转自:http://blog.sciencenet.cn/home.php?mod=space&uid=3031432&do=blog&id=1064033
1. NumPy中的N维数组ndarray基本介绍
- NumPy中基本的数据结构
- 所有元素是同一种类型
- 别名array(数组)
- 节省内存,提高CPU计算时间
- 有丰富的函数
注:NumPy的思维模式是面向数组。
2.ndarray数组属性
- 下标从0开始。
- 一个ndarray数组中的所有元素的类型必须相同。
- 轴(axis):每一个线性的数组称为是一个轴,也就是维度(dimensions)。比如,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组,所以一维数组就是ndarray中的轴,第一个轴(也就是第0轴)相当于是底层数组,第二个轴(也就是第1轴)是底层数组里的数组。
很多时候可以声明axis。axis=0,表示沿着第0轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
- 秩(rank):维数,一维数组的秩为1,二维数组的秩为2,以此类推。即轴的个数。
- 基本属性
ndarray1.ndim - 秩
ndarray1.shape - 维度 # 是一个元组,表示数组在每个维度上的大小。比如,一个二维数组,其维度表示“行数”和“列数”。该元组的长度即为秩。
ndarray1.size - 元素总个数 # 等于shape属性中元组元素的乘积。
ndarray1.dtype - 元素类型
ndarray1.itemsize - 元素字节大小 # 即元素所占内存空间大小,例如,元素类型为float64的数组的itemsiz属性值为8(=64/8),元素类型为complex32的数组的itemsize属性为4(=32/8)。
ndarray1.data - 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。
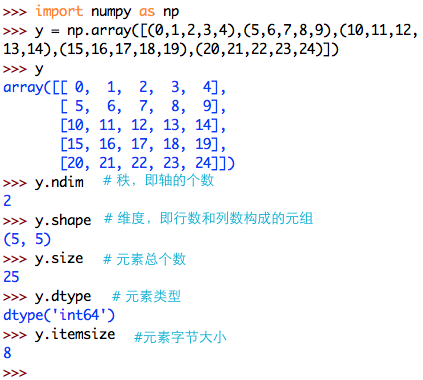
例如:以下5x5的数组,可以看成由5个一维数组构成,每个一维数组包含5个元素;第一维被称为第0轴(列),第二维被称为第1轴(行);秩为2,维度为(5,5),元素总个数为25。

3.如何创建ndarray
3.1从已有数据-——从list、tuple
array() - 创建多维数组。
np.array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0)
object — list或tuple对象。强制参数。
dtype — 数据类型。可选参数。
copy — 默认为True,对象被复制。可选参数。
order — 数组按一定的顺序排列。C - 按行;F - 按列;A - 如果输入为F则按列排列,否则按行排列;K - 保留按行和列排列。默认值为K。可选参数。
subok — 默认为False,返回的数组被强制为基类数组。如果为True,则返回子类。可选参数。
ndmin — 最小维数。可选参数。
注:array函数的参数必须是由方括号括起来的列表,而不能使用多个数值作为参数调用array。
>>> import numpy as np >>> arr1=np.array([[1,2,3],[4.1,5.1,6.1]]) >>> arr1 array([[1. , 2. , 3. ], [4.1, 5.1, 6.1]]) >>> arr2=np.array([(1,2,3),(4.1,5.1,6.1)]) >>> arr2 array([[1. , 2. , 3. ], [4.1, 5.1, 6.1]])
//上述代码中1是由元祖创建,2是由列表创建。
3.2从字符串中读取 - fromstring()
fromstring() - 从字符串中读取数据,并将其转换为一维数组。
np.fromstring(string, dtype=float, count=-1, sep='')
string — 包含数据的字符串。强制参数。
dtype — 数据类型,默认为浮点型。可选参数。
count — 从左到右读取数据的个数。默认为-1,表示读取所有数据。可选参数。
sep — 分隔符。若不指定分隔符,或指定为空,则字符串包含的数据被解译为二进制数据,否则为带有小数的ASCII文本。可选参数。
>>> arr1=np.fromstring('1,2,3,4',dtype=int,sep=',') >>> arr1 array([1, 2, 3, 4]) >>> arr2=np.fromstring('1 2 3 4',dtype=int,sep=' ') >>> arr2 array([1, 2, 3, 4])
3.3从可迭代对象中读取 - fromiter()
fromiter() - 从可迭代对象中读取数据,并将其转换为一维数组。
np.fromiter(iterable, dtype, count=-1)
iterable — 可迭代对象。不能有嵌套。强制参数。
dtype — 数据类型。强制参数。
count — 表示从可迭代对象中读取的项目数。默认为-1,表示读取所有数据。可选参数。
>>> it=(x*x for x in range(5))
>>> it
<generator object <genexpr> at 0x000001B85AB17BA0>
>>> x*x for x in range(5) SyntaxError: invalid syntax >>> np.fromiter(it,float) array([ 0., 1., 4., 9., 16.])
>>> np.fromiter('1234',int) array([1, 2, 3, 4])
>>> np.fromiter('1,2,3,4',int)#这样对于int是不可迭代的 Traceback (most recent call last): File "<pyshell#14>", line 1, in <module> np.fromiter('1,2,3,4',int) ValueError: invalid literal for int() with base 10: ','
>>> np.fromiter((1,2,3,4),float) array([1., 2., 3., 4.])
3.4以函数式创建 - fromfunction()
fromfunction() - 在每个坐标轴上执行函数表达式,用得到的数据创建数组。
np.fromfunction(function, shape, dtype)
function — 可调用的函数。必选参数。
shape — 要创建的数组的维度。其长度与函数参数的个数一致。必选参数。
dtype — 数据类型,默认为浮点型。可选参数。

//这里的x y,我是真的不太理解。为什么就得到这个了?
>>> np.fromfunction(f,(3,3)) (array([[0., 0., 0.], [1., 1., 1.], [2., 2., 2.]]), array([[0., 1., 2.], [0., 1., 2.], [0., 1., 2.]]))