今天面试字节跳动的视觉实习岗,问到了有序数组的查找方式,这里总结一下。
查找定义:根据给定的某个值,在数列中确定一个其关键字等于给定值的数据元素(或记录)。
有序表:若线性表中的数据元素相互之间可以比较,并且数据元素在表中依值非递减或非递增有序排列,即ai ai-1或ai ai-1 (i=1,2,3,…,n),则称该线性表为有序表。
有序查找:被查找数列必须为有序数列(有序表)。
平均查找长度(Average Search Length,ASL):需和指定key进行比较的关键字的个数的期望值,称为查找算法在查找成功时的平均查找长度。
对于含有n个数据元素的数列,查找成功的平均查找长度为:
:数列中第i个数据元素的概率。
:找到第i个数据元素时已经比较过的次数。
一般情况下,各元素概率相等
,则
顺序查找
思想:
把数列看作无序,从一端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相比较,若相等则表示查找成功;若扫描结束仍没有找到关键字等于k的结点,表示查找失败。
时间复杂度分析:
查找成功时的平均查找长度为:(没有先验信息,每个数据元素的概率相等)
;
当查找不成功时,需要n次比较,时间复杂度为O(n);
综上,顺序查找的时间复杂度为O(n)。
c++代码:
int array[]={1,2,3,4,9};
int sequenceSearch(int* array,int n,int val){
for(int i=0;i<n;i++){
if(array[i]==val) return i;
}
return -1;
}
python代码:
array = [1,2,3,4,9]
def sequenceSearch(array,val):
for i in range(len(array)):
if array[i] == val:
return i
return -1
二分查找
二分查找是一种必须应用于有序数列的查找方式。若数列无序,则需要先对数列进行排序。
基本思想: 也称为是折半查找。用给定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。
时间复杂度分析:如果一直没有查找到,待查找的子线性表长度依次为
,
为查找次数。
最坏情况下,线性表中没有待查找元素,此时
,则
。
平均查找长度:
折半查找的过程,可用二叉树来描述,二叉树中的每个结点对应有序表中的一个记录,结点中的值为该记录在表中的位置。通常称这个描述折半查找二叉树的过程称为折半查找判定树。
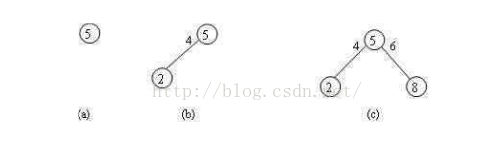
例如,长度为10的折半查找判定树的具体生成过程:
遵循左孩子结点<根结点<右孩子结点
- 在长度为10的有序表中进行折半查找,不论查找哪个记录,都必须和中间记录进行比较,而中间记录为(1+10)/2 =5 (注意要取整) 即判定数的的根结点为5,如图7-2(a)所示。
- 考虑判定树的左子树,即将查找区域调整到左半区,此时的查找区间为[1,4],那么中间值为(1+4)/2 =2 (注意要取整) ,所以做孩子根结点为2,如图7-2(b)所示。
- 考虑判定树的右子树,即将查找区域调整到右半区,此时的查找区间为[6,10],那么中间值为(6+10)/2 =8 (注意要取整) ,所以做孩子根结点为8,如图7-2(c)所示。
- 重复以上步骤,依次去确定左右孩子。
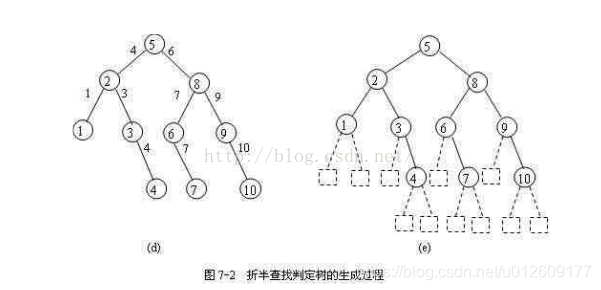
1.折半查找是一棵二叉排序树,每个根结点的值都大于左子树的所有结点的值,小于右子树所有结点的值。
2.折半查找判定数中的结点都是查找成功的情况,将每个结点的空指针指向一个实际上不存在的结点————外结点,所有外界点都是查找不成功的情况,如图7-2(e)所示。如果有序表的长度为n,则外结点一定有n+1个。
折半查找判定数中,某结点所在的层数就是即将要比较的次数,整个判定树代表的有序表的平均查找长度即为查找每个结点的比较次数之和除以有序表的长度。
例如:长度为10的有序表的平均查找长度为
ASL=(1*1+2*2+3*4+4*3)/10=29/10;
折半查找判定数中,查找不成功的次数即为查找相应外结点与内结点的总的比较次数。查找失败时的有序表的平均查找长度即为查找每个外结点的比较次数之和除以外结点的个数。
如图7-2(e),查找失败时,长度为10的有序表的平均查找长度为
ASL=(3*5+4*6)/11=39/11;
c++代码,递归版本:
int array[]={1,2,3,4,9};
int binarySearch(int* array, int n, int val, int offset = 0)
{
if (n == -1) return -1;
int index = (n - 1) / 2;
if (array[index] == val) return index + offset;
else if (array[index]>val) binarySearch(array, index - 1, val, offset);
else binarySearch(array + index + 1, n - index - 1, val, offset + index + 1);
}
c++代码,版本2
int array[]={1,2,3,4,9};
int binarySearch(int* array, int n, int val)
{
int begin=0,end=n-1,mid;
while(begin<=end)
{
mid=(begin+end)/2;
if(array[mid]==val) return mid;
else if(array[mid]>val) end = mid-1;
else begin = mid +1;
}
return -1;
}
python代码:
array=[1,2,3,4,9]
def binarySearch(array,val):
begin = 0
end = len(array) - 1
mid = 0
while begin<=end:
mid = (begin + end) // 2
if array[mid] == val : return mid
elif array[mid] > val : end = mid - 1
else : begin = mid + 1
return -1
插值查找
Motivation:为什么上述算法一定要是折半,而不是折四分之一或者折更多呢?
