这个blog用来积累设计数据仓库需要考虑的一些问题:
1、 源系统数据调研
也就是所谓的源系统数据,需要怎么调研,调研一些什么呢?
目前认为需要确认业务的流程(其实就是业务流程对应的后台表的关系), 因为应用系统流程变更,最好设置业务流程的文档维护业务知识,作为知识积累
2、在第三范式建模和维度建模之间的选择
目前主流的建模方式是维度建模,三范式建模,实体建模等,这里建议在ods层上添加第三范式建模,结合维度建模形成数据集市。
3、数据模型设计中的取舍
数据模型设计过程中需要考虑的因素很多,很多时候设计的过程是一个取舍的过程。基本不可能满足各个特性指标的最优化。在过程中需要重点考虑以下三点:
- 扩展性:数据模型的稳定性是指相对的稳定性,是指在源系统、业务逻辑变化的时候,能通过少的成本快速扩展模型。第三范式数据仓库建模方法迁采用竖表方法来满足模型的扩展性,缺带来了效率上的一定问题。维度模型方法在数据粒度不发生变化的时候,需要通过修改表结构,扩展字段方法,做模型应对业务的扩展,相对更复杂些。结合GP表添加字段困难的现实,平台要求所有要求宽表预留字段方法,来保证后续的扩展。另外目前的平台中存在的缺点是,源系统添加字段,会引发数据仓库中多个层次的表需要修改,成本较大,后续需要提供一些公用的工具方法进行改进。
- 效能:效能是ETL的效率和存储空间的平衡,同时一些体系化和扩展性的改进也会对单个的ETL效能有一定的牺牲。数据平台在IDL层采用了简单的镜像方法,牺牲存储获取ETL效率的优化和逻辑上的简化。但是一定要杜绝过度使用这种方法,而且必须要有对应的数据生命周期制度,清除无用的历史数据。
- 体系化:体系要求模型在符合业务视角,用户能够方便的从模型中准确找到对应的数据项,并能方便读取。同时,数据仓库又是强调整合过程。数据平台在宽表设计中强调高内聚、低耦合的理念,在物理实现中,将业务关系大,源系统影响差异小的进行整合;业务关系小,源系统影响差异大的进行分而置之。
4、实施方法
软件工程实践普遍提到的方法有瀑布法和迭代法,什么方法是实施阿里数据平台建设。数据平台国际站和中文站分别采用了这两种方法。阿里巴巴数据仓库的现实是业务在前面跑、平台的建设如果采用瀑布法,必须要有更快的速度,赶超业务变化搭建。所以应当采用集中所有优势兵力,集中攻破的方法。而迭代的方法,需要保持人员在相对稳定的情况,理念统一、坚持,通过不断的改进来是做实施,实施周期较长,影响较小,可以及时做适当的调整
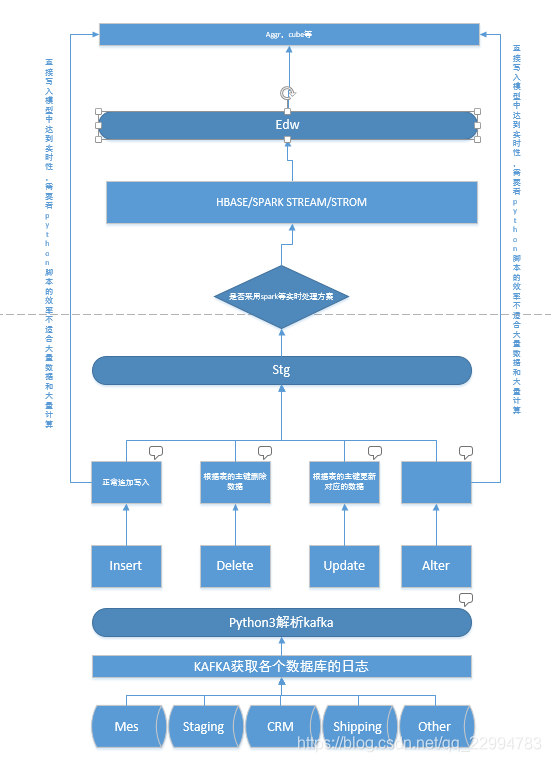
参考:https://www.cnblogs.com/davidwang456/articles/9024021.html
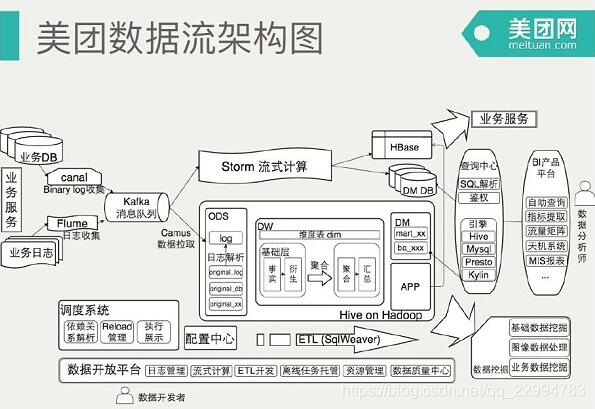
数据平台的建设思想:
第一个是对重复的事情,这一个平台团队做精做专,而且重复的事情只做一次,减少投入。
另外统一化,可以推一些标准,推一些数据管理的模式,减少业务之间的对接成本,这是平台的一大价值。
最重要的是为业务整体效率负责,包括开发效率、迭代效率、维护运维数据流程的效率,还有整个资源利用的效率,这都是要让业务团队对业务团队负责的。无论我们推什么事情,第一时间其实站在业务的角度要考虑他们的业务成本。