##CAS登陆流程##。如https://my.oschina.net/aiguozhe/blog/160715中所示。
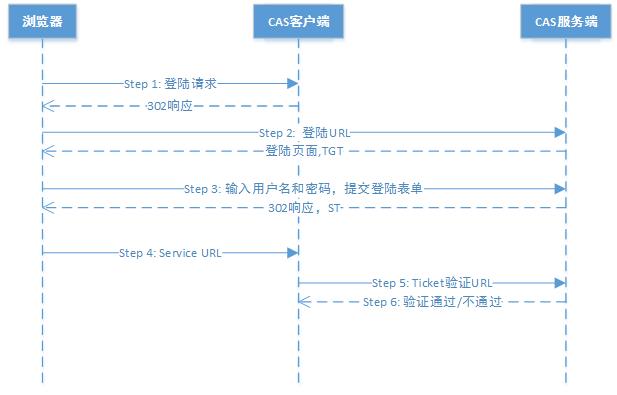
由于CAS不提供rest请求来通过认证。可行的方法是模拟浏览器请求,填入用户名和密码来实现认证流程。
一、通过fiddler抓取登陆过程报文:
Step1:
Request Header:

Response Header:302跳转到认证页面

Step2:
Request Header:

Response Header:

这里上图中的tgt并没有返回到请求端。(流程图有一个小问题)
Step3:
Request Header:

Response Header:

这里认证通过后,生成CASTGC这个cookie,内容是sso服务器缓存的session的key。
并且注意到返回302跳转到一开始需要登陆的地址。后面加上了ticket,(即ST用于CAS客户端和服务器认证)、
Step4:
由于302跳转,继续发出请求。Request Header:

Response Header:

