尺度空间(scale space)理论
要理解多尺度,首先要知道什么是尺度空间。xiaowei一文中提到,自然界中的物体呈现出不同的形态,需要不同的尺度观测。比如,建筑物用“米”测量,原子用“纳米”。比较形象的是,在平常使用的Google地图,可以滑动鼠标来改变地图的尺度;照相机通过调焦,将景物拉近拉远。尺度空间中各尺度图像的模糊程度逐渐变大,模拟了景物由近到远在视网膜形成过程。
为什么要讨论尺度空间?因为计算机在不知道图像尺寸的情况下,需要考虑多尺度以获取兴趣物体的最佳尺度。同时,在一幅图像的不同尺度下检测出相同的关键点来匹配,即尺度不变性。
尺度空间表达——高斯模糊
David Lowe 2004年 在Int. Journal of Computer Vision 的经典论文(Distinctive Image Features from Scale-Invariant Keypoints)中,对尺度空间的定义:
“It has been shown by Koenderink (1984) and Lindeberg (1994) that under a variety of reasonable assumptions the only possible scale-space kernel is the Gaussian function. Therefore, the scale space of an image is defined as a function, L(x, y, σ), that is produced from the convolution of a variable-scale Gaussian, G(x, y, σ), with an input image, I (x, y)."
抽取要点:
1. 高斯核是唯一可以产生多尺度空间的核;
2. 一幅图像的尺度空间 L(x, y, σ), 定义为原始图像 I(x,y) 与一个可变尺度的2维高斯函数G(x, y, σ)卷积运算。
即尺度空间形式表示为: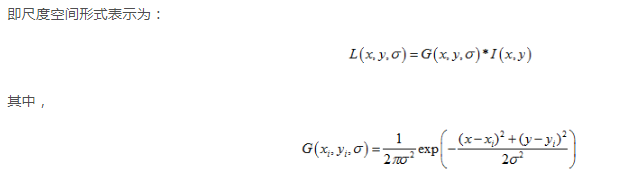

多尺度和多分辨率的区别
最大的不同:
尺度空间表达是由不同高斯核平滑卷积得到,在所有尺度上有相同的分辨率;
而(金字塔)多分辨率表达每层分辨率减少固定比率。
所以,(金字塔)多分辨率生成较快,且占用存储空间少;而多尺度表达随着尺度参数的增加冗余信息也变多。
多尺度表达的优点在于图像的局部特征可以用简单的形式在不同尺度上描述;而(金字塔)多分辨的表达没有理论基础,难以分析图像局部特征。
1. 比如有一幅图像,里面有房子有车有人,在这整张图上提取特征,提取的是全局的特征;现在,截取图像的一部分,比如截取汽车的部分,并将其放大至与原图相同的尺寸,在此时截取后放大的图上提取特征,提取的是整幅图像中某一部分的详细特征。
2. 或者,例如在进行卷积时,如图(随便截的图),分别提取出第三、四、五层卷积得到的特征图,然后将他们缩放到同一尺寸,也是一种多尺寸的表现。其中越深的卷积层提取出的特征图越抽象,提取到的特征更高级。
使用多尺度,就可以提取更全面的信息,既有全局的整体信息,又有局部的详细信息