文章目录
需求说明
- 今天到现在为止实战课程的访问量
- 今天到现在为止从搜索引擎引流过来的实战课程访问量
用户行为日志介绍
用户行为日志:用户每次访问网站时所有的行为数据(访问、浏览、搜索、点击…)
用户行为轨迹、流量日志
典型的日志来源于Nginx和Ajax
日志数据内容:
1)访问的系统属性: 操作系统、浏览器等等
2)访问特征:点击的url、从哪个url跳转过来的(referer)、页面上的停留时间等
3)访问信息:session_id、访问ip(访问城市)等
Python日志产生器服务器测试并将日志写入到文件中
generate_log.py
#coding=UTF-8
import random
import time
url_paths = [
"class/112.html",
"class/128.html",
"class/145.html",
"class/146.html",
"class/131.html",
"class/130.html",
"learn/821",
"course/list"
]
ip_slices = [132,156,124,10,29,167,143,187,30,46,55,63,72,87,98,168]
http_referers = [
"http://www.baidu.com/s?wd={query}",
"https://www.sogou.com/web?query={query}",
"http://cn.bing.com/search?q={query}",
"https://search.yahoo.com/search?p={query}",
]
search_keyword = [
"Spark SQL实战",
"Hadoop基础",
"Storm实战",
"Spark Streaming实战",
"大数据面试"
]
status_codes = ["200","404","500"]
def sample_url():
return random.sample(url_paths, 1)[0]
def sample_ip():
slice = random.sample(ip_slices , 4)
return ".".join([str(item) for item in slice])
def sample_referer():
if random.uniform(0, 1) > 0.2:
return "-"
refer_str = random.sample(http_referers, 1)
query_str = random.sample(search_keyword, 1)
return refer_str[0].format(query=query_str[0])
def sample_status_code():
return random.sample(status_codes, 1)[0]
def generate_log(count = 10):
time_str = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
f = open("/home/hadoop/data/project/logs/access.log","w+")
while count >= 1:
query_log = "{ip}\t{local_time}\t\"GET /{url} HTTP/1.1\"\t{status_code}\t{referer}".format(url=sample_url(), ip=sample_ip(), referer=sample_referer(), status_code=sample_status_code(),local_time=time_str)
f.write(query_log + "\n")
count = count - 1
if __name__ == '__main__':
generate_log(100)
生成的日志
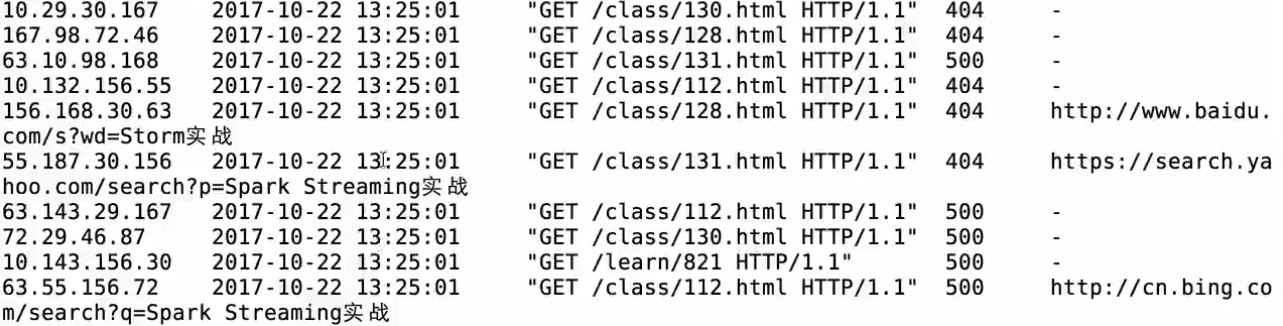
定时执行日志生成器:
linux crontab
网站:http://tool.lu/crontab
每一分钟执行一次的crontab表达式: */1 * * * *
log_generator.sh
python ****/generate_log.py
crontab -e
*/1 * * * * /home/hadoop/data/project/log_generator.sh
打通Flume&Kafka&Spark Streaming线路
使用Flume实时收集日志信息
对接python日志产生器输出的日志到Flume
streaming_project.conf
选型:access.log ==> 控制台输出
exec
memory
logger
exec-memory-logger.sources = exec-source
exec-memory-logger.sinks = logger-sink
exec-memory-logger.channels = memory-channel
exec-memory-logger.sources.exec-source.type = exec
exec-memory-logger.sources.exec-source.command = tail -F /home/hadoop/data/project/logs/access.log
exec-memory-logger.sources.exec-source.shell = /bin/sh -c
exec-memory-logger.channels.memory-channel.type = memory
exec-memory-logger.sinks.logger-sink.type = logger
exec-memory-logger.sources.exec-source.channels = memory-channel
exec-memory-logger.sinks.logger-sink.channel = memory-channel
启动flume测试
flume-ng agent \
--name exec-memory-logger \
--conf $FLUME_HOME/conf \
--conf-file /home/hadoop/data/project/streaming_project.conf \
-Dflume.root.logger=INFO,console
Flume对接kafka
日志==>Flume==>Kafka
启动zk:./zkServer.sh start
启动Kafka Server:
kafka-server-start.sh -daemon /home/hadoop/app/kafka_2.11-0.9.0.0/config/server.properties
修改Flume配置文件使得flume sink数据到Kafka
streaming_project2.conf
exec-memory-kafka.sources = exec-source
exec-memory-kafka.sinks = kafka-sink
exec-memory-kafka.channels = memory-channel
exec-memory-kafka.sources.exec-source.type = exec
exec-memory-kafka.sources.exec-source.command = tail -F /home/hadoop/data/project/logs/access.log
exec-memory-kafka.sources.exec-source.shell = /bin/sh -c
exec-memory-kafka.channels.memory-channel.type = memory
exec-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
exec-memory-kafka.sinks.kafka-sink.brokerList = hadoop000:9092
exec-memory-kafka.sinks.kafka-sink.topic = streamingtopic
exec-memory-kafka.sinks.kafka-sink.batchSize = 5
exec-memory-kafka.sinks.kafka-sink.requiredAcks = 1
exec-memory-kafka.sources.exec-source.channels = memory-channel
exec-memory-kafka.sinks.kafka-sink.channel = memory-channel
启动flume
flume-ng agent \
--name exec-memory-kafka \
--conf $FLUME_HOME/conf \
--conf-file /home/hadoop/data/project/streaming_project2.conf \
-Dflume.root.logger=INFO,console
启动kafka消费者查看日志是否正常
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic streamingtopic
Spark Streaming对接Kafka的数据进行消费
需求开发分析
功能1:今天到现在为止 实战课程 的访问量
yyyyMMdd courseid
使用数据库来进行存储我们的统计结果
Spark Streaming把统计结果写入到数据库里面
可视化前端根据:yyyyMMdd courseid 把数据库里面的统计结果展示出来
选择什么数据库作为统计结果的存储呢?
