转载自:https://blog.csdn.net/PTkin/article/details/50563831
本文转载自大神编程随想的博客。阅读原文需要科学上网,建议有条件者直接阅读原文,本文转载只为方便墙内阅读与存档学习。
原文传送门:
扫盲 HTTPS 和 SSL/TLS 协议[0]:引子 @ 编程随想的博客
扫盲 HTTPS 和 SSL/TLS 协议[1]:背景知识、协议的需求、设计的难点 @ 编程随想的博客
扫盲 HTTPS 和 SSL/TLS 协议[2]:可靠密钥交换的原理 @ 编程随想的博客
注:作者的本系列文章本打算写多篇,不过截至转载本文,包括引子在内一共完成了3篇,故只转此3篇。
扫盲 HTTPS 和 SSL/TLS 协议
[0]:引子
今天这篇算是补之前的欠债——俺在4年前写过几篇关于 CA 证书的扫盲(“这里”和“这里”),之后有不止一位热心读者建议俺写一篇关于 HTTPS 的扫盲。因为俺比较懒,当时没动笔,拖了2-3年,都有点忘了。正好今年出了两个跟 HTTPS 相关的高危漏洞(Heartbleed 和 PODDLE),于是俺又想起这事儿。
本来想单独写一篇。等写完“背景知识”这一章节,发现篇幅已经很长了。所以就再开一个系列吧。
事先声明:
既然叫做“扫盲”,所以俺不会讲太具体的“技术实现细节”(当然,更不会去讲“代码实现”)。本系列侧重于:尽可能通俗地介绍“设计思路”、“实现原理”,最后再聊聊“针对 HTTPS 的攻击手法”和“相关的安全防范措施”。初步计划写3-4篇。
虽然是扫盲,或许也能让 IT 技术人员从中获益——因为俺发现:连安全行业的某些程序员,对 HTTPS 的原理也所知甚少。
为了方便阅读,把本系列帖子的目录整理如下(需翻墙):
- 背景知识、协议的需求、设计的难点
- 可靠密钥交换的原理
- SSL/TLS 协议的实现
- 针对 HTTPS 的各种攻击手法
- 各种相应的防范措施
[1]:背景知识、协议的需求、设计的难点
文章目录
- 相关背景知识
- HTTPS 协议的需求是啥?
- 设计 HTTPS 协议的主要难点
- 结尾
- 相关背景知识
要说清楚 HTTPS 协议的实现原理,至少需要如下几个背景知识。
- 大致了解几个基本术语(HTTPS、SSL、TLS)的含义
- 大致了解 HTTP 和 TCP 的关系(尤其是“短连接”VS“长连接”)
- 大致了解加密算法的概念(尤其是“对称加密与非对称加密”的区别)
- 大致了解 CA 证书的用途
考虑到很多技术菜鸟可能不了解上述背景,俺先用最简短的文字描述一下。如果你自认为不是菜鸟,请略过本章节,直接去看“HTTPS 协议的需求”。
先澄清几个术语——HTTPS、SSL、TLS
1. “HTTP”是干嘛用滴?
首先,HTTP 是一个网络协议,是专门用来帮你传输 Web 内容滴。关于这个协议,就算你不了解,至少也听说过吧?比如你访问俺的博客的主页,浏览器地址栏会出现如下的网址
http://program-think.blogspot.com/
俺加了粗体的部分就是指 HTTP 协议。大部分网站都是通过 HTTP 协议来传输 Web 页面、以及 Web 页面上包含的各种东东(图片、CSS 样式、JS 脚本)。
2. “SSL/TLS”是干嘛用滴?
