1 r+ 读写模式:先读后写
#-*-coding:utf-8-*- ''' 读写-先读后写 ''' f = open('log.txt',mode='r+',encoding='utf-8') print(f.read()) f.write('bowen123') f.close()
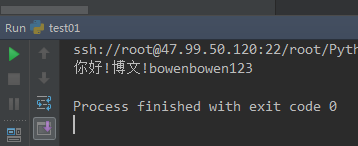
2 r+模式下先写后读
#-*-coding:utf-8-*- ''' 读写--先写再读 会把之前的从头开始覆盖,读时候读之前没有覆盖的。如果全部覆盖,是读不出东西的! ''' f = open('log.txt',mode='r+',encoding='utf-8') f.write('bbbbb') print(f.read()) f.close()

3 r+b
#-*-coding:utf-8-*- ''' 读写--r+b模式,这种写是在后面追加,不是覆盖 ''' f = open('log.txt',mode='r+b') print(f.read()) f.write('bowen'.encode('utf-8')) f.close()

4 a+
#-*-coding:utf-8-*- ''' 读写--先写再读 ''' f = open('log.txt',mode='a+',encoding='utf-8') f.write('bowen') f.seek(0) # 这句一定要加,否则读的时候光标是在末尾,是读最后是读不到的!! print(f.read()) f.close()
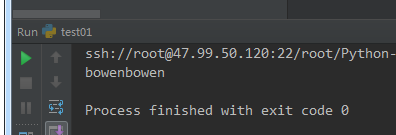
5 w+ 写读--覆盖模式 。这里省略
6 seek() 函数,注意中文时的参数
#-*-coding:utf-8-*- ''' seek(0) ''' f = open('log.txt',mode='a+',encoding='utf-8') #f.write('bowen') print(content) f.seek(3) # 这句一定要加,否则读的时候光标是在末尾,是读最后是读不到的!! print(f.read()) f.close()
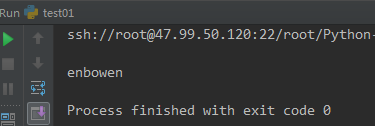
7 read() 函数 按照字符长度来比
#-*-coding:utf-8-*- ''' read(0) ''' f = open('log.txt',mode='r+',encoding='utf-8') content = f.read(3) print(content) f.close()
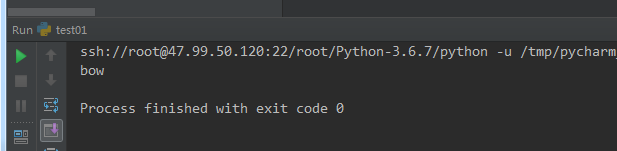
8 tell()定位光标位置
#-*-coding:utf-8-*- ''' tell()定位光标位置 ''' f = open('log.txt',mode='r+',encoding='utf-8') count = f.tell() print(count) f.seek(count+3) print(f.read()) f.close()

9 readable() 是否可读。writeable() 是否可写
10 readline()
#-*-coding:utf-8-*- ''' f.readline(),只能读一行 ''' f = open('log.txt',mode='r+',encoding='utf-8') print(f.readline()) f.close()
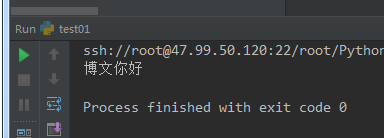
11 f.readlines()
#-*-coding:utf-8-*- ''' f.readlines() ,每一行当成列表中的元素,想读可以用for循环遍历列表 ''' f = open('log.txt',mode='r+',encoding='utf-8') print(f.readlines()) f.close()

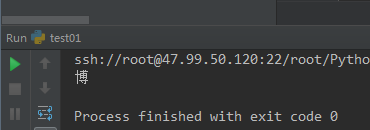
12 f.truncate(3),从后往前把源文件截取,永久改变了源文件
#-*-coding:utf-8-*- ''' f.truncate(3),从后往前把源文件截取,永久改变了源文件,源文件是博文你好 ''' f = open('log.txt',mode='r+',encoding='utf-8') #print(f.readlines()) # for li in f: # print(li) f.truncate(3) print(f.read()) f.close()
13 for循环打印列表
#-*-coding:utf-8-*- ''' for循环打印列表 ''' f = open('log.txt',mode='r+',encoding='utf-8') list=f.readlines() for li in list: print(li) f.close()

14 with open
#-*-coding:utf-8-*- ''' f是文件句柄,这种方式常用,不用写close了,可以同时打开多个操作文件,加个,open.... ''' with open('log.txt',mode='r+',encoding='utf-8') as f, open('傻逼.txt',mode='r+',encoding='utf-8') as b: print(b.read()) list=f.readlines() for li in list: print(li)