RDBMS: MySQL、Oracle...
day course_id click_count
20171111 1 10
20171111 2 10
下一个批次数据进来以后:(本操作比较麻烦)
20171111 (day)+ 1 (course_id ) ==> click_count + 下一个批次的统计结果 ==> 写入到数据库中
NoSQL: HBase、Redis....
HBase: 一个API就能搞定,非常方便(推荐)
20171111 + 1 ==> click_count + 下一个批次的统计结果
本次课程为什么要选择HBase的一个原因所在
前提需要启动:
HDFS
Zookeeper
HBase
HBase表设计
创建表
create 'imooc_course_clickcount', 'info'
Rowkey设计
day_courseid
思考:如何使用Scala来操作HBase
功能二:功能一+从搜索引擎引流过来的
HBase表设计
create 'imooc_course_search_clickcount','info'
rowkey设计:也是根据我们的业务需求来的
20171111 +search+ 1
在Spark应用程序接收到数据并完成相关需求
相关maven依赖已经在前面的文章中给出过
时间工具类:
package com.imooc.spark.project.utils
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
/**
* 日期时间工具类
*/
object DateUtils {
val YYYYMMDDHHMMSS_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
val TARGE_FORMAT = FastDateFormat.getInstance("yyyyMMddHHmmss")
def getTime(time: String) = {
YYYYMMDDHHMMSS_FORMAT.parse(time).getTime
}
def parseToMinute(time :String) = {
TARGE_FORMAT.format(new Date(getTime(time)))
}
def main(args: Array[String]): Unit = {
println(parseToMinute("2017-10-22 14:46:01"))
}
}
java编写的hbase工具类
package com.imooc.spark.project.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* HBase操作工具类:Java工具类建议采用单例模式封装
*/
public class HBaseUtils {
HBaseAdmin admin = null;
Configuration configuration = null;
/**
* 私有改造方法
*/
private HBaseUtils(){
configuration = new Configuration();
configuration.set("hbase.zookeeper.quorum", "hadoop000:2181");
configuration.set("hbase.rootdir", "hdfs://hadoop000:8020/hbase");
try {
admin = new HBaseAdmin(configuration);
} catch (IOException e) {
e.printStackTrace();
}
}
private static HBaseUtils instance = null;
public static synchronized HBaseUtils getInstance() {
if(null == instance) {
instance = new HBaseUtils();
}
return instance;
}
/**
* 根据表名获取到HTable实例
*/
public HTable getTable(String tableName) {
HTable table = null;
try {
table = new HTable(configuration, tableName);
} catch (IOException e) {
e.printStackTrace();
}
return table;
}
/**
* 添加一条记录到HBase表
* @param tableName HBase表名
* @param rowkey HBase表的rowkey
* @param cf HBase表的columnfamily
* @param column HBase表的列
* @param value 写入HBase表的值
*/
public void put(String tableName, String rowkey, String cf, String column, String value) {
HTable table = getTable(tableName);
Put put = new Put(Bytes.toBytes(rowkey));
put.add(Bytes.toBytes(cf), Bytes.toBytes(column), Bytes.toBytes(value));
try {
table.put(put);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
//HTable table = HBaseUtils.getInstance().getTable("imooc_course_clickcount");
//System.out.println(table.getName().getNameAsString());
String tableName = "imooc_course_clickcount" ;
String rowkey = "20171111_88";
String cf = "info" ;
String column = "click_count";
String value = "2";
HBaseUtils.getInstance().put(tableName, rowkey, cf, column, value);
}
}
domain相关实体类
package com.imooc.spark.project.domain
/**
* 清洗后的日志信息
* @param ip 日志访问的ip地址
* @param time 日志访问的时间
* @param courseId 日志访问的实战课程编号
* @param statusCode 日志访问的状态码
* @param referer 日志访问的referer
*/
case class ClickLog(ip:String, time:String, courseId:Int, statusCode:Int, referer:String)
package com.imooc.spark.project.domain
/**
* 实战课程点击数实体类
* @param day_course 对应的就是HBase中的rowkey,20171111_1
* @param click_count 对应的20171111_1的访问总数
*/
case class CourseClickCount(day_course:String, click_count:Long)
package com.imooc.spark.project.domain
/**
* 从搜索引擎过来的实战课程点击数实体类
* @param day_search_course
* @param click_count
*/
case class CourseSearchClickCount(day_search_course:String, click_count:Long)