SSL 是洋文“Secure Sockets Layer”的缩写,中文叫做“安全套接层”。它是在上世纪90年代中期,由网景公司设计的。(顺便插一句,网景公司不光发明了 SSL,还发明了很多 Web 的基础设施——比如“CSS 样式表”和“JS 脚本”)
为啥要发明 SSL 这个协议捏?因为原先互联网上使用的 HTTP 协议是明文的,存在很多缺点——比如传输内容会被偷窥(嗅探)和篡改。发明 SSL 协议,就是为了解决这些问题。
到了1999年,SSL 因为应用广泛,已经成为互联网上的事实标准。IETF 就在那年把 SSL 标准化。标准化之后的名称改为 TLS(是“Transport Layer Security”的缩写),中文叫做“传输层安全协议”。
很多相关的文章都把这两者并列称呼(SSL/TLS),因为这两者可以视作同一个东西的不同阶段。
3. “HTTPS”是啥意思?
解释完 HTTP 和 SSL/TLS,现在就可以来解释 HTTPS 啦。咱们通常所说的 HTTPS 协议,说白了就是“HTTP 协议”和“SSL/TLS 协议”的组合。你可以把 HTTPS 大致理解为——“HTTP over SSL”或“HTTP over TLS”(反正 SSL 和 TLS 差不多)。
再来说说 HTTP 协议的特点
作为背景知识介绍,还需要再稍微谈一下 HTTP 协议本身的特点。HTTP 本身有很多特点,考虑到篇幅有限,俺只谈那些和 HTTPS 相关的特点。
1. HTTP 的版本和历史
如今咱们用的 HTTP 协议,版本号是 1.1(也就是 HTTP 1.1)。这个 1.1 版本是1995年底开始起草的(技术文档是 RFC2068),并在1999年正式发布(技术文档是 RFC2616)。
在 1.1 之前,还有曾经出现过两个版本“0.9 和 1.0”,其中的 HTTP 0.9 【没有】被广泛使用,而 HTTP 1.0 被广泛使用过。
另外,据说明年(2015)IETF 就要发布 HTTP 2.0 的标准了。俺拭目以待。
(转载者注:截至2016年1月,HTTP2.0未正式发布)
2. HTTP 和 TCP 之间的关系
简单地说,TCP 协议是 HTTP 协议的基石——HTTP 协议需要依靠 TCP 协议来传输数据。
在网络分层模型中,TCP 被称为“传输层协议”,而 HTTP 被称为“应用层协议”。有很多常见的应用层协议是以 TCP 为基础的,比如“FTP、SMTP、POP、IMAP”等。
TCP 被称为“面向连接”的传输层协议。关于它的具体细节,俺就不展开了(否则篇幅又失控了)。你只需知道:传输层主要有两个协议,分别是 TCP 和 UDP。TCP 比 UDP 更可靠。你可以把 TCP 协议想象成某个水管,发送端这头进水,接收端那头就出水。并且 TCP 协议能够确保,先发送的数据先到达(与之相反,UDP 不保证这点)。
3. HTTP 协议如何使用 TCP 连接?
HTTP 对 TCP 连接的使用,分为两种方式:俗称“短连接”和“长连接”(“长连接”又称“持久连接”,洋文叫做“Keep-Alive”或“Persistent Connection”)
假设有一个网页,里面包含好多图片,还包含好多【外部的】CSS 文件和 JS 文件。在“短连接”的模式下,浏览器会先发起一个 TCP 连接,拿到该网页的 HTML 源代码(拿到 HTML 之后,这个 TCP 连接就关闭了)。然后,浏览器开始分析这个网页的源码,知道这个页面包含很多外部资源(图片、CSS、JS)。然后针对【每一个】外部资源,再分别发起一个个 TCP 连接,把这些文件获取到本地(同样的,每抓取一个外部资源后,相应的 TCP 就断开)
相反,如果是“长连接”的方式,浏览器也会先发起一个 TCP 连接去抓取页面。但是抓取页面之后,该 TCP 连接并不会立即关闭,而是暂时先保持着(所谓的“Keep-Alive”)。然后浏览器分析 HTML 源码之后,发现有很多外部资源,就用刚才那个 TCP 连接去抓取此页面的外部资源。
在 HTTP 1.0 版本,【默认】使用的是“短连接”(那时候是 Web 诞生初期,网页相对简单,“短连接”的问题不大);
到了1995年底开始制定 HTTP 1.1 草案的时候,网页已经开始变得复杂(网页内的图片、脚本越来越多了)。这时候再用短连接的方式,效率太低下了(因为建立 TCP 连接是有“时间成本”和“CPU 成本”滴)。所以,在 HTTP 1.1 中,【默认】采用的是“Keep-Alive”的方式。
关于“Keep-Alive”的更多介绍,可以参见维基百科词条(在“这里”)
谈谈“对称加密”和“非对称加密”的概念
1. 啥是“加密”和“解密”?
