【题外话】
这是2010年参加比赛时候做的研究,当时为了实现对Word、Excel、PowerPoint文件文字内容的抽取研究了很久,由于Java有POI库,可以轻松的抽取各种Office文档,而.NET虽然有移植的NPOI,但是只实现了最核心的Excel文件的读写,所以之后查了很多资料才实现了Word和PowerPoint文件文字的抽取。之后忙于各种事情一直没时间整理,后来虽然想写成文章但由于时间太久也记不清很多细节,现在重新查找资料并整理如下,希望对大家有用。
【系列索引】
- Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(一)
获取Office二进制文档的DocumentSummaryInformation以及SummaryInformation - Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(二)
获取Word二进制文档(.doc)的文字内容(包括正文、页眉、页脚、批注等等) - Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(三)
详细介绍Office二进制文档中的存储结构,以及获取PowerPoint二进制文档(.ppt)的文字内容 - Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(完)
介绍Office Open XML文档(.docx、.pptx)如何进行解析以及解析Office文件常见开源类库
【文章索引】
- .NET下读取Office文件的方式
- Windows复合二进制文件及其Header
- 我们从Directory开始
- DocumentSummaryInformation和SummaryInformation
- 相关链接
10年的时候参加比赛要做一个文件检索的系统,要包含Word、PowerPoint等文件格式的全文检索。由于之前用过.NET并且考虑到这些是微软的格式,可能使用.NET读取会更容易些,但没想到.NET这边查到的资料只有Interop的方式读取Office文件。后来接触了Java的POI,发现.NET也有移植的NPOI,但是只移植了核心的Excel读写,并没有Word、PowerPoint等文件的读写,所以最后没有办法只能硬着头皮自己去做Word和PowerPoint文件的解析。
那么Interop是什么?Interop的全称是“Interoperability”,即微软希望托管的.NET能与非托管的COM进行互相调用的一种方式。通过Interop读写Office即调用安装在计算机上的Office软件来实现Office的读写,其优点显而易见,文件还是由Office生成或读取的,所以与自己打开Office是没有任何区别的;但缺点也非常明显,即运行程序的计算机上必须安装有对应版本的Office软件,同时操作Office文件时实际上是打开了对应的Office组件,所以运行效率低、耗内存大并且还可能产生内存泄露的问题。关于Interop方式读写Office文件的例子网上有很多,有兴趣的可以自行查阅,这里就不再多讲了。
那么,有没有方式不借助Office软件实现Office文件的读写呢?答案肯定是肯定的,就像Java中的POI及.NET中的NPOI实现的那样,即通过程序自己读写文件来实现Office文件的读写。不过由于Office文件结构非常复杂,这里只提供文件摘要信息和文件文本内容的解析。不过即使如此,对于全文检索什么的还是足够的。
前几年,微软开放了一些私有格式的规范,使得所有人都可以对其文件进行解析,而不需要支付任何费用,这也使得我们编写解析文件的程序成为可能,相关链接在文章最后可以找到。对于一个Microsoft Office文件,其实质是一个Windows复合二进制文件(Windows Compound Binary File),文件的头Header是固定的512字节,Header记录文件最重要的参数。Header之后可以分为不同的Sector,Sector的种类有FAT、Mini-FAT(属于Mini-Sector)、Directory、DIF、Stroage等五种。为了方便称呼,我们规定每个Sector都有一个SectorID,Header后的Sector为第一个Sector,其SectorID为0。
我们先来说Header,一个Header的部分截图及包含的信息如下,比较重要的用粗体表示。

- Header的前8字节Byte[],也就是整个文件的前8字节,都是固定的0xD0 0xCF 0x11 0xE0 0xA1 0xB1 0x1A 0xE1,如果不是则说明不是复合文件。
- 从008H到017H的16字节,是Class Id,不过很多文件都置的0。