两需求的dao类
package com.imooc.spark.project.dao
import com.imooc.spark.project.domain.CourseClickCount
import com.imooc.spark.project.utils.HBaseUtils
import org.apache.hadoop.hbase.client.Get
import org.apache.hadoop.hbase.util.Bytes
import scala.collection.mutable.ListBuffer
/**
* 实战课程点击数-数据访问层
*/
object CourseClickCountDAO {
val tableName = "imooc_course_clickcount"
val cf = "info"
val qualifer = "click_count"
/**
* 保存数据到HBase
* @param list CourseClickCount集合
*/
def save(list: ListBuffer[CourseClickCount]): Unit = {
val table = HBaseUtils.getInstance().getTable(tableName)
for(ele <- list) {
table.incrementColumnValue(Bytes.toBytes(ele.day_course),
Bytes.toBytes(cf),
Bytes.toBytes(qualifer),
ele.click_count)
}
}
/**
* 根据rowkey查询值
*/
def count(day_course: String):Long = {
val table = HBaseUtils.getInstance().getTable(tableName)
val get = new Get(Bytes.toBytes(day_course))
val value = table.get(get).getValue(cf.getBytes, qualifer.getBytes)
if(value == null) {
0L
}else{
Bytes.toLong(value)
}
}
def main(args: Array[String]): Unit = {
val list = new ListBuffer[CourseClickCount]
list.append(CourseClickCount("20171111_8",8))
list.append(CourseClickCount("20171111_9",9))
list.append(CourseClickCount("20171111_1",100))
save(list)
println(count("20171111_8") + " : " + count("20171111_9")+ " : " + count("20171111_1"))
}
}
package com.imooc.spark.project.dao
import com.imooc.spark.project.domain.{CourseClickCount, CourseSearchClickCount}
import com.imooc.spark.project.utils.HBaseUtils
import org.apache.hadoop.hbase.client.Get
import org.apache.hadoop.hbase.util.Bytes
import scala.collection.mutable.ListBuffer
/**
* 从搜索引擎过来的实战课程点击数-数据访问层
*/
object CourseSearchClickCountDAO {
val tableName = "imooc_course_search_clickcount"
val cf = "info"
val qualifer = "click_count"
/**
* 保存数据到HBase
*
* @param list CourseSearchClickCount集合
*/
def save(list: ListBuffer[CourseSearchClickCount]): Unit = {
val table = HBaseUtils.getInstance().getTable(tableName)
for(ele <- list) {
table.incrementColumnValue(Bytes.toBytes(ele.day_search_course),
Bytes.toBytes(cf),
Bytes.toBytes(qualifer),
ele.click_count)
}
}
/**
* 根据rowkey查询值
*/
def count(day_search_course: String):Long = {
val table = HBaseUtils.getInstance().getTable(tableName)
val get = new Get(Bytes.toBytes(day_search_course))
val value = table.get(get).getValue(cf.getBytes, qualifer.getBytes)
if(value == null) {
0L
}else{
Bytes.toLong(value)
}
}
def main(args: Array[String]): Unit = {
val list = new ListBuffer[CourseSearchClickCount]
list.append(CourseSearchClickCount("20171111_www.baidu.com_8",8))
list.append(CourseSearchClickCount("20171111_cn.bing.com_9",9))
save(list)
println(count("20171111_www.baidu.com_8") + " : " + count("20171111_cn.bing.com_9"))
}
}
使用Spark Streaming处理Kafka过来的数据
package com.imooc.spark.project.spark
import com.imooc.spark.project.dao.{CourseClickCountDAO, CourseSearchClickCountDAO}
import com.imooc.spark.project.domain.{ClickLog, CourseClickCount, CourseSearchClickCount}
import com.imooc.spark.project.utils.DateUtils
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
/**
* 使用Spark Streaming处理Kafka过来的数据
*/
object ImoocStatStreamingApp {
def main(args: Array[String]): Unit = {
if (args.length != 4) {
println("Usage: ImoocStatStreamingApp <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, groupId, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("ImoocStatStreamingApp") //.setMaster("local[5]")
val ssc = new StreamingContext(sparkConf, Seconds(60))