通俗而言,你可以把“加密”和“解密”理解为某种【互逆的】数学运算。就好比“加法和减法”互为逆运算、“乘法和除法”互为逆运算。
“加密”的过程,就是把“明文”变成“密文”的过程;反之,“解密”的过程,就是把“密文”变为“明文”。在这两个过程中,都需要一个关键的东东——叫做“密钥”——来参与数学运算。
2. 啥是“对称加密”?
所谓的“对称加密技术”,意思就是说:“加密”和“解密”使用【相同的】密钥。这个比较好理解。就好比你用 7zip 或 WinRAR 创建一个带密码(口令)的加密压缩包。当你下次要把这个压缩文件解开的时候,你需要输入【同样的】密码。在这个例子中,密码/口令就如同刚才说的“密钥”。
3. 啥是“非对称加密”?
所谓的“非对称加密技术”,意思就是说:“加密”和“解密”使用【不同的】密钥。这玩意儿比较难理解,也比较难想到。当年“非对称加密”的发明,还被誉为“密码学”历史上的一次革命。
由于篇幅有限,对“非对称加密”这个话题,俺就不展开了。有空的话,再单独写一篇扫盲。
4. 各自有啥优缺点?
看完刚才的定义,很显然:(从功能角度而言)“非对称加密”能干的事情比“对称加密”要多。这是“非对称加密”的优点。但是“非对称加密”的实现,通常需要涉及到“复杂数学问题”。所以,“非对称加密”的性能通常要差很多(相对于“对称加密”而言)。
这两者的优缺点,也影响到了 SSL 协议的设计。
CA 证书的原理及用途
关于这方面,请看俺4年前写的《数字证书及CA的扫盲介绍》。这里就不再重复唠叨了,免得篇幅太长。
HTTPS 协议的需求是啥?
花了好多口水,终于把背景知识说完了。下面正式进入正题。先来说说当初设计 HTTPS 是为了满足哪些需求?
很多介绍 HTTPS 的文章一上来就给你讲实现细节。个人觉得:这是不好的做法。早在2009年开博的时候,发过一篇《学习技术的三部曲:WHAT、HOW、WHY》,其中谈到“WHY 型问题”的重要性。一上来就给你讲协议细节,你充其量只能知道 WHAT 和 HOW,无法理解 WHY。俺在前一个章节讲了“背景知识”,在这个章节讲了“需求”,这就有助于你理解:当初为什么要设计成这样?——这就是 WHY 型的问题。
兼容性
因为是先有 HTTP 再有 HTTPS。所以,HTTPS 的设计者肯定要考虑到对原有 HTTP 的兼容性。
这里所说的兼容性包括很多方面。比如已有的 Web 应用要尽可能无缝地迁移到 HTTPS;比如对浏览器厂商而言,改动要尽可能小;……
基于“兼容性”方面的考虑,很容易得出如下几个结论:
-
HTTPS 还是要基于 TCP 来传输
(如果改为 UDP 作传输层,无论是 Web 服务端还是浏览器客户端,都要大改,动静太大了) -
单独使用一个新的协议,把 HTTP 协议包裹起来
(所谓的“HTTP over SSL”,实际上是在原有的 HTTP 数据外面加了一层 SSL 的封装。HTTP 协议原有的 GET、POST 之类的机制,基本上原封不动)
打个比方:如果原来的 HTTP 是塑料水管,容易被戳破;那么如今新设计的 HTTPS 就像是在原有的塑料水管之外,再包一层金属水管。一来,原有的塑料水管照样运行;二来,用金属加固了之后,不容易被戳破。
可扩展性
前面说了,HTTPS 相当于是“HTTP over SSL”。
如果 SSL 这个协议在“可扩展性”方面的设计足够牛逼,那么它除了能跟 HTTP 搭配,还能够跟其它的应用层协议搭配。岂不美哉?
