 登录Hive
su hdfs
hive

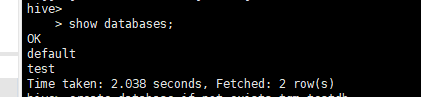
- 查看数据库
show databases;
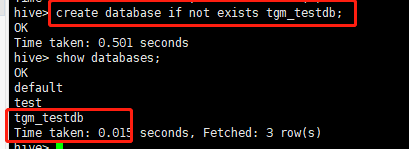
- 创建数据库
create database if not exists databasename;
数据导入
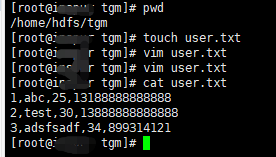
- root用户在/home/hdfs/tgm/目录下创建user.txt文件
cat user.txt
1,abc,25,13188888888888
2,test,30,13888888888888
3,adsfsadf,34,899314121
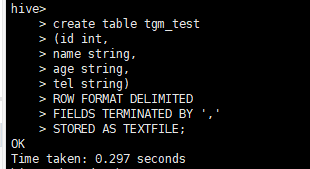
- 在hive中创建数据表
create table tgm_test
(id int,
name string,
age string,
tel string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
- 从本地文件加载
load data local inpath '/home/hdfs/tgm/user.txt' into table tgm_test;

- 从HDFS中文件加载
load data inpath 'user.txt' into table tgm_test;
- 从Hive中另一个表中加载
create table tgm_test2
(id int,
name string,
tel string)
partitioned by (age int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;

insert into table tgm_test2
partition (age='25')
select id, name, tel
from tgm_test;

数据导出
- 导出到本地
insert overwrite local directory '/tmp/test'
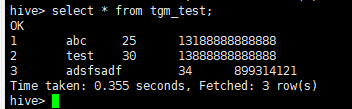
select * from tgm_test;
- 导出到HDFS
insert overwrite directory '/tmp/test'
select * from tgm_test;
- 导出时指定分隔符
insert overwrite local directory '/tmp/test'
row format delimited
fields terminated by ','
select * from tgm_test;