数据库分布式,其核心内容无非就是数据切分(Sharding),以及切分后对数据的定位、整合工作,解决单一数据库或数据表因数据量过大而导致的性能瓶颈问题。这里有必要再做一个澄清,本文谈的数据库分布式并非分布式数据库,前者不关注数据细节的存储组织问题,而是仍然在已有的MySQL、ORACLE等成熟数据库系统基础上进行的一系列数据操作调度。后者分布式数据库则是集数据存储、管理以及分布式协调与计算为一体的数据库系统,目前尚无特别成熟的商用产品。
数据切分就是把数据分散存放到多个数据库或多个表中,使得单台主机中的数据量变小,使得通过扩充主机数量即可提升数据库操作性能的目的。
数据切分可分为纵向和横向两种切分方法。纵向切分就是根据业务耦合性,将关联度低的不同表独立建成不同的数据库。如下图所示:
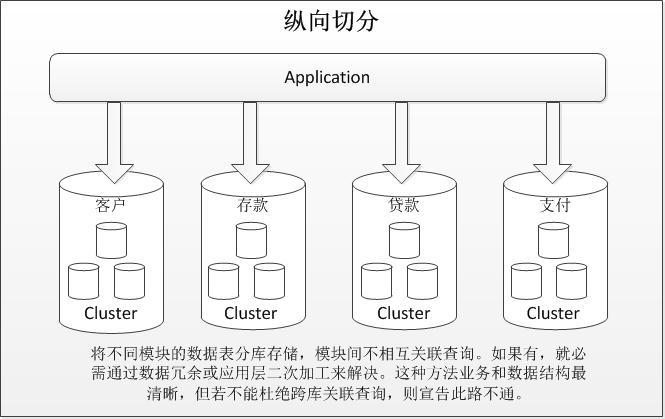
纵向切分相对简单,做法与我们将一个大的系统拆分成几个小系统的做法相似,就是根据业务分类进行独立划分应用或数据库。
然而当一个应用已经难以再进一步拆分时,或者拆分后数据行数巨大时,我们就还需要进行横向切分(即:将单个表的记录数变小)。横向切分是根据表内数据的逻辑关系,将同一个表按不同的条件拆分到多个数据库或多个表中。
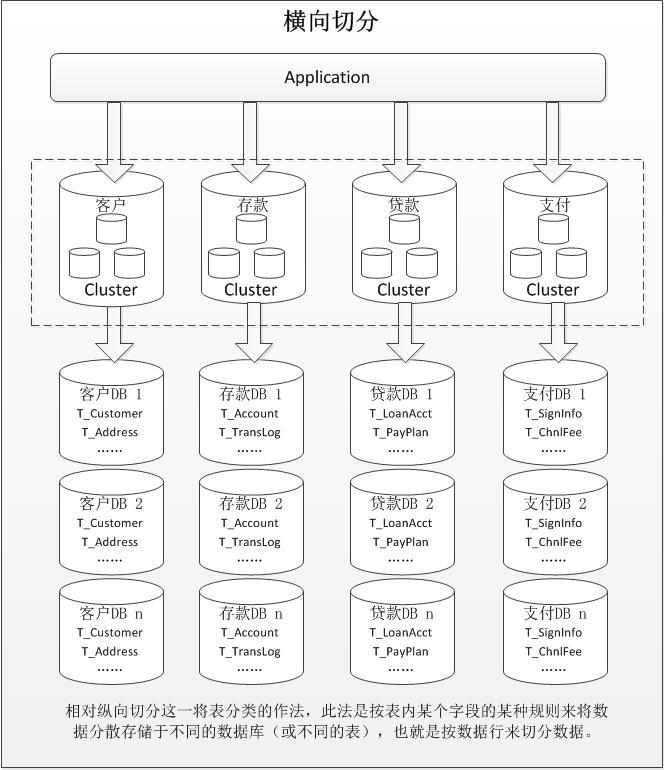
如上图所示,横向切分后同一张表同时出现在多个数据库中,每个库的数据内容不同,如何设定数据记录的切分规则是最重要考量。一旦确定切分规则,应用对该表的操作原则基本就已确定。假设我们将Customer表根据cus_no字段来切分到4个库,如果我们所有查询条件都带有cus_no字段则可明确定位到相应库去查询,但如果我们频繁用到的查询条件中不带cus_no时,将会导致无法定位数据库,从而需要同时向4个库发起查询,最后再合并数据、取最小集返回给应用,导致分库优势反而可能成为你的拖累。下图我们示意一个分表过程:
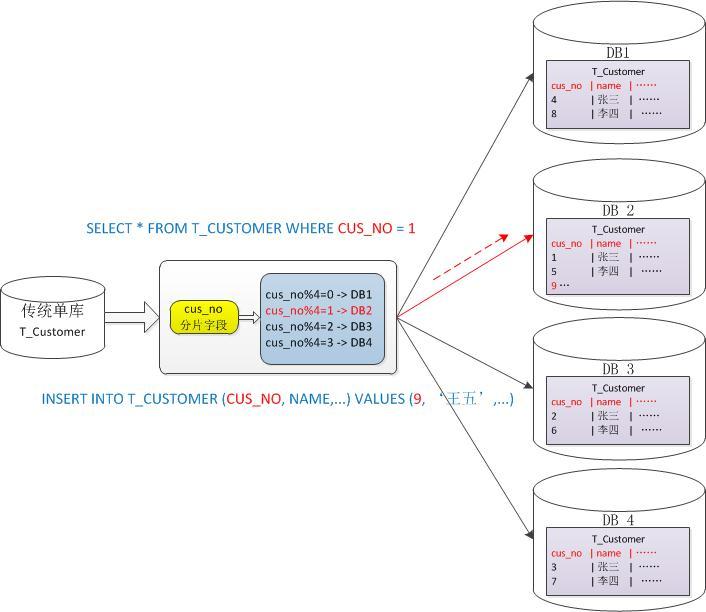
行文至此,分库分表的基本思路应该明了,紧接着有一箩筐的棘手问题还需要处理:
一、关联查询问题
数据切分后一大难题就是关联查询,跨库关联查询的想法最好打消掉,目前没有好的解决方案。简单一些的办法就是根据E-R图来切分,将同一族的数据都存放在本地库内,这样将跨库数据关联变成跨库数据拼接。