现在看来,当初设计 SSL 的人确实比较牛。如今的 SSL/TLS 可以跟很多常用的应用层协议(比如:FTP、SMTP、POP、Telnet)搭配,来强化这些应用层协议的安全性。
接着刚才打的比方:如果把 SSL/TLS 视作一根用来加固的金属管,它不仅可以用来加固输水的管道,还可以用来加固输煤气的管道。
保密性(防泄密)
HTTPS 需要做到足够好的保密性。
说到保密性,首先要能够对抗嗅探(行话叫 Sniffer)。所谓的“嗅探”,通俗而言就是监视你的网络传输流量。如果你使用明文的 HTTP 上网,那么监视者通过嗅探,就知道你在访问哪些网站的哪些页面。
嗅探是最低级的攻击手法。除了嗅探,HTTPS 还需要能对抗其它一些稍微高级的攻击手法——比如“重放攻击”(后面讲协议原理的时候,会再聊)。
完整性(防篡改)
除了“保密性”,还有一个同样重要的目标是“确保完整性”。关于“完整性”这个概念,在之前的博文《扫盲文件完整性校验——关于散列值和数字签名》中大致提过。健忘的同学再去温习一下。
在发明 HTTPS 之前,由于 HTTP 是明文的,不但容易被嗅探,还容易被篡改。
举个例子:
比如咱们天朝的网络运营商(ISP)都比较流氓,经常有网友抱怨说访问某网站(本来是没有广告的),竟然会跳出很多中国电信的广告。为啥会这样捏?因为你的网络流量需要经过 ISP 的线路才能到达公网。如果你使用的是明文的 HTTP,ISP 很容易就可以在你访问的页面中植入广告。
所以,当初设计 HTTPS 的时候,还有一个需求是“确保 HTTP 协议的内容不被篡改”。
真实性(防假冒)
在谈到 HTTPS 的需求时,“真实性”经常被忽略。其实“真实性”的重要程度不亚于前面的“保密性”和“完整性”。
举个例子:
你因为使用网银,需要访问该网银的 Web 站点。那么,你如何确保你访问的网站确实是你想访问的网站?(这话有点绕口令)
有些天真的同学会说:通过看网址里面的域名,来确保。为啥说这样的同学是“天真的”?因为 DNS 系统本身是不可靠的(尤其是在设计 SSL 的那个年代,连 DNSSEC 都还没发明)。由于 DNS 的不可靠(存在“域名欺骗”和“域名劫持”),你看到的网址里面的域名【未必】是真实滴!
(不了解“域名欺骗”和“域名劫持”的同学,可以参见俺之前写的《扫盲 DNS 原理,兼谈“域名劫持”和“域名欺骗/域名污染”》)
所以,HTTPS 协议必须有某种机制来确保“真实性”的需求(至于如何确保,后面会细聊)。
性能
再来说最后一个需求——性能。
引入 HTTPS 之后,【不能】导致性能变得太差。否则的话,谁还愿意用?
为了确保性能,SSL 的设计者至少要考虑如下几点:
-
如何选择加密算法(“对称”or“非对称”)?
-
如何兼顾 HTTP 采用的“短连接”TCP 方式?
