码云仓库地址
代码仓库的地址:https://gitee.com/juzipishui/learn.git
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| ·Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 1930 | 2150 |
| ·Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 900 | 1200 |
| · Design Spec | · 生成设计文档 | 60 | 40 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 480 | 460 |
| · Code Review | · 代码复审 | 60 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| ·Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 90 | 120 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 120 | 10 |
| 合计 | 1930 | 2100 |
因为之前没有从事过这样代码的编写,所以在做上述PSP表格时参考了相关博文(https://www.cnblogs.com/hjf1998/p/9637943.html)以及python教程视频的总课时,并根据自己是零基础者作出了以上的估计。
软件工程学习日志
2018年12月30日至2019年1月1日,进行了编程软件python的学习
2019年1月2日,查看了相关的资料,包括作业要求以及相近似代码的学习
2019年1月4日,开始进行博客的编写,包括最开始的计划
2019年1月5日,进行相关软件的安装以及代码的编写
2019年1月8日,进行代码的编写
2019年1月9日,进行代码编写以及测试
2019年1月10日,进行代码测试以及改进
解题思路描述
分析具体需求
一、基本功能
- 统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
- 统计文件的单词总数,单词:以英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
二、接装封口
在写了一些代码开胃之后,大家都完成了一份满足WordCount基本功能的代码。
大家的代码都各有特色,如果现在我们要把这个功能放到不同的环境中去(例如,命令行,Windows图形界面程序,网页程序,手机App),就会碰到困难:代码散落在各个函数中,很难剥离出来作为一个独立的模块运行以满足不同的需求。
同时我们也看到,不同的代码解决不同层面的问题:
- 有些是计算数据的(例如统计单词)
- 有些是控制输入的(例如scanf,cin,图形界面的输入字段)
- 有些是数据可视化的(例如printf,cout,println,DrawText)
- 有些则更为特殊,是架构相关的(例如main函数,并不是所有的程序都需要某个特定格式的main)
这些代码的种类不同,混杂在一起对于后期的维护扩展很不友好,所以它们的组织结构就需要精心的整理和优化。
我们希望把基本功能里的:
- 统计字符数
- 统计单词数
- 统计最多的10个单词及其词频
这三个功能独立出来,成为一个独立的模块(class library, DLL, 或其它)。这样的话,命令行和GUI的程序都能使用同一份代码。为了方便起见,我们称之为计算核心"Core模块",这个模块至少可以在几个地方使用:
- 命令行测试程序使用
- 在单元测试框架下使用
- 与数据可视化部分结合使用
计算模块接口的设计与实现过程
实现字符计数:
def get_chars(file_name): #统计字符数函数 file = open(file_name) chars_list = [] while(file): chars = file.read() chars_list.extend(chars) if(not chars): break chars_num = 0 for i in chars_list: if ord(i) <= 255 and ord(i) >= 0: chars_num += 1 return chars_num
实现行数计数:
def get_line(file_name): #统计文件的有效行数函数 line_count = 0 file = open(file_name) line = file.readlines() for i in line: line_count+=1 return line_count
实现单词数统计:
def get_words_one(file_name): #得到每个单独的“单词” file = open(file_name) word=[] ascii_list=[] line=[] ascii_list=[] for i in range(33,48,1): ascii_list.append(i) for i in range(58,65,1): ascii_list.append(i) for i in range(91,97,1): ascii_list.append(i) for i in range(123,127,1): ascii_list.append(i) #生成一个非数字字母的ASCII码的列表 while(file): each_line = file.readline() for i in each_line: if ord(i) in ascii_list: each_line=each_line.replace(i,' ') word.extend(each_line.split()) #对每个元素以空格其进行切片 if(not each_line): #假若读取结束 break return word def get_words_two(): word_list=[] word_list_one=get_words_one(file_name) word_list_two=[] word_list_three=[] ascii_list_one=[] for i in word_list_one: if 64 < ord(i[0]) <91 or 96 < ord(i[0]) <123: #挑选出首字符符合要求的“单词” word_list_two.append(i) for i in range(32,127): #生成一个字符的ASCII码的列表 ascii_list_one.append(i) for i in word_list_two: lenth=len(i) for j in range(lenth): if ord(i[j]) not in ascii_list_one: #对含有汉字的单词中的第一个汉字替换为‘+’ i=i.replace(i[j],'+') word_list_three.append(i) break if j == (lenth-1): word_list_three.append(i) for i in word_list_three: if '+' not in i: #删除含有‘+’的“单词” word_list.append(i) return(word_list)