- 从018H到019H的2字节UInt16,是文件格式的次要版本。
- 从01AH到01BH的2字节UInt16,是文件格式的主要版本。
- 从01CH到01DH的2字节UInt16,是固定为0xFE 0xFF,表示文档使用的是Little Endian(低位在前,高位在后)。
- 从01EH到01FH的2字节UInt16,是Sector大小的幂,默认为9(0x09 0x00),即每个Sector为512字节。
- 从020H到021H的2字节UInt16,是Mini-Sector大小的幂,默认为6(0x06 0x00),即每个Mini-Sector为64字节。
- 从022H到023H的2字节UInt16,是预留的,必须置0。
- 从024H到027H的4字节UInt32,是预留的,必须置0。
- 从028H到02BH的4字节UInt32,是预留的,必须置0。
- 从02CH到02FH的4字节UInt32,是FAT的数量。
- 从030H到033H的4字节UInt32,是Directory开始的SectorID。
- 从034H到037H的4字节UInt32,是用于事务的,必须置0。
- 从038H到03BH的4字节UInt32,是最小串(Stream)的最大大小,默认为4096(0x00 0x10 0x00 0x10)。
- 从03CH到03FH的4字节UInt32,是MiniFAT表开始的SectorID。
- 从040H到043H的4字节UInt32,是MiniFAT表的数量。
- 从044H到047H的4字节UInt32,是DIFAT开始的SectorID。
- 从048H到04BH的4字节UInt32,是DIFAT的数量。
- 从04CH到1FFH的436字节UInt32[],是前109块FAT表的SectorID。
那么我们可以写如下的代码将Header中重要的内容解析出来。
 View Code
View Code
说个比较有意思的,.NET中的BinaryReader有很多读取的方法,比如ReadUInt16、ReadInt32之类的,只有ReadUInt16的Summary写着“使用 Little-Endian 编码...”(见下图),其实不仅仅是ReadUInt16,所有ReadIntX、ReadUIntX、ReadSingle、ReadDouble都是使用Little-Endian编码方式从流中读的,大家可以放心使用,而不需要一个字节一个字节的读再反转数组,我在10年的时候就走过弯路。解释在MSDN各个方法中的备注里:http://msdn.microsoft.com/zh-cn/library/vstudio/system.io.binaryreader_methods.aspx

复合文档中其实存放着很多内容,这么多内容需要有个目录,那么Directory就是这个目录。从Header中我们可以读取出Directory开始的SectorID,我们可以Seek到这个位置(0x200 + sectorSize * dirStartSectorID)。Directory中每个DirectoryEntry固定为128字节,其主要结构如下:
- 从000H到040H的64字节,是存储DirectoryEntry名称的,并且是以Unicode存储的,即每个字符占2个字节,其实可以看做是UInt16。
- 从041H到042H的2字节UInt16,是DirectoryEntry名称的长度(包括最后的“\0”)。
- 从042H到042H的1字节Byte,是DirectoryEntry的类型。(主要的有:1为目录,2为节点,5为根节点)
- 从044H到047H的4字节UInt32,是该DirectoryEntry左兄弟的EntryID(第一个DirectoryEntry的EntryID为0,下同)。
- 从048H到04BH的4字节UInt32,是该DirectoryEntry右兄弟的EntryID。
- 从04CH到04FH的4字节UInt32,是该DirectoryEntry一个孩子的EntryID。
- 从074H到077H的4字节UInt32,是该DirectoryEntry开始的SectorID。
- 从078H到07BH的4字节UInt32,是该DirectoryEntry存储的所有字节长度。
显然,Directory其实是一个树形的结构,我们只要从第一个Entry(Root Entry)开始递归搜索就可以了。
为了方便开发,我们创建一个DirectoryEntry的类
View Code
然后我们递归搜索就可以了
View Code
【四、DocumentSummaryInformation和SummaryInformation】
Office文档包含很多摘要信息,比如标题、作者、编辑时间等等,如下图。