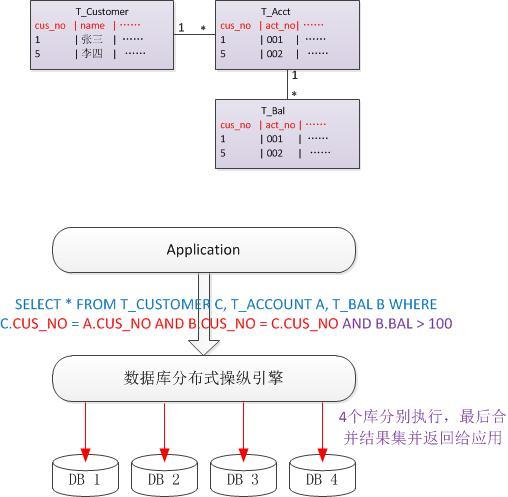
基于上述表间关系,同一客户的账户及账户的余额都在同一库,当查询条件未使用切分字段时,则将向4个库分别发起查询,以得到全部结果。

若希望查询某一客户的所有账户及余额时,将根据切分字段CUS_ID值直接定位到DB1库查询。
二、分页查询问题
正如前面提到的分库并行查询时,若需要分页查询则将出现悲剧,每个库返回的结果集本身是无序的,无法确定应该如何返回数据给用户。目前像MyCat这类中间件要求分页查询时必须带上ORDER BY字段,好使得多库查询结果全部出来后,再在内存中根据排序字段单独进行排序,最后返回最小结果集。可以想像,当查询的总结果集过大时,这一排序过程对资源和时间的消耗相当可观。
三、事务一致性问题
当我们需要更新的内容同时分布在不同库时,不可避免会带来跨库事务问题,在JavaEE体系下使用XA事务进行协调解决,但XA事务目前也并非完全安全,在最后确认提交这一步若某个库失败时,并不能确保所有库都能成功roolback。目前针对此种情况尚无简单的方案,需要采用日志分析、事后补偿的方式来解决,以达到互联网类系统宣称的“最终一致性”。
四、主键避重问题
由于表同时存在于多个数据库内,主键值我们平时常用的自增序列将无用武之地,因此需要单独设计全局主键,以避免跨库主键重复问题。
五、公共表问题
前方主要谈分表相关的内容,实际应用中大量的参数表、产品表等都数据量较小,而且属于高频联合查询的依赖表,这类表的所有数据都需要同时出现在各个库中。
一种办法就是我们对公共表的所有更新操作都同时发送到所有分库执行,然后指定一个主库,若主库成功我们就认为操作成功,然后再定期对其它库的数据进行同步操作。
上面所列的五大问题只是我们从宏观层面所看到的,还有许多实操环节的细节问题、分布式数据库中间件自身局限问题,例如SQL阻塞、死锁等导致全库无法工作等都会存在,特别是在主从模式下带来的数据不一致等问题。一旦你选择了数据切分,这些问题便接踵而来,如何构建相应的数据修复机制、避免全局故障等问题将伴随整个应用生命周期。
最后来点个人意见,作为我等传统银行,在非关键业务应用中可以尝试,原则上能不分表就不分表。我愿意相信,在数据膨胀的时代驱动下,成熟的商业化分布式数据库问世的时间将不会太久,像传统银行核心这类系统不妨等等看。