(SSL 是在1995年之前开始设计的,那时候的 HTTP 版本还是 1.0,默认使用的是“短连接”的 TCP 方式——默认不启用 Keep-Alive)
小结
以上就是设计 SSL 协议时,必须兼顾的各种需求。后面聊协议的实现时,俺会拿 SSL 协议的特点跟前面的需求作对照。看看这些需求是如何一一满足滴。
设计 HTTPS 协议的主要难点
设计 HTTPS 这个协议,有好几个难点。俺个人认为最大的难点在于“密钥交换”。
在传统的密码学场景中,假如张三要跟李四建立一个加密通讯的渠道,双方事先要约定好使用哪种加密算法?同时也要约定好使用的密钥是啥?在这个场景中,加密算法的【类型】让旁人知道,没太大关系。但是密钥【千万不能】让旁人知道。一旦旁人知道了密钥,自然就可以破解通讯的密文,得到明文。
好,现在回到 HTTPS 的场景。
当你访问某个公网的网站,你的浏览器和网站的服务器之间,如果要建立加密通讯,必然要商量好双方使用啥算法,啥密钥。——在网络通讯术语中,这个过程称之为“握手/handshake”。在握手阶段,因为加密方式还没有协商好,所以握手阶段的通讯必定是【明文】滴!既然是明文,自然有可能被第三方偷窥到。然后,还要考虑到双方之间隔着一个互联网,什么样的偷窥都可能发生。
因此,在握手的过程中,如何做到安全地交换密钥信息,而不让周围的第三方看到。这就是设计 HTTPS 最大的难点。
结尾
本文费这么多口水,来介绍 HTTPS 的“需求”和“难点”,为啥捏?因为只有当你了解这些,后面介绍 SSL/TLS 的实现原理时,你才能理解——当初为啥要把协议设计成这个样子。
[2]:可靠密钥交换的原理
文章目录
- 先插播一个安全通告
- 方案1——单纯用“对称加密算法”的可行性
- 方案2——单纯用“非对称加密算法”的风险
- 方案2失败的根源——缺乏【可靠的】身份认证
- 身份认证的几种方式
- 如何解决 SSL 的身份认证问题——CA 的引入
- 方案3——基于 CA 证书进行密钥交换
- 关于“客户端证书”
- 结尾
先插播一个安全通告
就在本系列刚开播之后没几天(11月11日),微软爆了一个跟 SSL/TLS 相关的高危漏洞,影响【几乎所有的】Windows 平台。至此,【所有】主流的 SSL/TLS 协议栈(至少包括:开源的 OpenSSL、开源的 GnuTLS、微软的 SSP、苹果的 SecureTransport),全都在今年爆了高危漏洞。(看来俺这个系列生逢其时啊)
个人觉得:【2014年】必将在信息安全历史上留下醒目的记录。
用 Windows 系统的同学,这几天要尽快升级微软的“安全更新”。因为该漏洞会导致“远程代码执行”,非常危险。
(微软的公告中没有提及 Win2000 和 WinXP 是因为这俩已经过了“产品支持周期”。不等于说这俩没问题)
在本系列的前一篇,已经介绍了相关的背景知识以及设计 SSL 需要考虑的需求。当时俺提到:设计 HTTPS 的最大难点(没有之一)是——如何在互联网上进行安全的“密钥交换”。今天就来讲讲密钥交换的原理(暂不谈技术实现)。
方案1——单纯用“对称加密算法”的可行性
首先简单阐述一下,“单纯用对称加密”为啥是【不可行】滴。
如果“单纯用对称加密”,浏览器和网站之间势必先要交换“对称加密的密钥”。
如果这个密钥直接用【明文】传输,很容易就会被第三方(有可能是“攻击者”)偷窥到;如果这个密钥用密文传输,那就再次引入了“如何交换加密密钥”的问题——这就变成“先有鸡还是先有蛋”的循环逻辑了。
所以,【单纯用】对称加密,是没戏滴。
方案2——单纯用“非对称加密算法”的风险
说完“对称加密”,再来说说“非对称加密”。
