最近在使用Kettle进行ETL的工作,现在总结一下。需求是将MYSQL中的表数据增量备份到HIVE仓库中,第一次是全量。我只想给大伙来点实用的,避免大家踩坑。Kettle是一个基于图形化的ETL工具,也可以用于集成各种作业,比如Sqoop,MR,Hive这些,越来越多的企业在使用。
本文大纲:
1、Kettle的安装与配置
2、库表数据的准备
3、Kettle增量抽取数据模型
4、测试与验证
5、部署到Linux上运行
6、总结
1、Kettle的安装与配置
1.1 下载安装包,解压
到Kettle官网下载:https://community.hitachivantara.com/docs/DOC-1009855,目前最新的是8.0版本。(pdi-ce-8.0.0.0-28.zip),下载后解压到任意目录。注意与自己的JDK搭配上,我的JDK是1.8。如果你的是1.7,则下载Kettle的7.0版本。
1.2 配置环境变量
配置Kettle的工作目录,即KETTLE_HOME,指向自己解压后的目录。

1.3 修改Kettle的配置文件
配置完环境变量后,进入Kettle的主目录,点击Spoon.bat,即可启动。同时你在主目录下会发现多了一个.kettle目录,里面有kettle.properties文件。
请将下面的内容修改为你自己的相应环境,然后拷贝到kettle.properties文件里。主要用于后面的增量数据抽取模型。
第一部分:数据仓库路径,你得在集群中安装好Hive。
第二部分:Hadoop集群的配置,你得安装一个Hadoop集群。
第三部分:我们的数据源,我们需要抽取哪个库的数据。
第四部分:我们抽取数据需要写一些Log,将Log存储到数据库中。
第五部分:kettle转换和作业的存放地址。


1.4 添加Hadoop的配置文件到Kettle大数据插件中
将Hadoop集群中的hdfs-site.xml和core-site.xml文件拷贝到${KETTLE_HOME}\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh512目录下。
1.5 将MYSQL的驱动包拷贝到Kettle lib目录下
${KETTLE_HOME}\lib。
2、库表数据的准备
2.1 数据源数据
创建一个待抽取数据的数据库和表。数据库请按照自己在Kettle配置文件所配置的进行创建,在执行下面的创表脚本。

添加一些测试数据。

2.2 Log日志表
我们需要将抽取数据的Log记录到数据库中。数据库请按照自己在Kettle配置文件所配置的进行创建,在执行下面的创表脚本。

2.3 Hive表
创建Hive表,先创建一个名为rds的数据库,在建表。该表的字段与数据源的表类似,在此添加了一个数据加载时间,是为了区分记录。
3、Kettle增量抽 取数据模型
取数据模型
下面的这些作业和转换请保持在kettle配置文件中指定的路径下。
3.1 设置作业变量

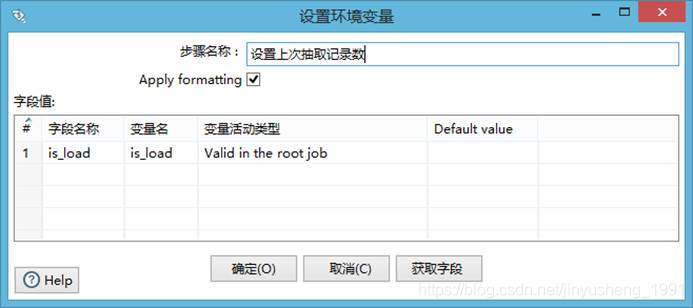
3.1.1获取上次抽取记录数
是为了判断是否是第一次抽取,若是第一次则全量抽取,否则增量抽取。

点击编辑,$是读取kettle配置文件中的变量值。

设置环境变量
3.1.2获取上次抽取时间
是为了实现增量抽取,从上次抽取结束时间到当前时间为增量数据。

设置上次数据抽取时间到变量中。

3.1.3获取系统当前时间
是为了增量抽取数据,取得当前的时间。

设置当前时间

3.2 抽取数据保存到Hive

3.2.1抽取mysql数据中的数据
抽取MYSQL数据源中的数据,使用is_load判断是否是第一次抽取,否则增量抽取。按照数据表数据更新时间进行过滤。is_load,before_time,curr_time都是前面设置的变量。

点击编辑,配置数据源。

3.2.2 动态生成文件名
这个文件名需要动态生成,因为不同的数据表保存到Hive的路径是不同的,Hive中表的数据是会根据表名创建一个目录,我们将数据保存到该目录下,就可以使用Hive SQL查询了,无需格外在进行一次load data导入。
注意:但这不是内部表,是外部表,只不过我们把数据放在而已。

3.2.3 获取数据仓库路径
这个路径是我们在kettle配置文件中配置的。

3.2.4生成数据入库时间
为每条数据增加一个字段,数据入库时间,即数据加载的时间。

3.2.5生成数据仓库最终保存路径
将数据仓库路径加上文件名就是一个完整的HDFS路径。

3.2.6保存数据到Hive
这里我们选择从字段中获取文件名,因为文件名是动态的,不能写死,否则以后你的工作量就线性增加了。

点击Edit。配置我们的Hadoop集群信息。

点击测试。显示下图,表示成功。

退回第一个弹出的窗口,点击内容。

点击字段。点击获取字段,点击最小宽度,将时间字段都设置为字符串,指定格式。不必要的字段可以删除。
3.3 保存本次数据抽取时间

3.3.1 生成唯一主键

3.3.2 获取当前时间

3.3.3 设置字段值

3.3.4 记录当次数据抽取时间

点击编辑。配置你的Log日志使用的数据库。

点击下方的数据字段。选择合适的字段。

3.4 建立一个JOB作业

添加一个转换,指向我们的“设置作业变量”转换所在的路径。其他两个类似,不在描述。

4、测试与验证
上面的工作都准备完成后,进行测试和验证。

查看HDFS是否有生成相应的文件。

在Linux的命令行窗口输入hive -e "select * from rds.test" 查看数据结果。

查看log表

接下来我们测试一个增量抽取。
在数据源表中添加一条新的数据。

重新点击运行一个job,查看HDFS。

在Linux的命令行窗口输入hive -e "select * from rds.test" 查看数据结果。

查看Log表

5、部署到Linux上运行
我们的ETL作业最终都是部署到Linux平台运行的,Kettle提供了kitchen.sh命令来让我们在后台运行JOB。在Linux平台上要安装Kettle,同时也要配置KETTLE_HOME,修改配置文件,改一下那些路径,知道我为什么把路径都配置起来了吧。
比如,可以写一个shell脚本,再让crontab来定时执行,也就是完整的企业级的ETL了。你也可以使用Azkaban或者Oozie来调度,看公司需求了。

6、总结
我们按照以上步骤执行以后在将job提交到Linux集群上,经过任务调度系统周期调度,就实现了一个表的自动同步问题,在大数据初级阶段,就自动实现了与数据源头的对接,感谢您的阅读。