线性回归
人们早就知晓,相比凉爽的天气,蟋蟀在较为炎热的天气里鸣叫更为频繁。
数十年来,专业和业余昆虫学者已将每分钟的鸣叫声和温度方面的数据编入目录。
Ruth 阿姨将她喜爱的蟋蟀数据库作为生日礼物送给您,并邀请您自己利用该数据库训练一个模型,从而预测鸣叫声与温度的关系。
首先建议您将数据绘制成图表,了解下数据的分布情况:

图 1. 每分钟的鸣叫声与温度(摄氏度)的关系。
毫无疑问,此曲线图表明温度随着鸣叫声次数的增加而上升。鸣叫声与温度之间的关系是线性关系吗?
是的,您可以绘制一条直线来近似地表示这种关系,如下所示:

图 2. 线性关系。
事实上,虽然该直线并未精确无误地经过每个点,但针对我们拥有的数据,清楚地显示了鸣叫声与温度之间的关系。
只需运用一点代数知识,您就可以将这种关系写下来,如下所示:

按照机器学习的惯例,您需要写一个存在细微差别的模型方程式:

训练与损失
简单来说,训练模型表示通过有标签样本来学习(确定)所有权重和偏差的理想值。
在监督式学习中,机器学习算法通过以下方式构建模型:检查多个样本并尝试找出可最大限度地减少损失的模型;这一过程称为经验风险最小化。
损失是对糟糕预测的惩罚。
也就是说,损失是一个数值,表示对于单个样本而言模型预测的准确程度。
如果模型的预测完全准确,则损失为零,否则损失会较大。
训练模型的目标是从所有样本中找到一组平均损失“较小”的权重和偏差。
例如,图 3 左侧显示的是损失较大的模型,右侧显示的是损失较小的模型(红色箭头表示损失。蓝线表示预测)。

图 3. 左侧模型的损失较大;右侧模型的损失较小。
请注意,左侧曲线图中的红色箭头比右侧曲线图中的对应红色箭头长得多。
显然,相较于左侧曲线图中的蓝线,右侧曲线图中的蓝线代表的是预测效果更好的模型。
您可能想知道自己能否创建一个数学函数(损失函数),以有意义的方式汇总各个损失。
平方损失:一种常见的损失函数

涉及的关键字词
偏差 (bias)
距离原点的截距或偏移。偏差(也称为偏差项)在机器学习模型中用 b 或 w0 表示。
例如,在下面的公式中,偏差为 b:
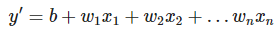
请勿与预测偏差混淆。
权重 (weight)
线性模型中特征的系数,或深度网络中的边。
训练线性模型的目标是确定每个特征的理想权重。
如果权重为 0,则相应的特征对模型来说没有任何贡献。
线性回归 (linear regression)
一种回归模型,通过将输入特征进行线性组合输出连续值。
推断 (inference)
在机器学习中,推断通常指以下过程:通过将训练过的模型应用于无标签样本来做出预测。
在统计学中,推断是指在某些观测数据条件下拟合分布参数的过程。(请参阅维基百科中有关统计学推断的文章。)
经验风险最小化 (ERM, empirical risk minimization)
用于选择可以将基于训练集的损失降至最低的函数。与结构风险最小化相对。
损失 (Loss)
一种衡量指标,用于衡量模型的预测偏离其标签的程度。或者更悲观地说是衡量模型有多差。
要确定此值,模型必须定义损失函数。
例如,线性回归模型通常将均方误差用作损失函数,而逻辑回归模型则使用对数损失函数。
均方误差 (MSE, Mean Squared Error)
每个样本的平均平方损失。MSE 的计算方法是平方损失除以样本数。
TensorFlow Playground 显示的“训练损失”值和“测试损失”值都是 MSE。
平方损失函数 (squared loss)
在线性回归中使用的损失函数(也称为 L2 损失函数)。
该函数可计算模型为有标签样本预测的值和标签的实际值之差的平方。
由于取平方值,因此该损失函数会放大不佳预测的影响。
也就是说,与 L1 损失函数相比,平方损失函数对离群值的反应更强烈。
训练 (training)
确定构成模型的理想参数的过程。
检查理解情况
问题
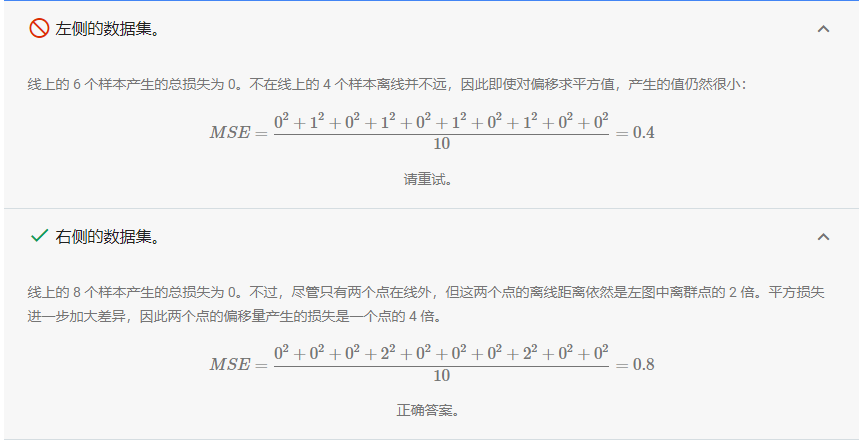
对于以下曲线图中显示的两个数据集,哪个数据集的均方误差 (MSE) 较高?

解答