在前面的“背景知识”中,已经大致介绍过“非对称加密”的特点——“加密和解密采用不同的密钥”。基于这个特点,可以避开前面提到的“循环逻辑”的困境。大致的步骤如下:
第1步
网站服务器先基于“非对称加密算法”,随机生成一个“密钥对”(为叙述方便,称之为“k1 和 k2”)。因为是随机生成的,目前为止,只有网站服务器才知道 k1 和 k2。第2步
网站把 k1 保留在自己手中,把 k2 用【明文】的方式发送给访问者的浏览器。
因为 k2 是明文发送的,自然有可能被偷窥。不过不要紧。即使偷窥者拿到 k2,也【很难】根据 k2 推算出 k1
(这一点是由“非对称加密算法”从数学上保证的)。第3步
浏览器拿到 k2 之后,先【随机生成】第三个对称加密的密钥(简称 k)。
然后用 k2 加密 k,得到 k’(k’ 是 k 的加密结果)
浏览器把 k’ 发送给网站服务器。由于 k1 和 k2 是成对的,所以只有 k1 才能解密 k2 的加密结果。
因此这个过程中,即使被第三方偷窥,第三方也【无法】从 k’ 解密得到 k第4步
网站服务器拿到 k’ 之后,用 k1 进行解密,得到 k
至此,浏览器和网站服务器就完成了密钥交换,双方都知道 k,而且【貌似】第三方无法拿到 k
然后,双方就可以用 k 来进行数据双向传输的加密。
现在,给大伙儿留一个思考时间——你觉得上述过程是否严密?如果不严密,漏洞在哪里?
建
议
你
思
考
一
柱
香
的
时
间
,
再
来
看
答
案
OK,现在俺来揭晓答案。“方案2”依然是不安全滴——虽然“方案2”可以在一定程度上防止网络数据的【偷窥/嗅探】,但是【无法】防范网络数据的【篡改】。
假设有一个攻击者处于“浏览器”和“网站服务器”的通讯线路之间,并且这个攻击者具备“修改双方传输数据”的能力。那么,这个攻击者就可以攻破“方案2”。具体的攻击过程如下:
第1步
这一步跟原先一样——服务器先随机生成一个“非对称的密钥对”k1 和 k2(此时只有网站知道 k1 和 k2)第2步
当网站发送 k2 给浏览器的时候,攻击者截获 k2,保留在自己手上。
然后攻击者自己生成一个【伪造的】密钥对(以下称为 pk1 和 pk2)。
攻击者把 pk2 发送给浏览器。第3步
浏览器收到 pk2,以为 pk2 就是网站发送的。
浏览器不知情,依旧随机生成一个对称加密的密钥 k,然后用 pk2 加密 k,得到密文的 k’
浏览器把 k’ 发送给网站。
(以下是关键)
发送的过程中,再次被攻击者截获。
因为 pk1 pk2 都是攻击者自己生成的,所以攻击者自然就可以用 pk1 来解密 k’ 得到 k
然后,攻击者拿到 k 之后,用之前截获的 k2 重新加密,得到 k”,并把 k” 发送给网站。第4步
网站服务器收到了 k” 之后,用自己保存的 k1 可以正常解密,所以网站方面不会起疑心。
至此,攻击者完成了一次漂亮的偷梁换柱,而且让双方都没有起疑心。
上述过程,也就是传说中大名鼎鼎的“中间人攻击”。洋文叫做“Man-In-The-Middle attack”。缩写是 MITM。
“中间人攻击”有很多种“类型”,刚才演示的是针对“【单纯的】非对称加密”的中间人攻击。至于“中间人攻击”的其它类型,俺在本系列的后续博文中,还会再提到。
为了更加形象,补充两张示意图,分别对应“偷窥模式”和“中间人模式”。让你更直观地体会两者的差异。
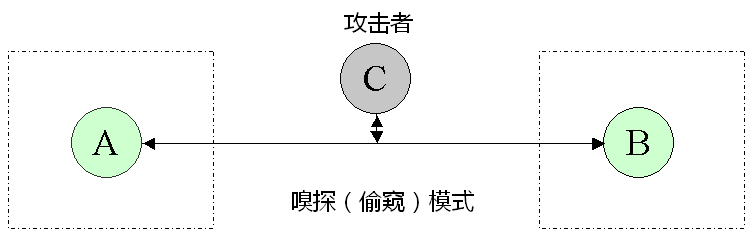
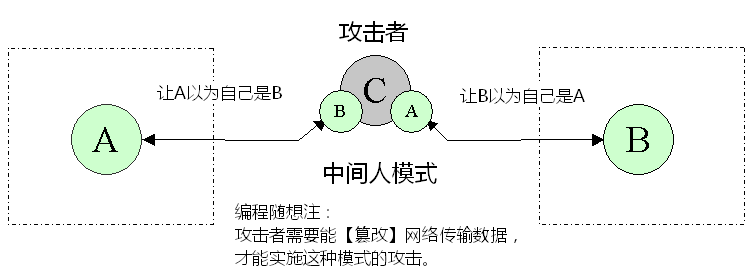
方案2失败的根源——缺乏【可靠的】身份认证
为啥“方案2”会失败?
