查询数据
基本语法:select 字段列表/* from 表名 [where 条件];
完整语法:select [select选项] 字段列表[字段别名]/* from 数据源[where 条件子句] [group by条件子句] [having 子句] [order by 子句] [limit 子句];
select选项部分:select选项是指select对查出来的结果的处理方式,主要有两种。
All:默认的,保留所有的结果
Distinct: 对查询结果进行去重(将重复的给去除)
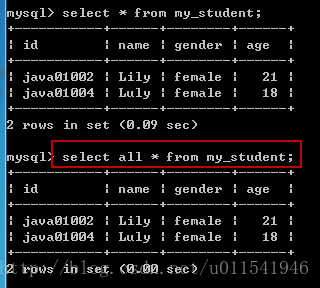
查询全部
举例:
Select all * from 表名; 和select * from 表名是等价的。
我们前面经常使用select * from 表名的语法来查询全部数据,这里举例下带上select all选项;
去重查询
为了演示去重,我们得给当前my_student表进行插入一些重复的数据。
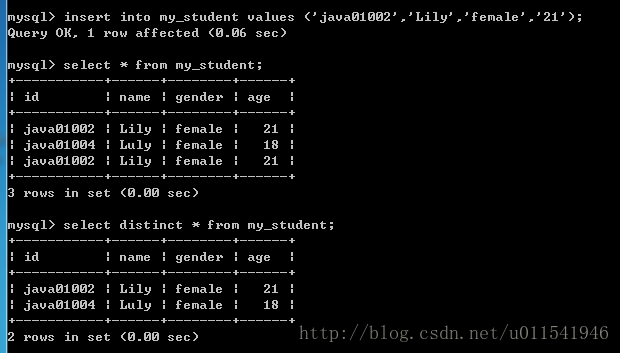
上面我们先是插入了一条重复的数据,然后用select distinct查询就显示两条结果,去除了一个重复的结果。注意这里distinct去除是指全部字段都完全相同才认为是一个重复的记录。
字段别名
字段别名:当数据进行查询出来的时候,有时候名字并不一定就满足需求(多表查询的时候会有同名字段),这个时候需要对字段名进行重命名,这个就是别名。
语法:字段名 [as] 别名;
举例:
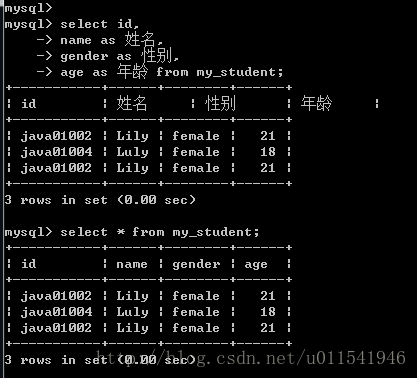
第一种是使用别名显示,第二种不加,还有添加别名语句as可以写也可以不写。
数据源就是数据的来源,关系型数据库的来源都是数据表。本质上只要保证数据类似二维表,最终都可以作为数据源。数据源分为多种:单表数据源,多表数据源,查询语句。
单表数据源举例:select * from 表名;
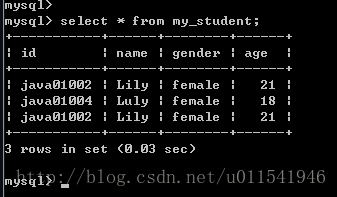
多表数据源举例:select * from 表名1,表名2,…;
这里我们用两个表查询举例,先分别看看两个表的内容。
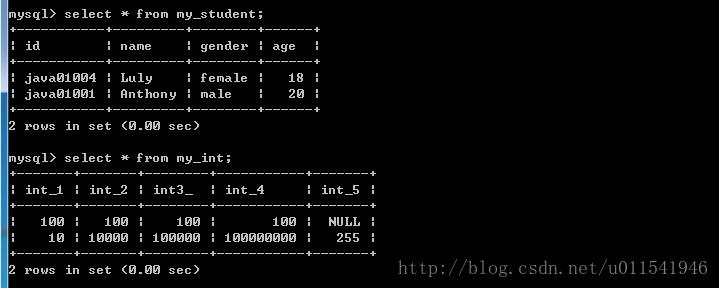
