前言
好久没写博客了,打算把之前做的一个电影评分资讯推送的微信开发全程记录一下,适合对网络爬虫、微信开发感兴趣的童鞋。在教程开始之前,我想先引出两个问题(这次写博客假装很有条理的样子= =)
1. 为什么想要抓取ONE电影的数据?
因为我平时本身就喜欢去电影院看电影,所以关注到ONE·APP有电影栏目,而且评分信息一目了然,非常适合我这种人,该看哪一部你懂的~(PS:这是写博客当天截的图,下周末去看82分机器猫,嘿嘿)

当然了,豆瓣电影也有评分,但是感觉那里水军很多,所以数据参考价值不大吧。顺便普及一下,“一个”APP是由韩寒创立的,最初只有文学栏目,2016年初才进军电影行业(相关报道),目的就是让电影打分少一点套路,多一分真诚,用心良苦呀,所以我们就用收下韩寒这份好意吧!
2. 我需要提前准备什么东西?
- 首先,你得有一台手机(你是不是傻?请忽略这条),如果16g苹果没内存可用安卓模拟器代替。。。(没有别的意思…)
- 其次,你得有java网络爬虫相关知识,主要是httpclient的使用,解析JSON用的是效率较高的jackson。
- 最后,你得有微信java开发经验,主要解决数据呈现问题,当然你也可以使用仅用的JAVA EE知识做一个网页来呈现数据。因为不能面面俱到,所以此教程可能不会过多讲解这一块内容,这里推荐慕课网视频教程,建议直奔重点看第五章,十分受用。
对了,先放个图,看下微信开发的功能最终效果,噔噔噔噔~↓
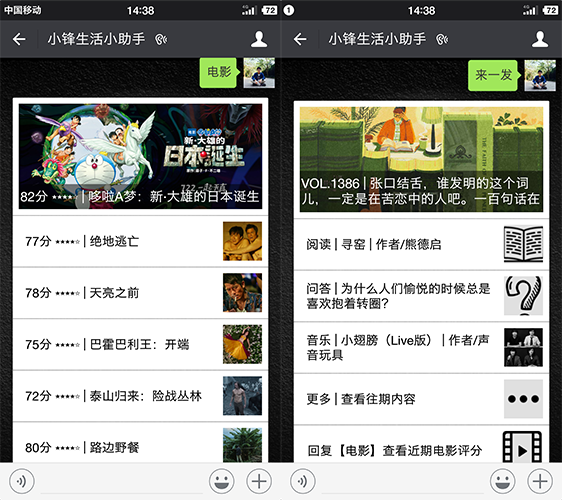
还是像模像样的,前面bb了那么多,下面开始我们的教程吧!
思路
1. 抓取数据(Fidder抓包,手机wifi代理)
2. 分析数据(解析JSON/HTML,提取有用信息)
3. 微信开发(文本消息匹配、被动回复图文)
基本思路是对数据的抓取→分析→处理→呈现,下面以ONE·APP的电影数据为例,本教程会把重点放在前面两part。
实战
1. 抓取数据
前期准备
下载抓包工具Fiddler:大家到网上去下载就好了,我这里用的是
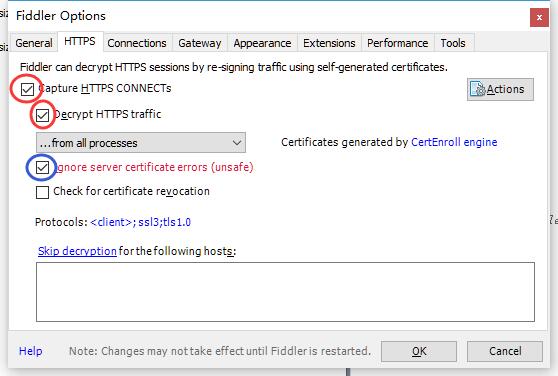
V4.6。设置Fiddler规则(关键):点
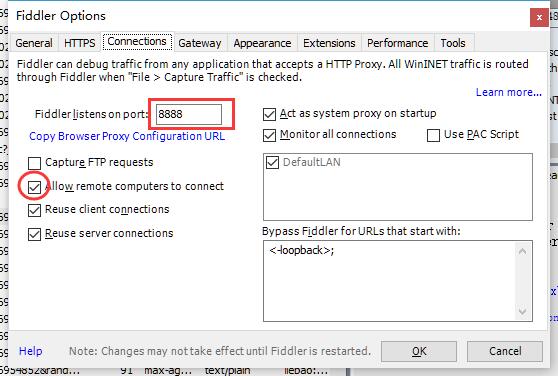
Tools->Fiddler Options->HTTPS,勾选Capture HTTPS CONNECTs和Decrypt HTTPS traffic这两项,建议勾上ignore server certificate erros (unsafe)保证我们抓包时候不会狂弹窗而影响心情;切换到Connections选项卡,再勾选allow remote computers to connect这项,记住这里出现的Fiddler listens on port端口号是8888(当然这里可以自己改成别的,但是建议不要这样做),之后会用到它。