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val messages = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap)
// 测试步骤一:测试数据接收
//messages.map(_._2).count().print
// 测试步骤二:数据清洗
val logs = messages.map(_._2)
val cleanData = logs.map(line => {
val infos = line.split("\t")
// infos(2) = "GET /class/130.html HTTP/1.1"
// url = /class/130.html
val url = infos(2).split(" ")(1)
var courseId = 0
// 把实战课程的课程编号拿到了
if (url.startsWith("/class")) {
val courseIdHTML = url.split("/")(2)
courseId = courseIdHTML.substring(0, courseIdHTML.lastIndexOf(".")).toInt
}
ClickLog(infos(0), DateUtils.parseToMinute(infos(1)), courseId, infos(3).toInt, infos(4))
}).filter(clicklog => clicklog.courseId != 0)
// cleanData.print()
数据清洗操作:从原始日志中取出我们所需要的字段信息就可以了
/*
数据清洗结果类似如下:
ClickLog(46.30.10.167,20171022151701,128,200,-)
ClickLog(143.132.168.72,20171022151701,131,404,-)
ClickLog(10.55.168.87,20171022151701,131,500,-)
ClickLog(10.124.168.29,20171022151701,128,404,-)
ClickLog(98.30.87.143,20171022151701,131,404,-)
ClickLog(55.10.29.132,20171022151701,146,404,http://www.baidu.com/s?wd=Storm实战)
ClickLog(10.87.55.30,20171022151701,130,200,http://www.baidu.com/s?wd=Hadoop基础)
ClickLog(156.98.29.30,20171022151701,146,500,https://www.sogou.com/web?query=大数据面试)
ClickLog(10.72.87.124,20171022151801,146,500,-)
ClickLog(72.124.167.156,20171022151801,112,404,-)
到数据清洗完为止,日志中只包含了实战课程的日志
补充一点:机器配置不要太低
Hadoop/ZK/HBase/Spark Streaming/Flume/Kafka==》: 8Core 8G
*/
// 测试步骤三:统计今天到现在为止实战课程的访问量
cleanData.map(x => {
// HBase rowkey设计: 20171111_88
(x.time.substring(0, 8) + "_" + x.courseId, 1)
}).reduceByKey(_ + _).foreachRDD(rdd => {
rdd.foreachPartition(partitionRecords => {
val list = new ListBuffer[CourseClickCount]
partitionRecords.foreach(pair => {
list.append(CourseClickCount(pair._1, pair._2))
})
CourseClickCountDAO.save(list)
})
})
// 测试步骤四:统计从搜索引擎过来的今天到现在为止实战课程的访问量
cleanData.map(x => {
/**
* https://www.sogou.com/web?query=Spark SQL实战
*
* ==>
*
* https:/www.sogou.com/web?query=Spark SQL实战
*/
val referer = x.referer.replaceAll("//", "/")
val splits = referer.split("/")
var host = ""
if(splits.length > 2) {
host = splits(1)
}
(host, x.courseId, x.time)
}).filter(_._1 != "").map(x => {
(x._3.substring(0,8) + "_" + x._1 + "_" + x._2 , 1)
}).reduceByKey(_ + _).foreachRDD(rdd => {
rdd.foreachPartition(partitionRecords => {
val list = new ListBuffer[CourseSearchClickCount]
partitionRecords.foreach(pair => {
list.append(CourseSearchClickCount(pair._1, pair._2))
})
CourseSearchClickCountDAO.save(list)
})
})
ssc.start()
ssc.awaitTermination()
}
}
运行项目
在本地运行
本地测试的时候直接运行ImoocStatStreamingApp 类即可;然后查看hbase里的数据是否有变化
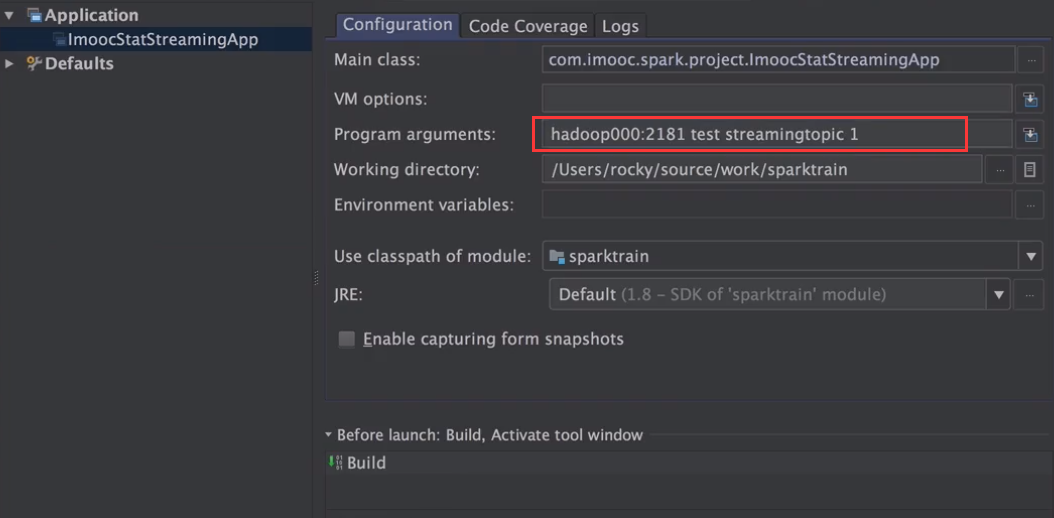
在服务器运行
项目打包:mvn clean package -DskipTests
报错:
[ERROR] /Users/rocky/source/work/sparktrain/src/main/scala/com/imooc/spark/project/dao/CourseClickCountDAO.scala:4: error: object HBaseUtils is not a member
of package com.imooc.spark.project.utils
因为java和scala代码一块打包会报错
需要注释bulid里的以下代码即可
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
将jar包传到服务器
spark-submit --master local[5] \
--class com.imooc.spark.project.spark.ImoocStatStreamingApp \
/home/hadoop/lib/sparktrain-1.0.jar \
hadoop000:2181 test streamingtopic 1
报错的解决
报错:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils$
at com.imooc.spark.project.spark.ImoocStatStreamingApp$.main(ImoocStatStreamingApp.scala:31)
at com.imooc.spark.project.spark.ImoocStatStreamingApp.main(ImoocStatStreamingApp.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:755)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:119)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.kafka.KafkaUtils$
