版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/qq_17054989/article/details/80087341
1.思路分析
首先打开电影天堂的列表页

右键审查元素查看电影简介的链接
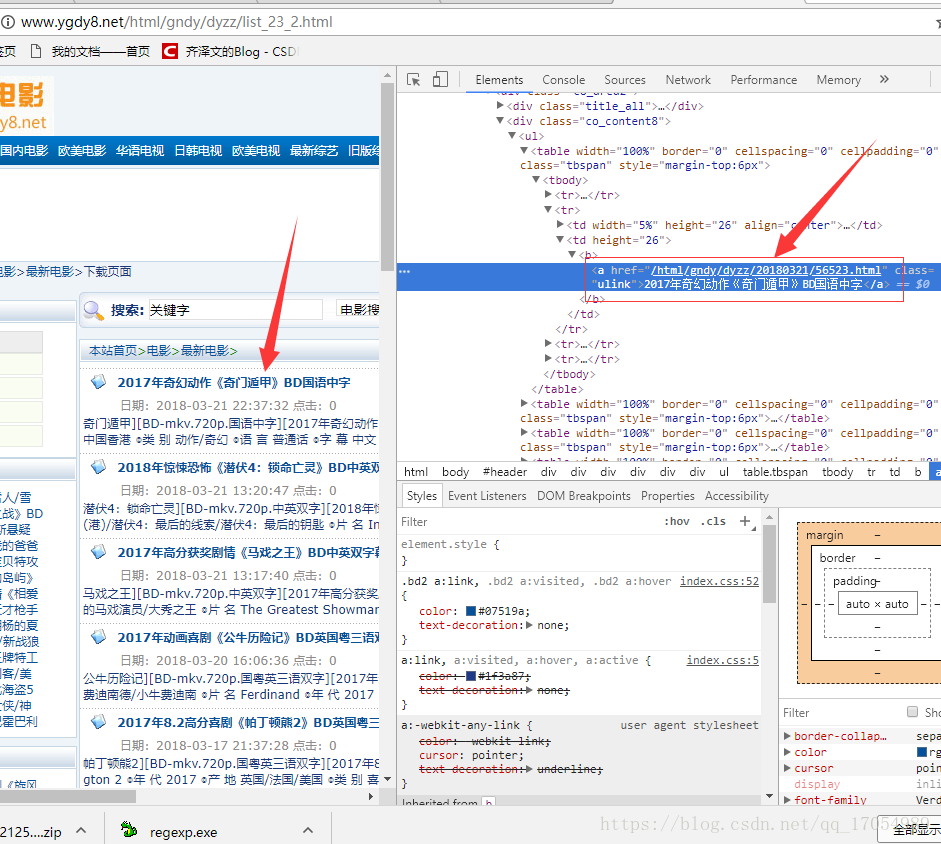
将此链接打开可以得到下载地址

可能是爬虫原因网站审查元素和用request得到的数据不一样,因此代码的正则表达式会改变
加上列表循环便可以批量输出下载链接
2.代码
#!/usr/bin/env python
#-*-coding:utf-8-*-
__author__ = 'Qi zewen QQ群497719008'
import requests
import re
# import time
#批量爬取电影天堂电影下载链接
for n in range(1,175):
a_url = 'http://www.dytt8.net/html/gndy/dyzz/list_23_'+str(n)+'.html' #网站地址
html_1 = requests.get(a_url) #连接到网站,返回状态码
html_1.encoding='gb2312' #改变网站编码为中文gb2312
# print(html_1.text)
detail_list=re.findall('<a href="(.*?)" class="ulink',html_1.text) #findall匹配正则表达式和网站代码获取 .text
# print(detail_list)
for m in detail_list:
# time.sleep(0.2)
# b_url = 'http://www.dytt8.net/{}'.format(m)
b_url = 'http://www.dytt8.net/%s'%m
html_2=requests.get(b_url)
html_2.encoding='gb2312'
# print(html_2.text)
ftp = re.findall('<a href="(.*?)">ftp.*?</a></td>',html_2.text)
if ftp != []:
print (ftp[0])
with open('dn.txt','a',encoding='utf-8') as f:
#写文本write到本地
if ftp != []:
f.write(ftp[0]+'\n')