设置完必须重启Fiddler搭建网络环境:使电脑和手机在同一个局域网下,这个为之后的手机wifi代理做准备。
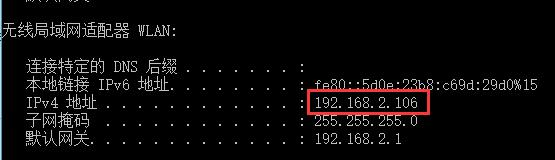
查看电脑内网IP:在命令行输入
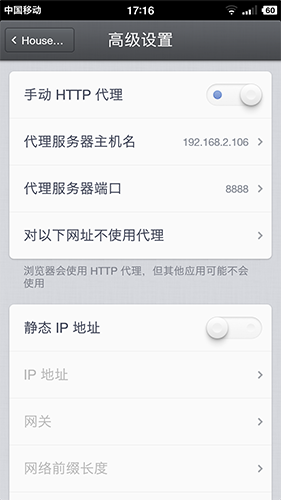
ipconfig查看内网IP,我这里查到是192.168.2.106,先记住,下面会用到。设置手机wifi代理(关键):不用手机可能有点不一样,我这里以我的安卓小锤子来做示范。
设置->无线网络->已连接的网络详细->高级设置,开启手动HTTP代理,填写代理服务器主机名为电脑内网IP 192.168.2.106,以及代理服务器端口为Fiddler显示的8888。其他系统和型号的手机自己琢磨下吧~手机下载“一个”APP:在各大手机应用市场搜索
一个、ONE、韩寒均可下载。
下面开始才是重点
手机打开“一个”APP,在抓包之前先清理Fiddler刚刚的抓取到的包,方便我们等下筛选。
点开“电影”栏目,观察Fiddler的抓包情况。到这里你已经成功了一半了,host为
wufazhuce.com正是“一个”的域名,而且url为/api/movie/list/0?(这很restful…),可以确定是我们想要的那个请求。
(但是在实际抓包中,往往会有各种各样的无用信息掺杂在里面,这时候就需要我们去辨别哪些是我们想要的url)
我们通过直接访问刚刚抓取到的url:http://v3.wufazhuce.com:8000/api/movie/list/0?,打开发现返回的是json格式的数据,正是我们想要的。到此为止,我们的抓取数据part已经完成了,应该不困难吧= =


没有抓取到包可能出现的原因:
- 电脑和手机不在同一个局域网内
- Fiddler设置不对
- 手机wifi没有代理成功,可能是填写有误,也可能是手机系统问题
- 最有可能的是我之前遇到的问题:设置完代理后,要先关闭APP,再重新打开
- 人品问题,自行百度,也欢迎留言哈~
更多API分享
电影详情:
http://v3.wufazhuce.com:8000/api/movie/detail/ID首页电影故事:
http://v3.wufazhuce.com:8000/api/movie/ID/story/1/0全部电影故事:
http://v3.wufazhuce.com:8000/api/movie/ID/story/0/0热门评论(点赞数)
http://v3.wufazhuce.com:8000/api/comment/praise/movie/ID/0全部评论(发表时间)