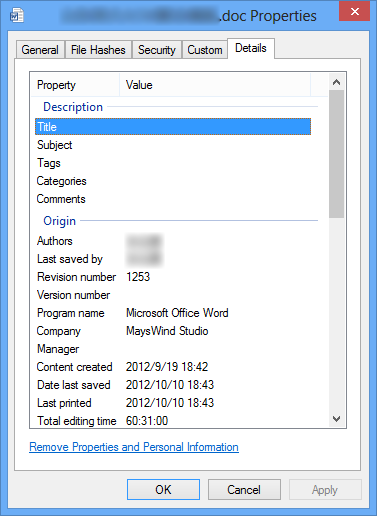
摘要信息又分为两类,一类是DocumentSummaryInformation,另一类是SummaryInformation,分别包含不同种类的摘要信息。通过上述的代码应该能获取到Root Entry下有一个叫“\005DocumentSummaryInformation”的Entry和一个叫“\005SummaryInformation”的Entry。
对于DocumentSummaryInformation,其结构如下
- 从018H到01BH的4字节UInt32,是存储属性组的个数。
- 从01CH开始的每20字节,是属性组的信息:
- 对于前16字节Byte[],如果是0x02 0xD5 0xCD 0xD5 0x9C 0x2E 0x1B 0x10 0x93 0x97 0x08 0x00 0x2B 0x2C 0xF9 0xAE,则表示是DocumentSummaryInformation;如果是0x05 0xD5 0xCD 0xD5 0x9C 0x2E 0x1B 0x10 0x93 0x97 0x08 0x00 0x2B 0x2C 0xF9 0xAE,则表示是UserDefinedProperties。
- 对于后4字节UInt32,则是该属性组相对于Entry的偏移。
对于每个属性组,其结构如下:
- 从000H到003H的4字节UInt32,是属性组大小。
- 从004H到007H的4字节UInt32,是属性组中属性的个数。
- 从008H开始的每8字节,是属性的信息:
- 对于前4字节UInt32,是属性编号,表示属性的种类。
- 对于后4字节UInt32,是属性内容相对于属性组的偏移。
常见的属性编号有以下这些:
View Code
对于每个属性,其结构如下:
- 从000H到003H的4字节UInt32,是属性内容的类型。
- 类型为0x02时为UInt16。
- 类型为0x03时为UInt32。
- 类型为0x0B时为Boolean。
- 类型为0x1E时为String。
- 剩余的字节为属性的内容。
- 除了类型是String时为不定长,其余三种均为4位字节(多余字节置0)。
- 类型是String时前4字节是字符串的长度(包括“\0”),所以没法使用BinaryReader的ReadString读取。之后长度为字符串内容,字符串是使用单字节编码进行存储的,可以使用Encoding中的GetString获取字符串内容。
为了方便开发,我们创建一个DocumentSummary的类。比较有意思的是,不论DocumentSummaryInformation还是SummaryInformation,第一个属性都是记录该组内容的代码页编码,可以通过Encoding.GetEncoding()获取对应的编码然后用GetString把对应的字符串解析出来:
View Code
然后我们进行读取就可以了:
View Code
而SummaryInformation与DocumentSummaryInformation相比读取方式是一样的,只不过属性组的16位标识为0xE0 0x85 0x9F 0xF2 0xF9 0x4F 0x68 0x10 0xAB 0x91 0x08 0x00 0x2B 0x27 0xB3 0xD9。
常见的SummaryInformation属性的属性编号如下:
View Code
其他代码由于与DocumentSummaryInformation相近就不再单独给出了。
附,本文所有代码下载:https://github.com/mayswind/SimpleOfficeReader
1、Microsoft Open Specifications:http://www.microsoft.com/openspecifications/en/us/programs/osp/default.aspx
2、用PHP读取MS Word(.doc)中的文字:https://imethan.com/post-2009-10-06-17-59.html
3、Office檔案格式:http://www.programmer-club.com.tw/ShowSameTitleN/general/2681.html
4、LAOLA file system:http://stuff.mit.edu/afs/athena/astaff/project/mimeutils/share/laola/guide.html
【后记】
花了好几天的时间才写完读取DocumentSummaryInformation和SummaryInformation,果然自己写程序用和写成文章区别太大了,前者差不多就行,后者还得仔细查阅资料。如果您觉得好就点下推荐呗。