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 11 more
因为打包的时候没有打进去;使用--packages加上额外jar包(服务器需要联网)
spark-submit --master local[5] \
--class com.imooc.spark.project.spark.ImoocStatStreamingApp \
--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 \
/home/hadoop/lib/sparktrain-1.0.jar \
hadoop000:2181 test streamingtopic 1
java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/client/HBaseAdmin
at com.imooc.spark.project.utils.HBaseUtils.<init>(HBaseUtils.java:30)
at com.imooc.spark.project.utils.HBaseUtils.getInstance(HBaseUtils.java:40)
at com.imooc.spark.project.dao.CourseClickCountDAO$.save(CourseClickCountDAO.scala:26)
at com.imooc.spark.project.spark.ImoocStatStreamingApp$$anonfun$main$4$$anonfun$apply$1.a
因为打包的时候没有打进去;使用--jars加上额外本地jar包(服务器不需要联网)
spark-submit --master local[5] \
--jars $(echo /home/hadoop/app/hbase-1.2.0-cdh5.7.0/lib/*.jar | tr ' ' ',') \
--class com.imooc.spark.project.spark.ImoocStatStreamingApp \
--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 \
/home/hadoop/lib/sparktrain-1.0.jar \
hadoop000:2181 test streamingtopic 1
提交作业时,注意事项:
1)--packages的使用
2)--jars的使用
可视化实战
构建Spring Boot项目
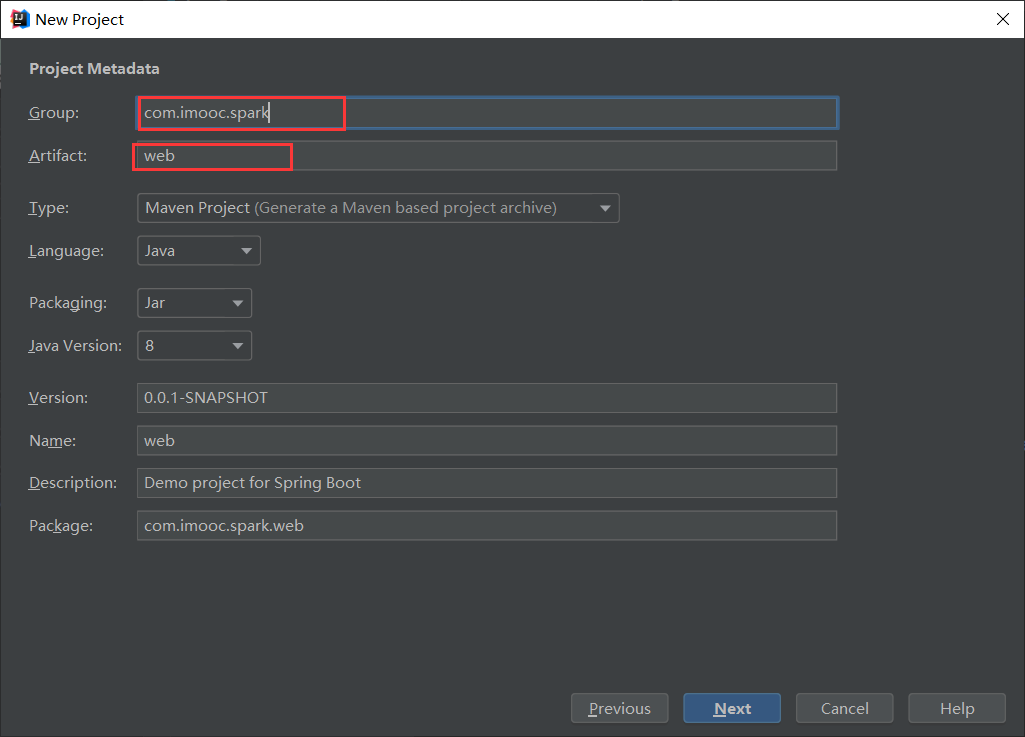
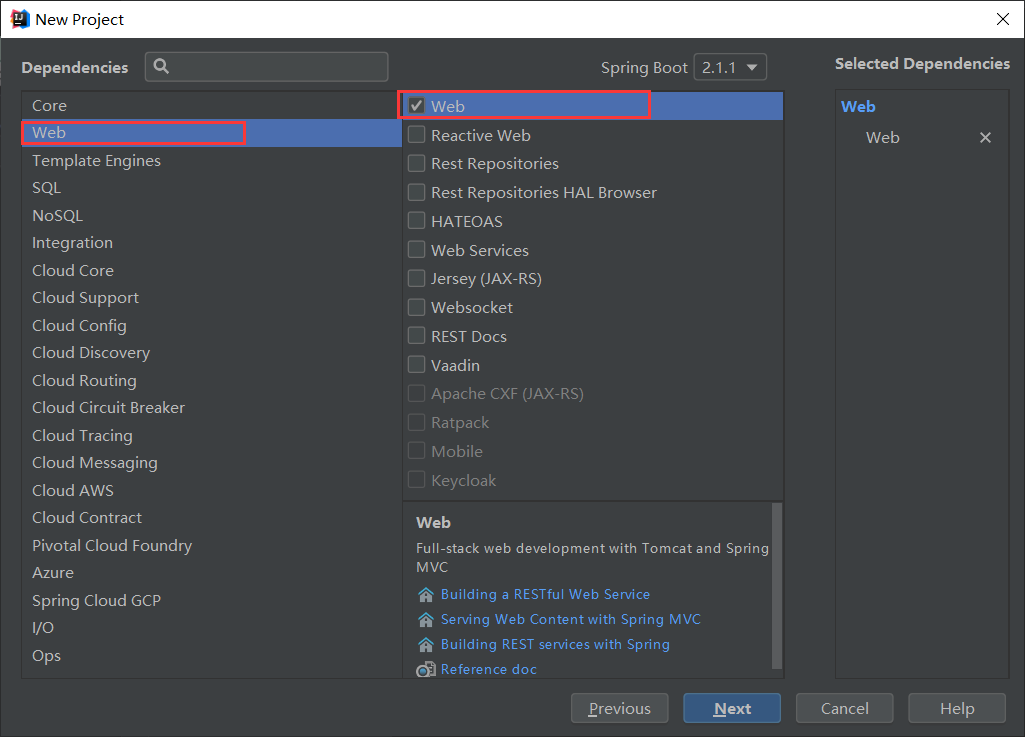
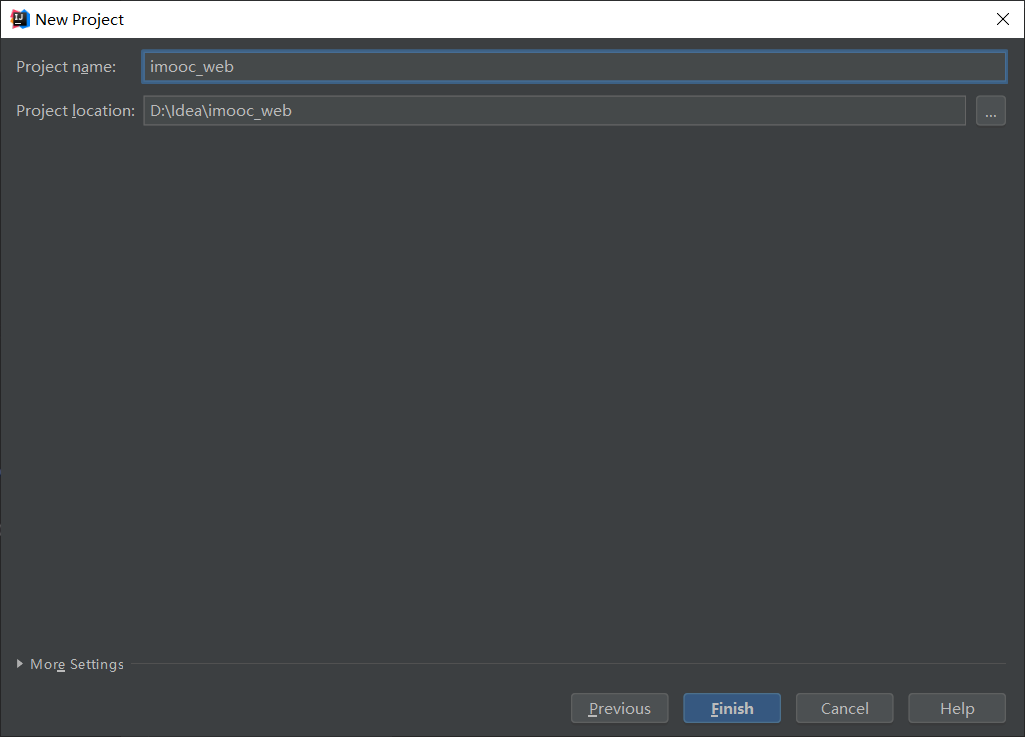
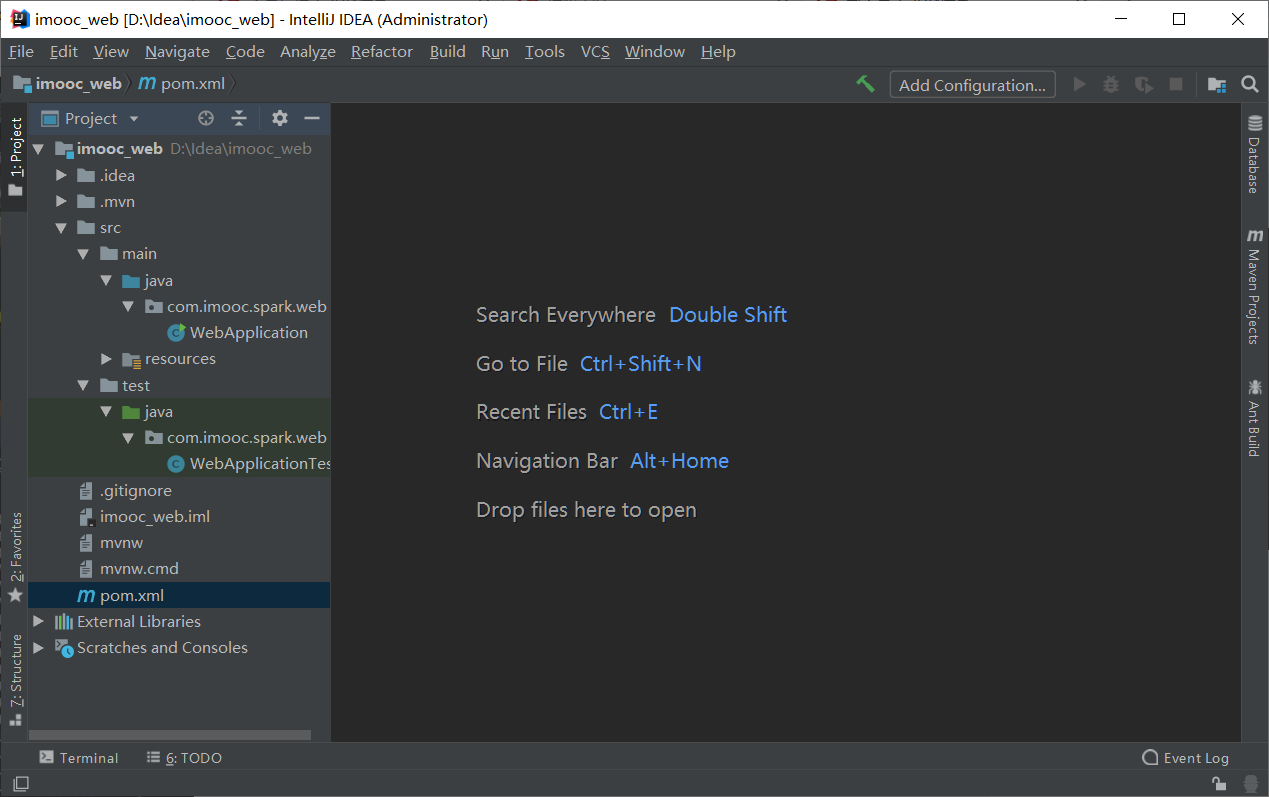
所需mvaen依赖
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.7.0</version>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
</dependencies>
application.properties配置文件
server.port=9999
server.context-path=/imooc
package com.imooc.spark;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.servlet.ModelAndView;
/**
* 这是我们的第一个Boot应用
*/
@RestController
public class HelloBoot {
@RequestMapping(value = "/hello", method = RequestMethod.GET)
public String sayHello() {
return "Hello World Spring Boot...";
}
}
访问 http://localhost:9999/imooc/hello 进行测试
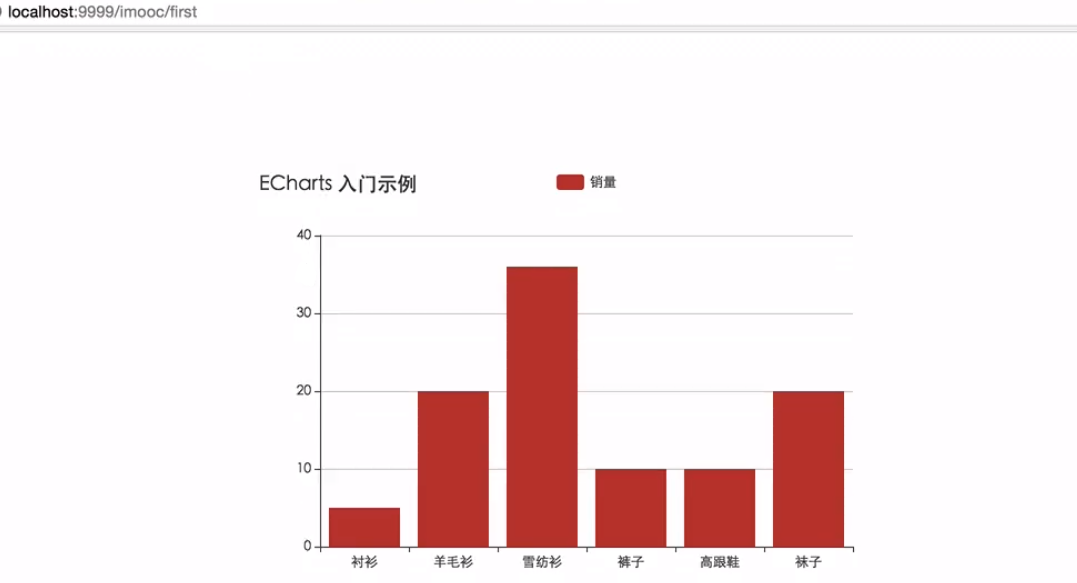
Spring Boot整合Echarts绘制静态数据柱状图
将echarts下载放入下图标红目录;同时将jquery也放入
同时创建test.html测试
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>test</title>
<!-- 引入 ECharts 文件 -->
<script src="js/echarts.min.js"></script>
</head>
<body>
<!-- 为 ECharts 准备一个具备大小(宽高)的 DOM -->
<div id="main" style="width: 600px;height:400px;position: absolute; top:50%; left: 50%; margin-top: -200px;margin-left: -300px"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title: {
text: 'ECharts 入门示例'
},
tooltip: {},
legend: {
data:['销量']
},
xAxis: {
data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"]
},
yAxis: {},
series: [{
name: '销量',
type: 'bar',
data: [5, 20, 36, 10, 10, 20]
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
测试
package com.imooc.spark;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.servlet.ModelAndView;
/**
* 这是我们的第一个Boot应用
*/
@RestController
public class HelloBoot {
@RequestMapping(value = "/hello", method = RequestMethod.GET)
public String sayHello() {
return "Hello World Spring Boot...";
}
@RequestMapping(value = "/first", method = RequestMethod.GET)
public ModelAndView firstDemo() {
return new ModelAndView("test");
}
}
访问 http://localhost:9999/imooc/first 进行测试
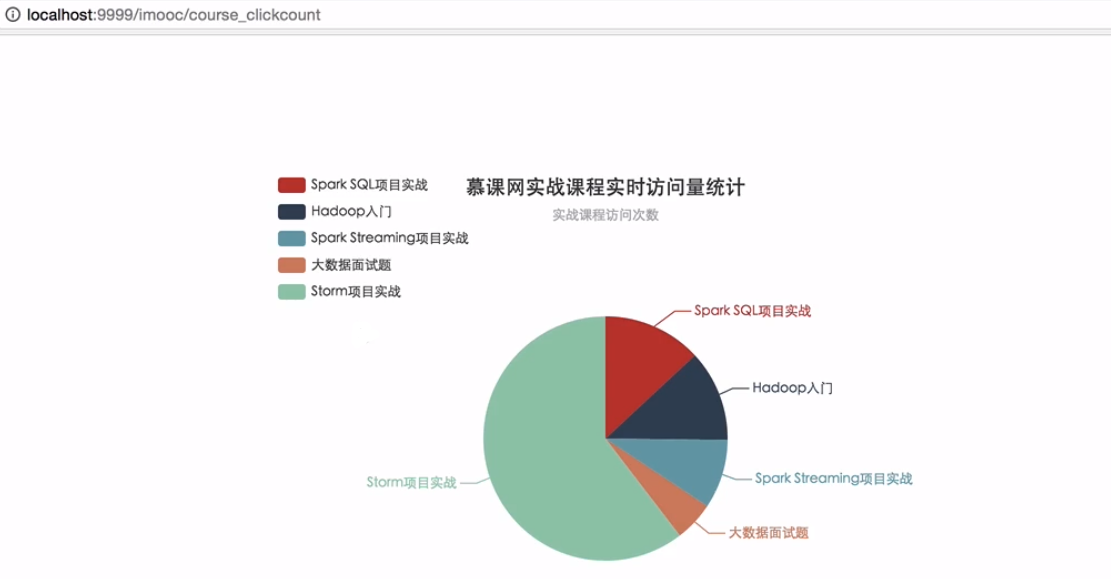
Spring Boot整合Echarts绘制静态数据饼图
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>imooc_stat</title>
<!-- 引入 ECharts 文件 -->
<script src="js/echarts.min.js"></script>
</head>
<body>
<!-- 为 ECharts 准备一个具备大小(宽高)的 DOM -->
<div id="main" style="width: 600px;height:400px;position: absolute; top:50%; left: 50%; margin-top: -200px;margin-left: -300px"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title : {
