环境准备
·jdk配置;
·scala安装与配置;
·spark安装与配置;
·hadoop安装与配置;
版本说明
·jdk:1.8
·scala:2.11.8
·spark:2.4.0
·hadoop:2.8.3
jdk配置
- 首先,进入我的电脑-〉系统属性-〉高级系统设置->环境变量
配置JAVA_Home
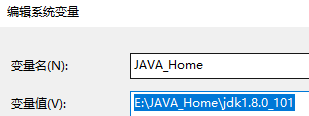
配置Path

- 验证配置

scala安装与配置
- scala下载
官方地址:https://www.scala-lang.org/download/2.11.8.html

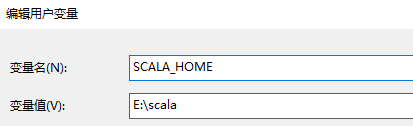
- 配置用户变量下的Path
变量值一栏输入:E:\scala 也就是scala的安装目录
注意:安装路径不能有空格和中文,否则报错,出现报错需要卸载重装
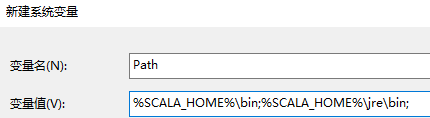
- 配置系统变量下的Path变量
在"变量值"一栏的最前面添加如下的路径: %SCALA_HOME%\bin;%SCALA_HOME%\jre\bin;
注意:后面的分号 ; 不要漏掉。
- 设置系统变量下的Classpath 变量:
· “变量名”:ClassPath
· “变量值”:
· .;%SCALA_HOME%\bin;%SCALA_HOME%\lib\dt.jar;%SCALA_HOME%\lib\tools.jar.;

- 验证配置

spark安装与配置
- spark下载:http://spark.apache.org/downloads.html
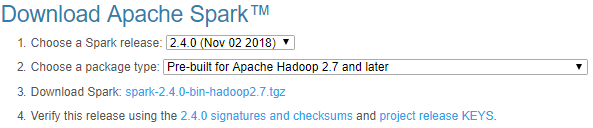
选择3,进入下载页面 ,选择默认下载

- 下载完毕后解压到D:
- 配置Path
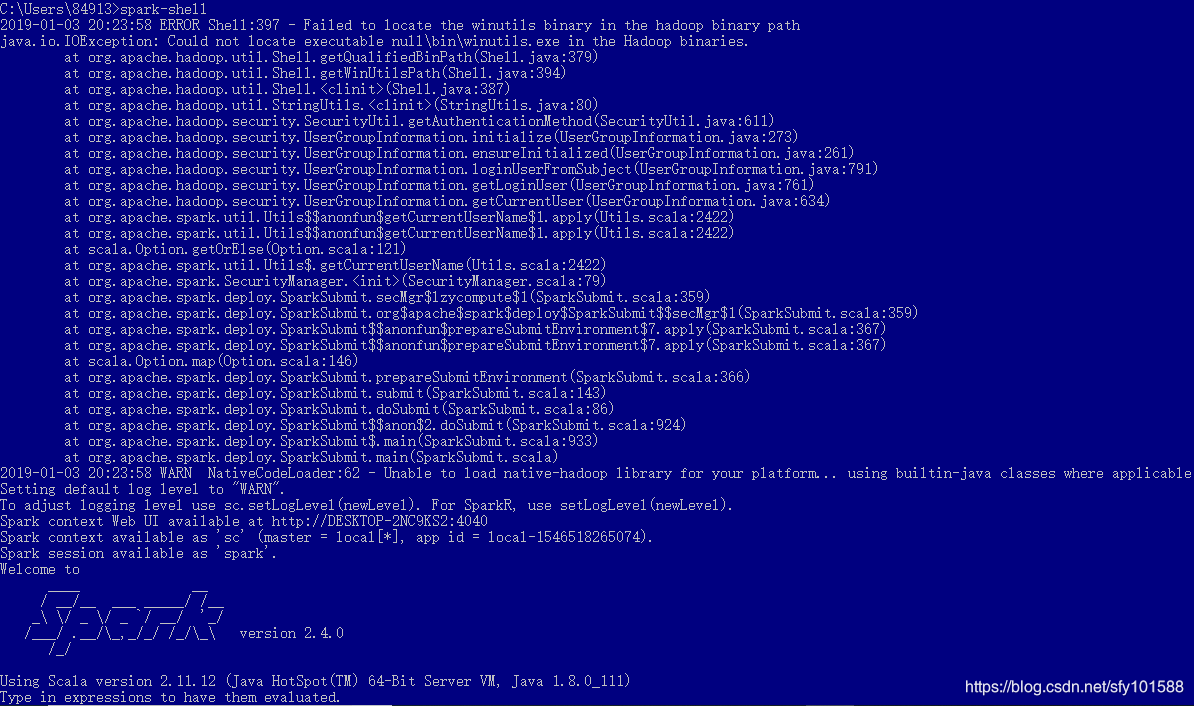
如上,可以看到对应的spark、scala、java版本,同时存在异常信息,异常信息是由于hadoop导致的,下面来配置hadoop即可解决该异常。
Hadoop安装与配置
- Hadoop官网下载:http://hadoop.apache.org/releases.html
- 解压Hadoop
- 配置Path
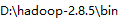
- 验证配置
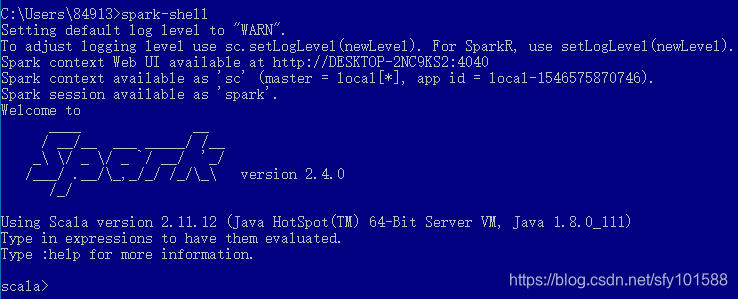
基于spark用线性回归进行数据预测
分类和聚类算法很多,但是对数据进行精准预测的算法不是很多,这里参照了别人的线性回归的例子,使用spark ml进行线性回归。
数据格式
标签,特征值1 特征值2 特征值3...
1. 1,1.9
2. 2,3.1
3. 3,4
4. 3.5,4.45
5. 4,5.02
6. 9,9.97
7. -2,-0.98
实现代码如下
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
val data_path = "files/C:/Users/84913/Desktop/sfy/linear_regression_data1.txt"
val data = sc.textFile(data_path)
val training = data.map { line =>
val arr = line.split(',')
LabeledPoint(arr(0).toDouble, Vectors.dense(arr(1).split(' ').map(_.toDouble)))
}.cache()
training.foreach(println)
结果
(1.0,[1.9])
(2.0,[3.1])
(3.0,[4.0])
(3.5,[4.45])
(4.0,[5.02])
(9.0,[9.97])
(-2.0,[-0.98])