参考代码:https://blog.csdn.net/weixin_32820767/article/details/82314867
实现字频统计及输出前十名:
def word_frequency(): word_list=get_words_two() lower = [item.lower() for item in word_list] #将单词中的字母全部变成小写 dict_one={} #建立一个空词典 count = [] for word in lower:#计算词频 if word in dict_one: dict_one[word]=dict_one[word]+1 else: dict_one[word]=1 for i in sorted(dict_one.items(),key=lambda x:x[1],reverse=True): #按词频进行排序 count.append(i) count.sort() for i in range(min(10,len(count))): print(count[i])
参考代码:https://blog.csdn.net/jiaowosiye/article/details/79209422
计算模块接口部分的性能改进
2018年1月9日,全部代码编辑完成,开始进行测试,测试出现了问题,原代码无法正确对单词数计数,在以切片的方法收集单词时,得到的全是单独的英文字母,无法正确统计单词频率,修改了一晚上,主要集中在对单词数统计的修改,但始终无法的得到正确结果。
尝试改变所用的函数,根据网上的一段代码(https://blog.csdn.net/jiaowosiye/article/details/79209422)进行了修改,具体如下:
a = 0 word def main(): file=open("input.txt",'r') wordCounts={} #先建立一个空的字典,用来存储单词 和相应出现的频次 count=10 #显示前多少条(按照单词出现频次从高到低) for line in file: lineprocess(line.lower(),wordCounts) #对于每一行都进行处理,调用lineprocess()函数,参数就是从file文件读取的一行 items0=list(wordCounts.items()) #把字典中的键值对存成列表,形如:["word":"data"] items=[[x,y] for (y,x) in items0] #将列表中的键值对换一下顺序,方便进行单词频次的排序 就变成了["data":"word"] items.sort() #sort()函数对每个单词出现的频次按从小到大进行排序 print (a) for i in range(len(items)-1,len(items)-count-1,-1): #上一步进行排序之后 对items中的元素从后面开始遍历 也就是先访问频次多的单词 print(items[i][1]+"\t"+str(items[i][0])) def lineprocess(line,wordCounts): for ch in line: #对于每一行中的每一个字符 对于其中的特殊字符需要进行替换操作 if ch in "~@#$%^&*()_-+=<>?/,.:;{}[]|\'""": line=line.replace(ch,"") words=line.split() #替换掉特殊字符以后 对每一行去掉空行操作,也就是每一行实际的单词数量 for word in words: if (ord(word[0])<65) or (90 < ord(word[0]) <97 )or (255>ord(word[0]) > 122): words.remove(word) global a a+=len(words) for word in words: if word in wordCounts: wordCounts[word]+=1 else: wordCounts[word]=1 #这个函数执行完成之后整篇文章里每个单词出现的频次都已经统计好了 main()
这个修改之后的函数已经能够实现正确的单词数统计以及字频的输出,但输出字频不是以字典序输出,太晚了,没有往下继续。
2018年1月10日,昨晚回到床上思考了一下,早上将单词统计函数中的if改为了elif,经老师帮助运行无误,于是在原函数的大框架下继续改进。发现此单词统计函数存在问题,将‘123asdf’这类字符串也进行了统计。然后改变了思路从得到单词列表长度的角度来解决此问题。在课上同学们提出了很多问题,现将截止到今天上课结束未解决的问题总结如下:
1、形如’big大‘字符串如何处理?
2、当文件为空时,或所得到的单词总数小于10时,如何处理?
3、无字符的空行如何处理?
解决思路
尝试了很多次,第一个问题是花费时间最长的问题,最开始的思路如下:
word=['dcd','jds路','jds路'] for i in word: for j in i: if ord(j)>255: word.remove(i) print( word)
但是此方法不能全部筛选干净,而且当形如’big大‘字符串还会出现错误:x not in list,也在网上查找了很多类似问题,加入break后也无法解决。所以改变了思路,与之前得到含有每个单词的列表相类似,将字符串中的第一个汉字用一个符号替换,然后对所有字符串进行遍历,如果含有该符号,则remove该字符串。代码如下:
def get_words_two(): word_list=[] word_list_one=get_words_one(file_name) word_list_two=[] word_list_three=[] ascii_list_one=[] for i in word_list_one: if 64 < ord(i[0]) <91 or 96 < ord(i[0]) <123: #挑选出首字符符合要求的“单词” word_list_two.append(i) for i in range(32,127): #生成一个字符的ASCII码的列表 ascii_list_one.append(i) for i in word_list_two: lenth=len(i) for j in range(lenth): if ord(i[j]) not in ascii_list_one: #对含有汉字的单词中的第一个汉字替换为‘+’ i=i.replace(i[j],'+') word_list_three.append(i) break if j == (lenth-1): word_list_three.append(i) for i in word_list_three: if '+' not in i: #删除含有‘+’的“单词” word_list.append(i) return(word_list)
虽然此方法较为繁琐,但它很好地解决了这个问题。
另外两个问题也得到了解决,第二个问题的解决方法如下:
for i in range(min(10,len(count)))
即取10与列表长度的较小值作为i的取值。
计算模块部分单元测试展示
综合作业要求以及上课同学提出的问题,采用的文本为:
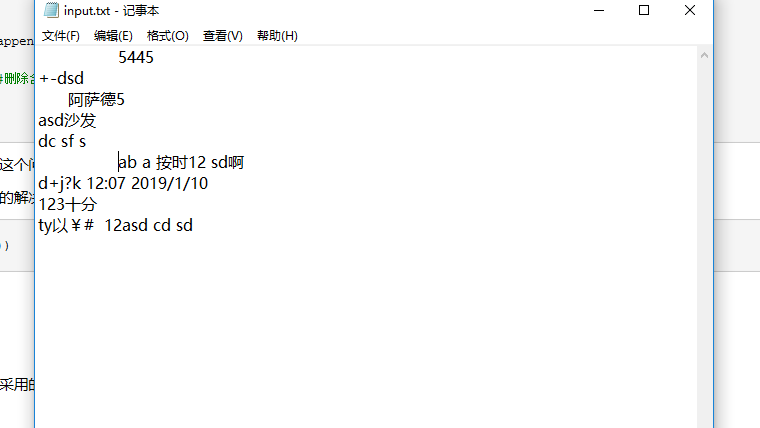
结果为:

计算模块异常说明
本代码对于所要求的功能暂时未发现异常情况。