text: '慕课网实战课程实时访问量统计',
subtext: '实战课程访问次数',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} ({d}%)"
},
legend: {
orient: 'vertical',
left: 'left',
data: ['Spark SQL项目实战','Hadoop入门','Spark Streaming项目实战','大数据面试题','Storm项目实战']
},
series : [
{
name: '访问次数',
type: 'pie',
radius : '55%',
center: ['50%', '60%'],
data:[
{value:3350, name:'Spark SQL项目实战'},
{value:3100, name:'Hadoop入门'},
{value:2340, name:'Spark Streaming项目实战'},
{value:1350, name:'大数据面试题'},
{value:15480, name:'Storm项目实战'}
],
itemStyle: {
emphasis: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
package com.imooc.spark;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.servlet.ModelAndView;
/**
* 这是我们的第一个Boot应用
*/
@RestController
public class HelloBoot {
@RequestMapping(value = "/hello", method = RequestMethod.GET)
public String sayHello() {
return "Hello World Spring Boot...";
}
@RequestMapping(value = "/first", method = RequestMethod.GET)
public ModelAndView firstDemo() {
return new ModelAndView("test");
}
@RequestMapping(value = "/course_clickcount", method = RequestMethod.GET)
public ModelAndView courseClickCountStat() {
return new ModelAndView("demo");
}
}
访问 http://localhost:9999/imooc/demo 进行测试
项目目录调整
根据天来获取HBase表中的实战课程访问次数
hbase工具类
package com.imooc.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/**
* HBase操作工具类
*/
public class HBaseUtils {
HBaseAdmin admin = null;
Configuration conf = null;
/**
* 私有构造方法:加载一些必要的参数
*/
private HBaseUtils() {
conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "hadoop000:2181");
conf.set("hbase.rootdir", "hdfs://hadoop000:8020/hbase");
try {
admin = new HBaseAdmin(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
private static HBaseUtils instance = null;
public static synchronized HBaseUtils getInstance() {
if (null == instance) {
instance = new HBaseUtils();
}
return instance;
}
/**
* 根据表名获取到HTable实例
*/
public HTable getTable(String tableName) {
HTable table = null;
try {
table = new HTable(conf, tableName);
} catch (IOException e) {
e.printStackTrace();
}
return table;
}
/**
* 根据表名和输入条件获取HBase的记录数
*/
public Map<String, Long> query(String tableName, String condition) throws Exception {
Map<String, Long> map = new HashMap<>();
HTable table = getTable(tableName);
String cf = "info";
String qualifier = "click_count";
Scan scan = new Scan();
Filter filter = new PrefixFilter(Bytes.toBytes(condition));
scan.setFilter(filter);
ResultScanner rs = table.getScanner(scan);
for(Result result : rs) {
String row = Bytes.toString(result.getRow());
long clickCount = Bytes.toLong(result.getValue(cf.getBytes(), qualifier.getBytes()));
map.put(row, clickCount);
}
return map;
}
public static void main(String[] args) throws Exception {
Map<String, Long> map = HBaseUtils.getInstance().query("imooc_course_clickcount" , "20171022");
for(Map.Entry<String, Long> entry: map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
}
实战课程访问量domain以及dao开发
domain
package com.imooc.domain;
import org.springframework.stereotype.Component;
/**
* 实战课程访问数量实体类
*/
@Component
public class CourseClickCount {
private String name;
private long value;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
}
dao
package com.imooc.dao;
import com.imooc.domain.CourseClickCount;
import com.imooc.utils.HBaseUtils;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* 实战课程访问数量数据访问层
*/
@Component
public class CourseClickCountDAO {
/**
* 根据天查询
*/
public List<CourseClickCount> query(String day) throws Exception {