除了俺在图中提到的“攻击者具备篡改数据的能力”,还有另一点关键点——“方案2缺乏身份认证机制”。
正是因为“缺乏身份认证机制”,所以当攻击者一开始截获 k2 并把自己伪造的 pk2 发送给浏览器时,浏览器无法鉴别:自己收到的密钥是不是真的来自于网站服务器。
假如具备某种【可靠的】身份认证机制,即使攻击者能够篡改数据,但是篡改之后的数据很容易被识破。那篡改也就失去了意义。
身份认证的几种方式
下面,俺来介绍几种常见的“身份认证原理”。
基于某些“私密的共享信息”
为了解释“私密的共享信息”这个概念,咱们先抛开“信息安全”,谈谈日常生活中的某个场景。
假设你有一个久未联系的老朋友。因为时间久远,你已经没有此人的联系方式了。某天,此人突然给你发了一封电子邮件。
那么,你如何确保——发邮件的人确实是你的老朋友捏?
有一个办法就是:你用邮件向对方询问某个私密的事情(这个事情只有你和你的这个朋友知道,其他人不知道)。如果对方能够回答出来,那么对方【很有可能】确实是你的老朋友。
从这个例子可以看出,如果通讯双方具有某些“私密的共享信息”(只有双方知道,第三方不知道),就能以此为基础,进行身份认证,从而建立信任。
基于双方都信任的“公证人”
“私密的共享信息”,通常需要双方互相比较熟悉,才行得通。如果双方本来就互不相识,如何进行身份认证以建立信任关系捏?
这时候还有另一个办法——依靠双方都信任的某个“公证人”来建立信任关系。
如今 C2C 模式的电子商务,其实用的就是这种方式——由电商平台充当公证人,让买家与卖家建立某种程度的信任关系。
考虑到如今的网购已经相当普及,大伙儿应该对这类模式很熟悉吧。所以俺就不浪费口水了。
如何解决 SSL 的身份认证问题——CA 的引入
说完身份认证的方式/原理,再回到 SSL/TLS 的话题上。
对于 SSL/TLS 的应用场景,由于双方(“浏览器”和“网站服务器”)通常都是互不相识的,显然不可能采用第一种方式(私密的共享信息),而只能采用第二种方式(依赖双方都信任的“公证人”)。
那么,谁来充当这个公证人捏?这时候,CA 就华丽地登场啦。
所谓的 CA,就是“数字证书认证机构”的缩写,洋文全称叫做“Certificate Authority”。关于 CA 以及 CA 颁发的“CA 证书”,俺已经写过一篇教程:《数字证书及CA的扫盲介绍》,介绍其基本概念和功能。所以,此处就不再重复唠叨了。
如果你看完那篇 CA 的扫盲,你自然就明白——CA 完全有资格和能力,充当这个“公证人”的角色。
方案3——基于 CA 证书进行密钥交换
其实“方案3”跟“方案2”很像的,主要差别在于——“方案3”增加了“CA 数字证书”这个环节。所谓的数字证书,技术上依赖的还是前面提到的“非对称加密”。为了描述“CA 证书”在 SSL/TLS 中的作用,俺大致说一下原理(仅仅是原理,具体的技术实现要略复杂些):
第1步(这是“一次性”的准备工作)
网站方面首先要花一笔银子,在某个 CA 那里购买一个数字证书。
该证书通常会对应几个文件:其中一个文件包含公钥,还有一个文件包含私钥。
