稍微了解一下程序中数据库操作历史吧!
1.首先是JDBC连接
2.c3p0
3.JPA
JPA是Java Persistence API的简称,中文名Java持久层API,是JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中.
4.hibernate
实现了全自动的ORM(对象关系映射)
- 数据持久化:用户只需要操作对象即可,内部将对象最终转化为sql.
- 结果集映射:将sql执行后的结果自动的映射为对象
缺点:
- 耗费内存
- 会形成冗余的sql,执行的效率较低
- 如果是关联查询,则需要冗余的配置,同时需要学习hsql
5.Mybatis
以半自动的ORM的方式操作数据库
- sql语句需要自己手写
- 能够实现结果集映射.
6.通用Mapper等
特点:基于Mybatis的,实现类单表的orm自动映射.
以面向对象的方式操作单表.
我们重点了解一下通用mapper,假设你们都会Mybatis
通用Mapper底层原理
- 1. 定义公共的接口方法
包含了单表操作的全部方法.CRUD等操作
- 将接口方法最终转为Sql语句
例子:以新增为例
Sql: insert into 表名(字段名称) values(值….)
- 3. 将对象与表一一映射
对 象名称{对象的属性} >>>>> 表名(字段….)
- 最终形成sql
Sql:insert into 表名(字段…) values(对象的属性值…….)
使用通用Mapper对数据库进行操作,要对实体类进行一些操作:
1.要在实体类 名上加上@Table注解,并加上表名,还要定义主键,以及自增@GeneratedValue(Strategy=GenerationType.IDENTITY)
如果表不自增的话,就不要加@GeneratedValue(Strategy=GenerationType.IDENTITY)了
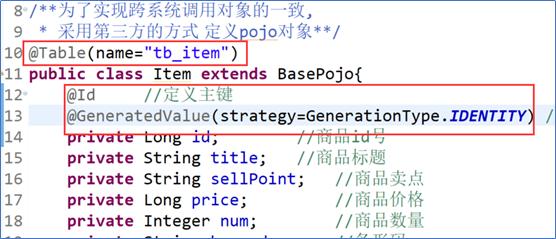
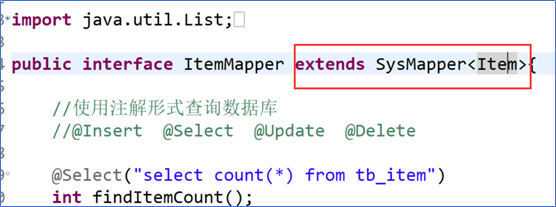
2.定义操作数据库的Dao层,继承SysMapper<Item>,这里要引入通用mapper的.jar依赖。只能进行普通的增删改查
复杂的话,还是自己写sql语句吧!
<!-- 通用Mapper -->
<dependency>
<groupId>com.github.abel533</groupId>
<artifactId>mapper</artifactId>
<version>${mapper.version}</version>
</dependency>