List<CourseClickCount> list = new ArrayList<>();
// 去HBase表中根据day获取实战课程对应的访问量
Map<String, Long> map = HBaseUtils.getInstance().query("imooc_course_clickcount","20171022");
for(Map.Entry<String, Long> entry: map.entrySet()) {
CourseClickCount model = new CourseClickCount();
model.setName(entry.getKey());
model.setValue(entry.getValue());
list.add(model);
}
return list;
}
public static void main(String[] args) throws Exception{
CourseClickCountDAO dao = new CourseClickCountDAO();
List<CourseClickCount> list = dao.query("20171022");
for(CourseClickCount model : list) {
System.out.println(model.getName() + " : " + model.getValue());
}
}
}
实战课程访问量Web层开发
package com.imooc.spark;
import com.imooc.dao.CourseClickCountDAO;
import com.imooc.domain.CourseClickCount;
import net.sf.json.JSONArray;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.servlet.ModelAndView;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* web层
*/
@RestController
public class ImoocStatApp {
//课程号和课程的关系正常情况下在数据库里;这里就简要编写了
private static Map<String, String> courses = new HashMap<>();
static {
courses.put("112","Spark SQL慕课网日志分析");
courses.put("128","10小时入门大数据");
courses.put("145","深度学习之神经网络核心原理与算法");
courses.put("146","强大的Node.js在Web开发的应用");
courses.put("131","Vue+Django实战");
courses.put("130","Web前端性能优化");
}
@Autowired
CourseClickCountDAO courseClickCountDAO;
// @RequestMapping(value = "/course_clickcount_dynamic", method = RequestMethod.GET)
// public ModelAndView courseClickCount() throws Exception {
//
// ModelAndView view = new ModelAndView("index");
//
// List<CourseClickCount> list = courseClickCountDAO.query("20171022");
// for(CourseClickCount model : list) {
// model.setName(courses.get(model.getName().substring(9)));
// }
// JSONArray json = JSONArray.fromObject(list);
//
// view.addObject("data_json", json);
//
// return view;
// }
//简单实现
@RequestMapping(value = "/course_clickcount_dynamic", method = RequestMethod.POST)
@ResponseBody
public List<CourseClickCount> courseClickCount() throws Exception {
List<CourseClickCount> list = courseClickCountDAO.query("20171022");
for(CourseClickCount model : list) {
model.setName(courses.get(model.getName().substring(9)));
}
return list;
}
@RequestMapping(value = "/echarts", method = RequestMethod.GET)
public ModelAndView echarts(){
return new ModelAndView("echarts");
}
}
实战课程访问量实时查询展示功能实现及扩展
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>imooc_stat</title>
<!-- 引入 ECharts 文件 -->
<script src="js/echarts.min.js"></script>
<!-- 引入 jQuery 文件 -->
<script src="js/jquery.js"></script>
</head>
<body>
<!-- 为 ECharts 准备一个具备大小(宽高)的 DOM -->
<div id="main" style="width: 600px;height:400px;position: absolute; top:50%; left: 50%; margin-top: -200px;margin-left: -300px"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title : {
text: '慕课网实战课程实时访问量统计',
subtext: '实战课程访问次数',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} ({d}%)"
},
legend: {
orient: 'vertical',
left: 'left'
},
series : [
{
name: '访问次数',
type: 'pie',
radius : '55%',
center: ['50%', '60%'],
data: (function(){ //<![CDATA[
var datas = [];
$.ajax({
type: "POST",
url: "/imooc/course_clickcount_dynamic",
dataType: 'json',
async: false,
success: function(result) {
for(var i=0; i<result.length; i++) {
datas.push({"value":result[i].value, "name":result[i].name})
}
}
})
return datas;
//]]>
})(),
itemStyle: {
emphasis: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
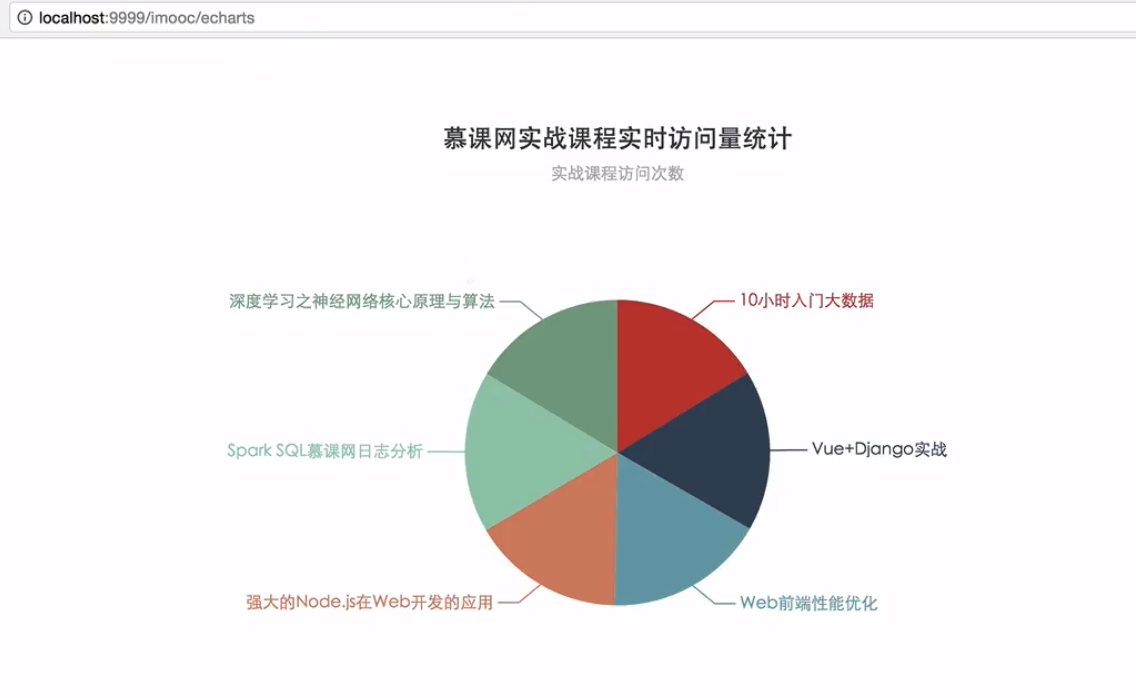
Spring Boot整合Echarts动态获取HBase的数据
1) 动态的传递进去当天的时间
a) 在代码中写死
b) 让你查询昨天的、前天的咋办?