此处的“私钥”,相当于“方案2”里面的 k1;而“公钥”类似于“方案2”里面的 k2。
网站方面必须在 Web 服务器上部署这两个文件。所谓的“公钥”,顾名思义就是可以公开的 key;而所谓的“私钥”就是私密的 key。
其实前面已经说过了,这里再唠叨一下:“非对称加密算法”从数学上确保了——即使你知道某个公钥,也很难(不是不可能,是很难)根据此公钥推导出对应的私钥。
第2步
当浏览器访问该网站,Web 服务器首先把包含公钥的证书发送给浏览器。第3步
浏览器验证网站发过来的证书。如果发现其中有诈,浏览器会提示“CA 证书安全警告”。
由于有了这一步,就大大降低了(注意:是“大大降低”,而不是“彻底消除”)前面提到的“中间人攻击”的风险。为啥浏览器能发现 CA 证书是否有诈?
因为正经的 CA 证书,都是来自某个权威的 CA。如果某个 CA 足够权威,那么主流的操作系统(或浏览器)会内置该 CA 的“根证书”。(比如 Windows 中就内置了几十个权威 CA 的根证书)
因此,浏览器就可以利用系统内置的根证书,来判断网站发过来的 CA 证书是不是某个 CA 颁发的。
(关于“根证书”和“证书信任链”的概念,请参见之前的教程《数字证书及CA的扫盲介绍》)第4步
如果网站发过来的 CA 证书没有问题,那么浏览器就从该 CA 证书中提取出“公钥”。
然后浏览器随机生成一个“对称加密的密钥”(以下称为 k)。用 CA 证书的公钥加密 k,得到密文 k’
浏览器把 k’ 发送给网站。第5步
网站收到浏览器发过来的 k’,用服务器上的私钥进行解密,得到 k。
至此,浏览器和网站都拥有 k,“密钥交换”大功告成啦。
关于“客户端证书”
前面介绍的“方案3”仅仅使用了“服务端证书”——通过服务端证书来确保服务器不是假冒的。
除了“服务端证书”,在某些场合中还会涉及到“客户端证书”。所谓的“客户端证书”就是用来证明客户端(浏览器端)访问者的身份。
比如在某些金融公司的内网,你的电脑上必须部署“客户端证书”,才能打开重要服务器的页面。
由于本文主要介绍的是【公网】上的场景,这种场景下大都【不需要】“客户端证书”。所以,对“客户端证书”这个话题,俺就偷个懒,略过不提。
结尾
可能有同学会问:那么“方案3”是否就足够严密,无懈可击了捏?
俺只能说,“方案3”【从理论上讲】没有明显的漏洞。目前的 SSL/TLS 大致采用的就是这个方案。
但是,“理论”一旦落实到“实践”,往往是有差距滴,会引出新的问题。套用某 IT 大牛的名言,就是:In theory, there is no difference between theory and practice. But in practice, there is.
所以在本系列的后续博文,俺还会再来介绍“针对 SSL/TLS 的种种攻击方式”以及“对应的防范措施”。
下一篇,打算大致说一下“协议的实现”。
版权声明
本博客所有的原创文章,作者皆保留版权。转载必须包含本声明,保持本文完整,并以超链接形式注明作者编程随想和本文原始地址:
扫盲 HTTPS 和 SSL/TLS 协议[0]:引子 @ 编程随想的博客