上面显示两个表,表1有1条数据,表2有两条数据。
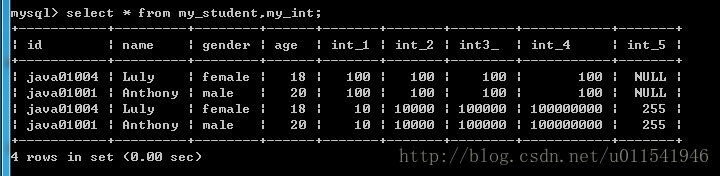
上面的现象是:从一张表中取出一条记录,去另外一张表中匹配所有记录,而且全部保留(记录数和字段数),这种结果在数学上称之为笛卡尔积。其实就是一种交叉连接,笛卡尔积没什么用处,实际工作中尽量避免。
查询语句举例:数据的来源是一条查询语句(查询语句结果其实就是二维表)
语法:select * from (select语句) as 表名;
Where字句:用来判断数据,也就是根据条件筛选数据。Where 子句返回结果有两种:0和1,0代表false,1代表true,在SQL中没有布尔这种数据类型。
判断条件:
比较运算符:>, <, >=, !=, <>, =, like, between and, in, not in。
逻辑运算符:&&(and),||(or), !(not)
简单解释上面几种判断条件:<>这个也是不等于,意思是既大于也小于,like一般是在模糊匹配的时候用到,between and很好理解,在什么范围之间,in 和not in就是包含或者不包含的判断。
Where 原理:
Where是唯一一个直接从磁盘获取数据的时候就开始判断的条件,从磁盘取出一条记录,开始进行where判断,判断的结果如果成立保存到内存,如果失败直接放弃。从这个角度来说,where字句是考虑到内存使用效率的设计。
在举例之前,我们先来修改下我们的学生表,增加几个字段。
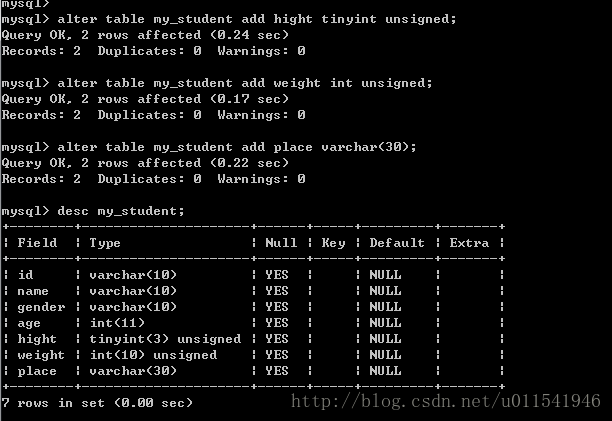
分别增加了身高,体重和籍贯三个字段。下面我们来给插入几条数据,插入后效果如下。(如果你嫌麻烦,你可以用图像化工具连接mysql,进行编辑,插入数据)
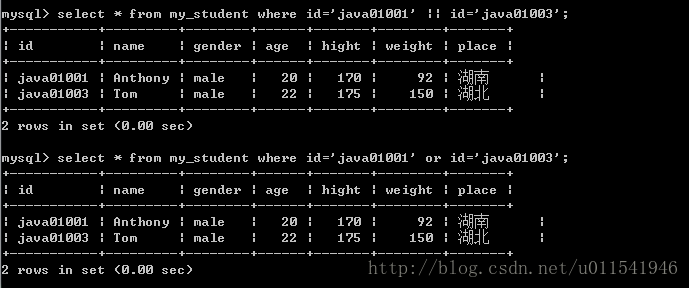
查询练习1:找出学生id为java01001或者java01003的学生,练习逻辑判断
查询练习2:查询身高在165到175之间的学生

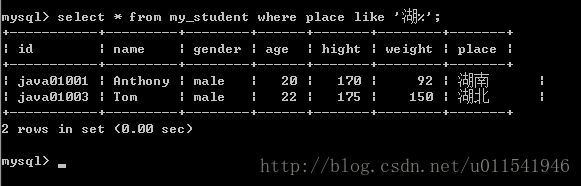
查询练习3:找出来自湖南或者湖北的学生。
这个利用练习1的逻辑判断是完全可以实现,下面我们用like模糊匹配来实现。