http://v3.wufazhuce.com:8000/api/comment/time/movie/ID/0
注意:所有URL中的ID替换为实际的电影ID即可,最后以为参数0所代表的含义代表下标ID,在下文中会提及到,默认写0。
2.分析数据
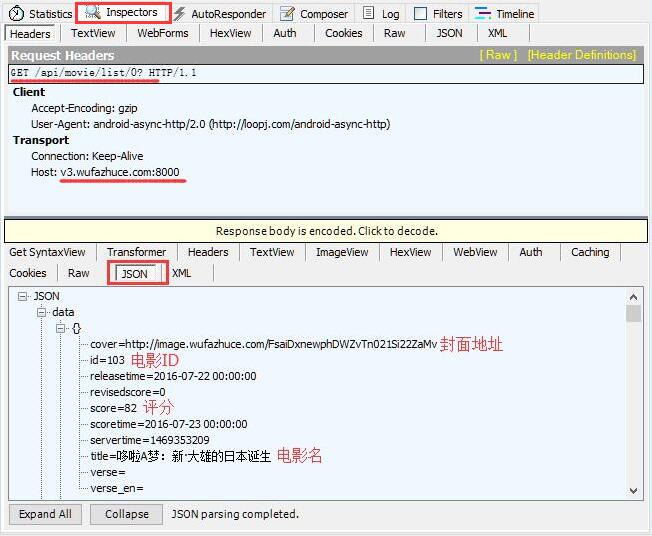
我们选择那条请求,查看软件右边的请求详细分析,由于我们事先知道请求返回数据类型是json,所以我们点
Inspectors选项卡下的JSON选项卡,如下图。我们把有用的信息记录下来,很有必要。
请求方式&地址:GET http://v3.wufazhuce.com:8000/api/movie/list/0
备注:url中的最后一个参数代表电影ID下标,用于分页功能,假如你第一页最后一个电影记录的ID是84,那么你再次请求地址http://v3.wufazhuce.com:8000/api/movie/list/84,得到的数据就是从85开始,也就是下一页电影的数据。这里要靠大家软件开发的经验以及亲手尝试过才知道,听不懂也没关系,这一个参数不足以影响我们的开发。你只要知道默认是0,获取最新的电影数据就行了。
json返回部分有用数据{ "res": 0, "data": [ { "id": "103", "title": "哆啦A梦:新·大雄的日本诞生", "score": "82", "cover": "http://image.wufazhuce.com/FsaiDxnewphDWZvTn021Si22ZaMv" } ]}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
参数 类型 说明 res int 返回码:0-成功,1-失败 data array 数据集合 -
id
int 电影ID,唯一标识 -
title
string 电影名 -
score
int 评分 -
cover
string 封面地址
当然了,这种是json数据格式的分析过程,这个跟过程跟你得业务有关,而我只需要实现一开始所呈现的那种图片效果,以上这些数据就够了。使用jackson来解析数据。
如果返回的数据是xml格式,也很好办,跟json差不多,使用xstream解析。
如果返回的数据是带视图模型(也就是有页面的),那就要用浏览器审查元素或者查看源代码,细心观察需要爬取的数据都在哪些div里面,观察它或者它的父元素是否有什么标志性的id甚至是class,这样就能通过jsoup解析它们。网页爬虫可以参考我上一篇爬虫文章《基于WebMagic写的一个csdn博客小爬虫》,框架里面用到的就是强大的jsoup。
数据分析完后,接下来就是真正的coding了!
