KMP用于求b串在a串的出现位置(字符串匹配)。我们通过一道题来讲讲KMP的算法过程。
【HDU 1711】给定两个数字串a、b。求b在a第一次出现的位置。若没出现输出-1。
一般的暴力算法就是暴力匹配。若有一个位置匹配失败,则回溯后重新匹配。时间复杂度高达
。
可以发现,这个过程中有大量的冗余运算。比方说,匹配失败后(蓝色点),图中的红色段都是已经匹配好的了。
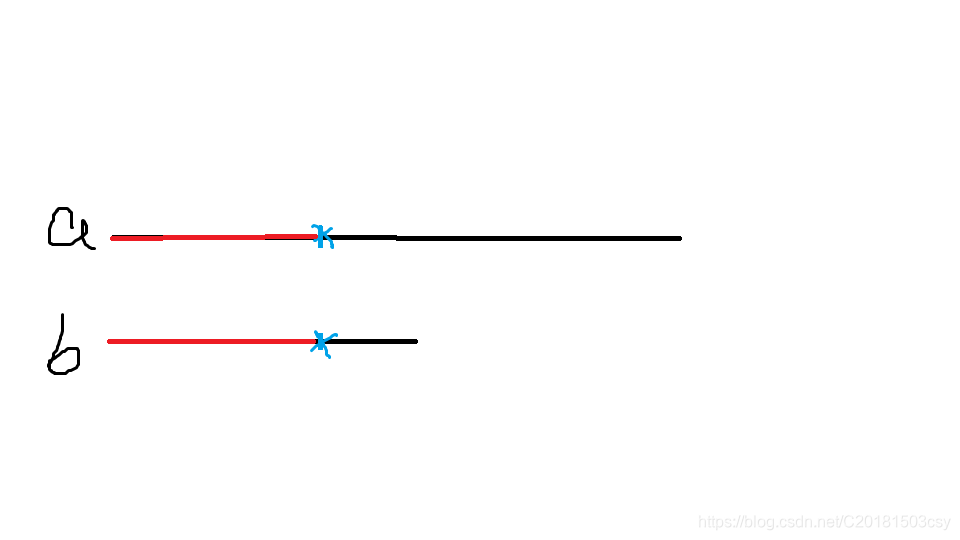
那么我们想要做的,就是将b向右移动若干个单位,使得a中的蓝点能够匹配上就行了。
我们把移动后的串记作b’(如图)
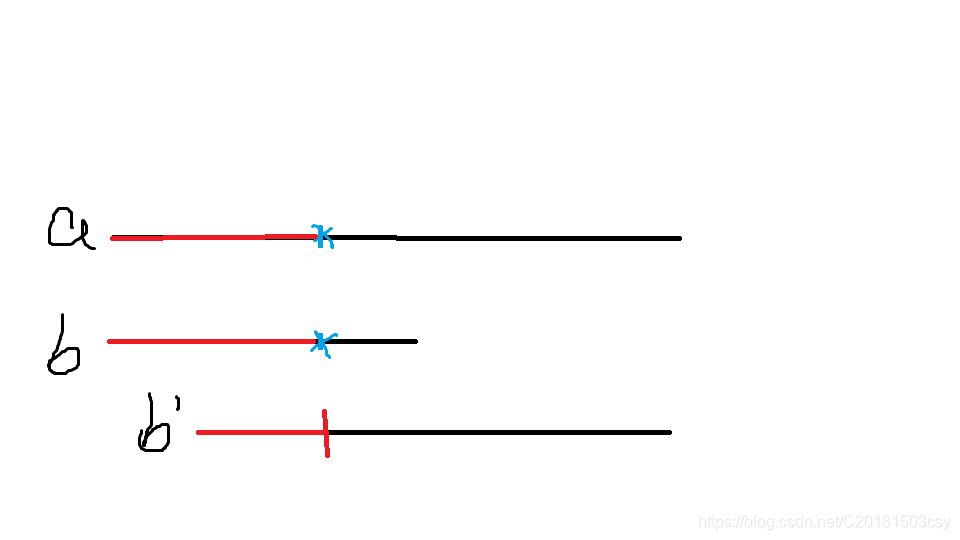
显然,b’的红色段(即b红色段的开头一小段)等于a红色段的末尾一小段(即b红色段的末尾一小段),也就是说。b’的红色段是b的一个前缀后缀公共子串。为了避免遗漏,b’的红色段就应该是b前i-1个元素的最长前缀后缀公共子串。
举一个例子。若现在有一个串:
abababa
其前缀有:
a
ab
aba
abab
ababa
ababab
后缀有:
a
ba
aba
baba
ababa
ababab
前缀后缀公共子串有:
a
aba
ababa
(原串本身不能作为前缀后缀公共子串)
于是,我们用nxt[i]表示若在b的i处匹配失败,应该再从哪里开始匹配。这个数组可以用递推搞定。特殊地,nxt[0]=-1
首先,由上面的分析可知,nxt[i]就相当于b前i-1个元素的最长前缀后缀公共子串的长度。
考虑已求出前i-1个nxt[i]。那么就判断第i-1个字符是否能加入到i-2的最长前缀后缀公共子串中。如果能,就有nxt[i]=nxt[i-1]+1。否则,令j=nxt[i-1],重复上述过程。
讲得不是很清楚,但看看代码应该就能明白:
nxt[0] = -1;
for(i = 1; i < m; i++)
{
j = nxt[i - 1];
while(j != -1 && b[i - 1] != b[j])
j = nxt[j];
nxt[i] = j + 1;
}
然后用nxt[i]计算匹配位置:
for(i = j = 0; i <= n; i++, j++)
{
if(j == m)
{
printf("%d\n", i - j + 1);
break;
}
if(i == n)
{
puts("-1");
break;
}
while(j != -1 && a[i] != b[j])
j = nxt[j];
}
题目的完整代码:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int mn = 1000005, mm = 10005;
int a[mn], b[mm], nxt[mm];
int main()
{
int t, n, m, i, j;
scanf("%d", &t);
while(t--)
{
scanf("%d%d", &n, &m);
for(i = 0; i < n; i++)
scanf("%d", &a[i]);
for(i = 0; i < m; i++)
scanf("%d", &b[i]);
if(n < m)
{
puts("-1");
continue;
}
nxt[0] = -1;
for(i = 1; i < m; i++)
{
j = nxt[i - 1];
while(j != -1 && b[i - 1] != b[j])
j = nxt[j];
nxt[i] = j + 1;
}
for(i = j = 0; i <= n; i++, j++)
{
if(j == m)
{
printf("%d\n", i - j + 1);
break;
}
if(i == n)
{
puts("-1");
break;
}
while(j != -1 && a[i] != b[j])
j = nxt[j];
}
}
}
附:时间复杂度分析:
计算匹配位置部分显然为
预处理nxt[i]时,根据其构造方法可知,每一个位置最多会被当做“跳板”1次。这样,内层处理的平摊复杂度为
。于是预处理部分为
,总时间复杂度为