打个比方,在英文字典里面查“apple”,你下意识翻开字典是翻前面的书页还是后面的书页呢?如果再让你查“zoo”,你又怎么查?很显然,这里你绝对不会是从中间开始查起,而是有一定目的的往前或往后翻。
同样的,比如要在取值范围1 ~ 10000 之间 100 个元素从小到大均匀分布的数组中查找5, 我们自然会考虑从数组下标较小的开始查找。
经过以上分析,折半查找这种查找方式,不是自适应的(也就是说是傻瓜式的)。二分查找中查找点计算如下:
mid=(low+high)/2, 即mid=low+1/2*(high-low);
通过类比,我们可以将查找的点改进为如下:
mid=low+(key-a[low])/(a[high]-a[low])*(high-low),
也就是将上述的比例参数1/2改进为自适应的,根据关键字在整个有序表中所处的位置,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
基本思想:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,插值查找也属于有序查找。
例子:有1000个records,keys是
,从小到大均匀分布在
之间。现在想找一个记录
,它的key是0.7。
首先,0.7*1000=700,尝试
和
进行比较,发现
的key是0.68,所以
到
不用考虑了。
那下一个比较的点怎么选。代入均匀分布的概率分布函数,计算Y小于等于
的概率,得到(0.7-0.68)/(1-0.68)=0.0675,然后计算0.0675*300=20,所以下一次和
进行比较。
重复上述过程,直到查找成功或查找表为空。
注:对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
时间复杂度分析:
最坏情况下,数据极不均匀,插值查找需要对每个元素比较一次,复杂度为O(n)。
查找成功或者失败的时间复杂度均为O(log2(log2n)),这个证明有时间的话会看看,参考文献给出了相关的链接。
c++代码:
int array[]={1,2,3,4,9};
int InterpolationSearch(int* array, int n, int val)
{
int begin = 0, end = n - 1;
while (begin <= end)
{
if (begin == end) return array[begin] == val ? begin : -1;
else
{
int index = begin + (val - array[begin])*(end - begin + 1) / (array[end] - array[begin]);
if (array[index] == val) return index;
else if (array[index] > val) end = index - 1;
else begin = index + 1;
}
}
return -1;
}
分块查找
分块查找又称索引顺序查找,它是顺序查找的一种改进方法。
算法思想:将n个数据元素"按块有序"划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须"按块有序";即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素,……
算法流程
- 先选取各块中的最大关键字构成一个索引表;
- 查找分两个部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;然后,在已确定的块中用顺序法进行查找。
算法分析
这种带索引表的分块有序表查找的时间性能取决于两步查找时间之和:如前面所述,第一步可以采用简单顺序查找和折半查找之一进行。第二步只能采用简单顺序查找,但由于子表的长度较原表的长度小。因此,其时间性能介于顺序查找和折半查找之间。
参考文献
- 数据结构–七大查找算法总结
https://blog.csdn.net/sayhello_world/article/details/77200009 - 折半查找判定数及平均查找长度
https://blog.csdn.net/zhupengqq/article/details/51837908 - 数据结构—平均查找长度ASL的相关计算技巧 https://blog.csdn.net/zqq_2016/article/details/78578058
- 插值搜索查找的时间复杂度为何是O(loglogN)?
https://www.zhihu.com/question/35997917 - Interpolation Search - A LogLogN Search
http://www.cs.technion.ac.il/~itai/publications/Algorithms/p550-perl.pdf