3.微信开发
添加maven依赖(maven配置视频,或者手动下载jar包)
<!-- HttpClient --><dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.3.6</version></dependency><dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpmime</artifactId> <version>4.3.6</version></dependency><!-- JSON --><dependency> <groupId>org.codehaus.jackson</groupId> <artifactId>jackson-mapper-asl</artifactId> <version>1.9.13</version></dependency><!-- XML --><dependency> <groupId>com.thoughtworks.xstream</groupId> <artifactId>xstream</artifactId> <version>1.4.7</version></dependency><!-- HTML --><dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.9.2</version></dependency><!-- IO --><dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.4</version></dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
添加wx-tools.jar(我一个室友写的框架,下载jar包,查看官方文档,3分钟上手教程)
当然了,如果嫌麻烦你可以不使用任何的微信后台框架,如果没学习过微信java开发的请移步到慕课网视频教程,直奔重点看第五章。编写爬虫业务(重点)
package com.soecode.xfshxzs.service;/** * 电影爬虫业务 */public class MovieService { // 电影列表URL private static final String MOVIE_LIST_URL = "http://v3.wufazhuce.com:8000/api/movie/list/0"; /** * 获取电影列表 * * @return */ public List<Movie> getMovieList() { List<Movie> list = new ArrayList<Movie>(); try { String json = HttpUitl.doGet(MOVIE_LIST_URL); ObjectMapper mapper = new ObjectMapper(); JsonNode root = mapper.readTree(json); JsonNode data = root.path("data"); if (data.isArray()) { for (JsonNode node : data) { Movie movie = mapper.readValue(node, Movie.class); list.add(movie); } } } catch (ClientProtocolException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return list; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
自己写的一个HTTP工具类,拥有doGet方法,实现了传入一个url,输出网页字符串文本。
package com.soecode.xfshxzs.util;/** * HTTP工具类 */public class HttpUitl { /** * 普通GET请求 * * @param uri * @return * @throws IOException * @throws ClientProtocolException */ public static String doGet(String uri) throws ClientProtocolException, IOException { String html = null; CloseableHttpClient httpClient = HttpClients.createDefault(); HttpGet httpGet = new HttpGet(uri); CloseableHttpResponse response = httpClient.execute(httpGet); HttpEntity entity = response.getEntity(); if (entity != null) { html = EntityUtils.toString(entity); EntityUtils.consume(entity); } httpGet.releaseConnection(); response.close(); return html; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
编写处理器:调用业务方法,实现星星效果,装配图文消息,发送给用户
package com.soecode.xfshxzs.handler;/** * 电影消息处理器 */public class MovieMessageHandler implements WxMessageHandler { private MovieService movieService = new MovieService(); public WxXmlOutMessage handle(WxXmlMessage wxMessage, Map<String, Object> context, WxService wxService) throws WxErrorException { String content = wxMessage.getContent(); List<Movie> list = movieService.getMovieList(); for (int i = 0; i < 8; i++) { Item item = new Item(); item.setTitle(movieDetail.getScore() + "分 " + createStarsByScore(movieDetail.getScore()) + " | " + movieDetail.getTitle()); item.setPicUrl(movieDetail.getDetailcover()); builder.addArticle(item); } return WxXmlOutMessage.NEWS().toUser(wxMessage.getFromUserName()).fromUser(wxMessage.getToUserName()).build(); } /** * 根据分数创建星星 * * @param score * @return */ private String createStarsByScore(int score) { String stars = ""; int solidStarsNum = Math.floorDiv(score + 10, 20); for (int i = 0; i < solidStarsNum; i++) { stars += "★"; } int hollowStarsNum = 5 - solidStarsNum; for (int i = 0; i < hollowStarsNum; i++) { stars += "☆"; } return stars; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
新建拦截规则:匹配文本类消息“电影”,看不懂也没关系,真的没关系= =
router.rule().async(false).msgType(WxConsts.XML_MSG_TEXT).rContent("电影").handler(new MovieMessageHandler()).end();- 1
- 剩下就是微信服务器验证了,在开发过程中我们应该本地调试过才放到自己服务器上,之前使用的内网映射(穿透)工具ngrok(怀念一下)不知道何时用不了了,所以一直在用很不稳定的花生壳,大家自己选择吧。到此为止,我们的教程已经顺利完成了,此处应有掌声,啪啪啪啪~
要源码请继续往下看↓
后记
教程中只涉及到了电影资讯的爬虫,还有查天气、查快递等更多功能请关注公众号尽情调戏(好像有BUG?),仅作为一个DEMO参考。放二维码目的不是为了增粉啊,真的不是啊,只是想演示以上教程,赶紧扫吧~

这个微信公众号的java源码我已经放到了我的GitHub上了,大家可以下载参考,互相交流学习~
https://github.com/liyifeng1994/xfshxzs
很感谢大家能够看到这里,你们的每一个阅读量都是对我莫大的鼓励!(如果能去github给个赞就更好啦~嘻嘻~)
哦对了,说到电影,我要顺便给你们一点福(an)利,以下是我的电影日常= =。
男神福利:如何低价购买电影票?(知乎网友攻略)
宅男福利:高清控联盟(专注高清蓝光)
凌晨了,要睡觉了,又写到这么晚= = 以后不能再这样了!!
在接下来的大学里最后一个暑假,我要好好看完刚从图书馆里借来的两本书,加油!fighting!!

再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!希望你也加入到我们人工智能的队伍中来!http://www.captainbed.net