在页面中放一个时间插件(jQuery插件),默认只取当天的数据
2) 自动刷新展示图
每隔多久发送一个请求去刷新当前的数据供展示
统计慕课网当天实战课程从搜索引擎过来的点击量
数据已经在HBase中有的
自己通过Echarts整合Spring Boot方式自己来实现和需求一代码基本雷同
Spring Boot项目部署到服务器上运行
打包:
mvn clean package -DskipTests
拷贝到服务器启动
java -jar 项目jar包名字
访问
http://服务器ip:9999/imooc/echarts
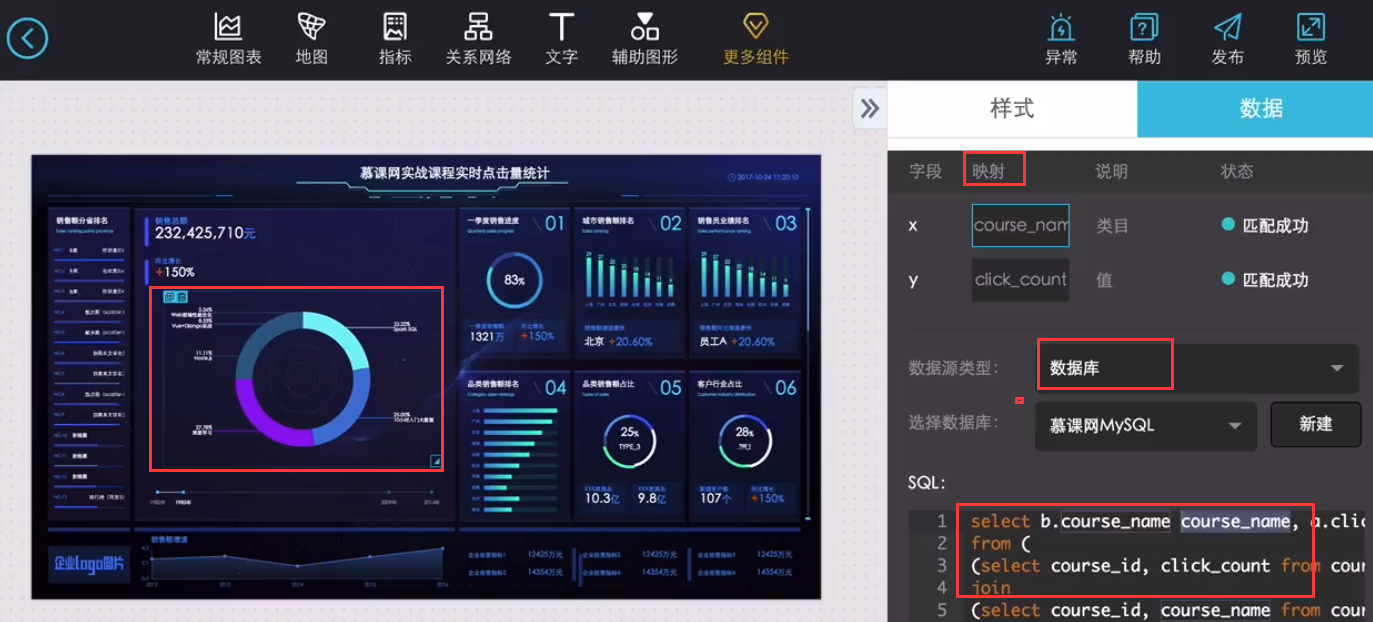
阿里云DataV数据可视化介绍
链接:
https://data.aliyun.com/visual/datav?utm_content=se_1000286536
DataV功能说明
1)点击量分省排名/运营商访问占比
Spark SQL项目实战课程: 通过IP就能解析到省份、城市、运营商
2)浏览器访问占比/操作系统占比
Hadoop项目:userAgent
DataV访问的数据库(MySQL),需要能够在公网上访问(比如阿里云服务器)
DataV测试数据
CREATE TABLE course_click_count
(
ID int(4) PRIMARY KEY,
day VARCHAR(10),
course_id VARCHAR(10),
click_count long
);
INSERT INTO course_click_count values (1,'20171111','112',8000);
INSERT INTO course_click_count values (2,'20171111','128',9000);
INSERT INTO course_click_count values (3,'20171111','145',10000);
INSERT INTO course_click_count values (4,'20171111','146',4000);
INSERT INTO course_click_count values (5,'20171111','131',3000);
INSERT INTO course_click_count values (6,'20171111','130',2000);
CREATE TABLE course_info
(
ID int(4) PRIMARY KEY,
course_id VARCHAR(10),
course_name VARCHAR(100)
);
INSERT INTO course_info values (1,'112','Spark SQL');
INSERT INTO course_info values (2,'128','10小时入门大数据');
INSERT INTO course_info values (3,'145','深度学习');
INSERT INTO course_info values (4,'146','Node.js');
INSERT INTO course_info values (5,'131','Vue+Django实战');
INSERT INTO course_info values (6,'130','Web前端性能优化');
select b.course_name course_name, a.click_count click_count
from (
(select course_id, click_count from course_click_count where day='20171111' ) a
join
(select course_id, course_name from course_info) b
on a.course_id = b.course_id
)