ST认证通过之后,CAS会删掉。最后会跳转到最初访问的页面
-------前方高能预警-------
-------前方高能预警-------
-------前方高能预警-------
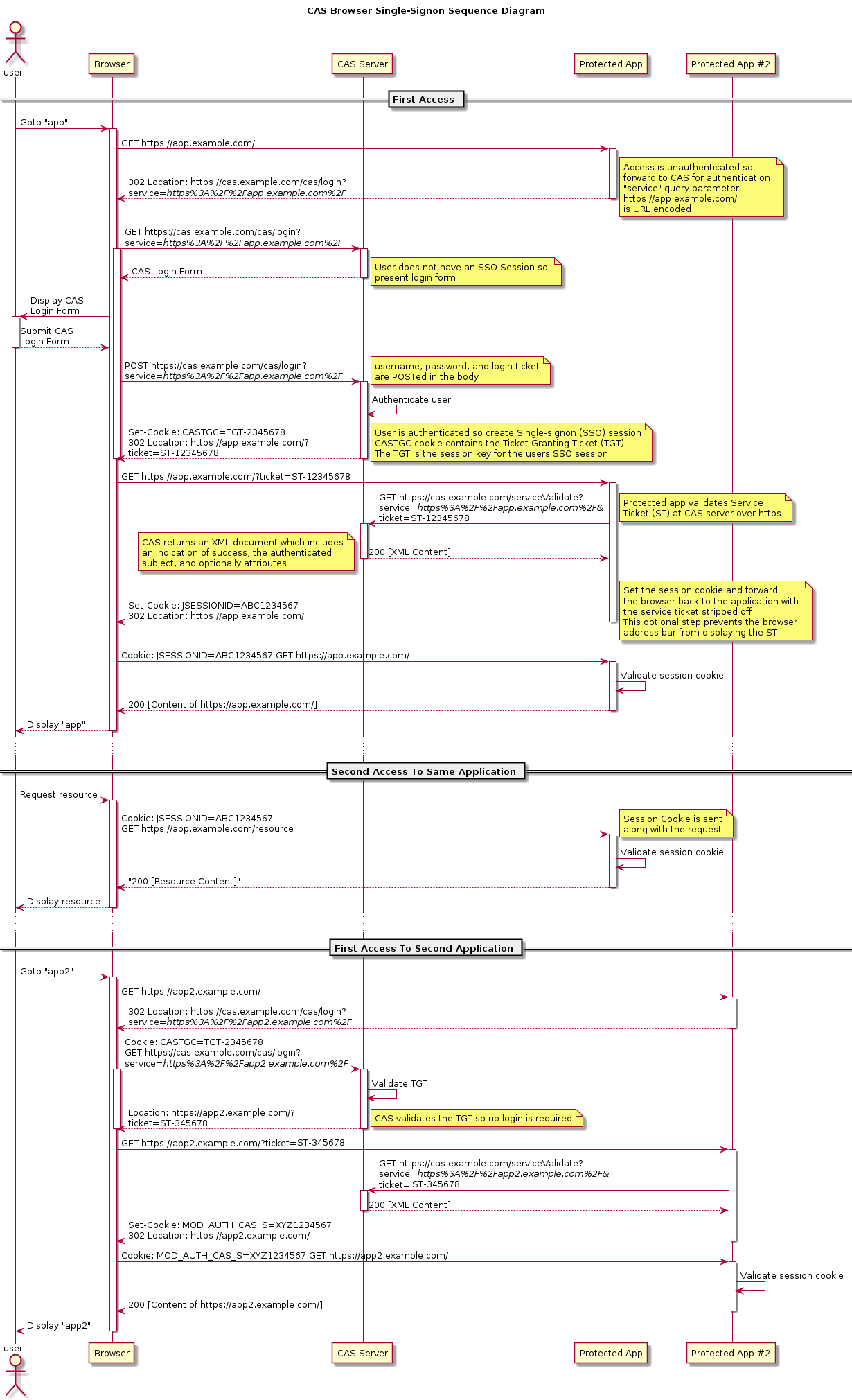
下图是官网上最权威的流程图
https://apereo.github.io/cas/4.1.x/images/cas_flow_diagram.png
二、通过Python来实现流程
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Aug 10 14:52:52 2018
@author: kinghuang
"""
import requests
import lxml.html
import sys
class AuthUtil:
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Content-Length": "162",
"Content-Type": "application/x-www-form-urlencoded",
"Cookie": "JSESSIONID=x5oK-NF_Z3QBLzDW4v8t3v2B.mgssoprdapp02",
"Host": "mgsso.cloudytrace.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36"
}
event_headers={
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Cookie": "",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36"
}
data = {
"username":"******",
"password":"******"
}
def auth(self):
###STEP1####
url_login = 'http://mgsso.cloudytrace.com/login?service=http%3A%2F%2Falert.cloudytrace.com%2Fweb%2Findex.html'
print ("begin to login ..")
sesh = requests.session()
req = sesh.get(url_login)
html_content = req.text
###STEP2####
#parsing page for hidden inputs
login_html = lxml.html.fromstring(html_content)
hidden_inputs=login_html.xpath(r'//section/input[@type="hidden"]')
user_form = {x.attrib["name"] : x.attrib["value"] for x in hidden_inputs}
user_form["username"]=self.data['username'];
user_form["password"]=self.data['password'];
#print(f"---headers--={req.headers}")
self.headers['Cookie'] = req.headers['Set-cookie']
responseRes=sesh.post(req.url, data=user_form, headers=self.headers)
#有时候cas会继续弹出登录页面做认证
if self.findStr(responseRes.request.headers['Cookie'],'CASTGC')==False:
responseRes=sesh.post(req.url, data=user_form, headers=self.headers)
###STEP3####
loginSuccess_headers = responseRes.request.headers
#!!!注意这里必须要这么写,是由于发生跳转,这么写才能获取带有CASTGC的cookie!!!
self.event_headers["Cookie"] =responseRes.request.headers["Cookie"];
print (f"---responseRes.request.headers---{responseRes.request.headers}")
'''
print (f"---sesh---{sesh.headers}")
print (f"text={responseRes.text}")
print (f"statusCode={responseRes.status_code}")
print (f"---self.headers---={self.headers}")
print (f"current_response_header:{responseRes.headers}")
print (f"---headers_result---:{headers_res}")
'''
return self.event_headers,loginSuccess_headers
def logout(self, headers):
logout_url = 'http://mgsso.cloudytrace.com/logout'
logout_req = requests.session()
logout_req.get(logout_url,headers=headers)
def findStr(self, source, target):
return source.find(target) != -1
class EventCrawler:
def crawEvent(self, headers):
###爬取的内容url##
event_url = "http://alert.cloudytrace.com/event/query.htm?endTime=2018%2F08%2F12+17:28:40&pageNo=1&pageSize=10&startTime=2018%2F08%2F05+17:28:40&systemId=";
req = requests.session()
# print (f"---crawEvent--header={headers}")
res = req.get(event_url,headers=headers);
print(f"!res_text!={res.text}")
if __name__=='__main__':
auth = AuthUtil()
headers = auth.auth()
crawler_headers = headers[0]
logout_headers = headers[1]
EventCrawler().crawEvent(headers=crawler_headers)
auth.logout(headers=logout_headers)
# crawler = EventCrawler()
# crawler.crawEvent(headers)
以上。
引用: