目录
什么是知识?知识有什么用
知识的传统定义来源于信息科学,知识的概念通常表示为金字塔的一部分,该金字塔有时也成为知识层次,其中数据是基础,信息是中间层,而知识在最顶层。
攀登金字塔意味着从数据中提炼知识,这需要经历内容和意义的整合,当攀登这个金字塔时,所用技术可以帮助我们更加深入的理解原始数据,更重要的是帮助我们理解生成这些数据的用户,换言之,它会变得更加有用。

大数据3V
大数据的3V即是容量 volume 多样性 variety 速度 velocity ,容量指的是处理分布在不同机器中的数据,这意味着需要一个与处理小量数据完全不同的基础架构,此外,容量与速度是相关的,当数据快速增长时,大这个概念也在不断变化,最后多样性是指如何以不同的格式和结果呈现数据,这些多样的数据通常不兼容且带有不同语义。社会媒体数据也具有3V特性。
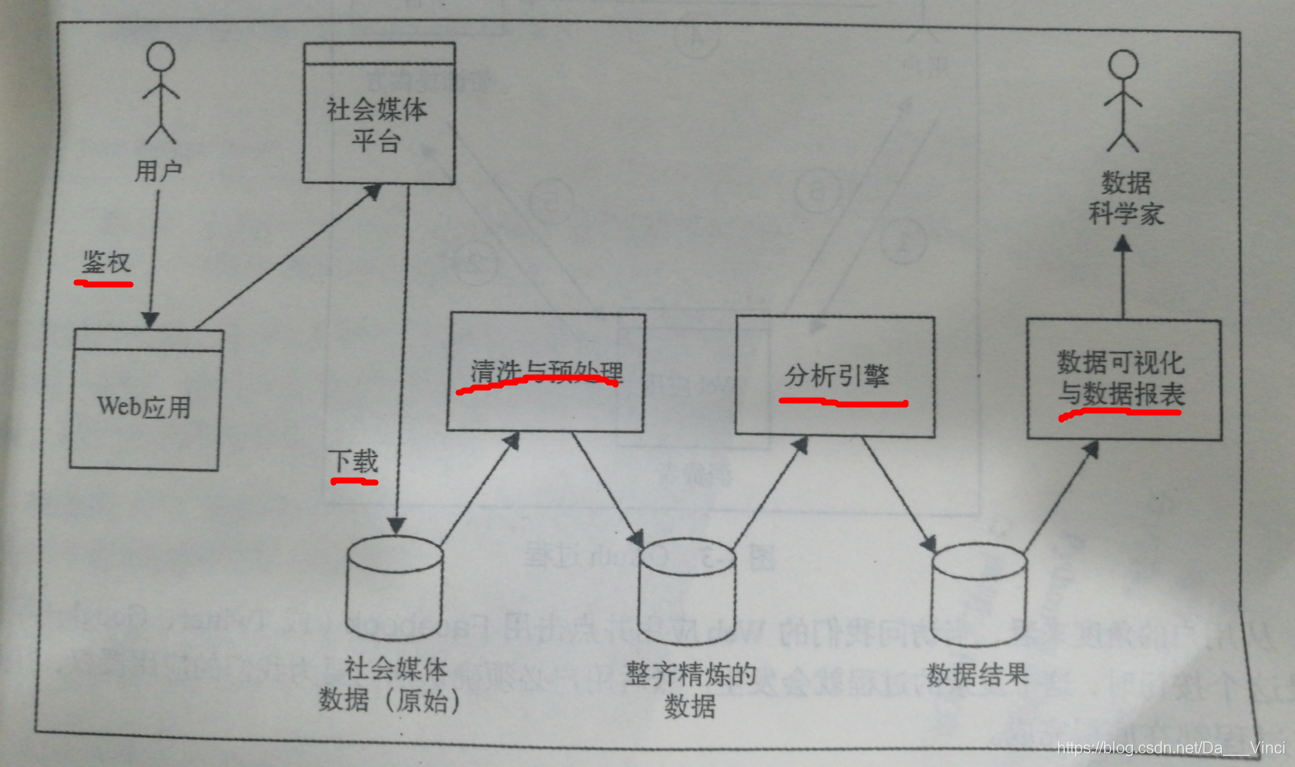
数据挖掘流程
(1)鉴权
(2)数据收集
(3)数据清洗和预处理
(4)建模和分析
(5)结果呈现
文本挖掘
文本挖掘是从非结构化的文本数据中获得结构化信息的过程,文本挖掘适用于大多数社交媒体平台,因为用户可以用帖子和评论的方式发布内容。
文档分类:将一个文档指定为一个或多个类别
文档聚类:将文档分组为子集,也称作簇,每个类中的数据是一致的,且与其他类的数据有区别。
文档摘要:生成一个简短版的文档,目的是为用户减少信息量,同事保留原始版本中最重要的内容。
实体抽取:在文本中定位,并对实体分类,类别如人物地点,机构等。
情感分析:识别并对文本中的情感和意见分类,以理解对特定产品,话题,服务等的态度。
机器学习简介
机器学习是构建算法从数据中学习并进行预测的科学,他和数据挖掘紧密相关,有时这两个领域可以互换,这两个领域的主要区别在于:机器学习侧重于基于数据的已知属性进行预测,而数据挖掘则侧重于基于数据的未知属性发现新信息。
机器学习最流行的方法分为监督学习和无监督学习两类。
监督学习可以用来解决分类这样的问题,在分类问题中,数据带有额外属性,而我们想要预测类的标签,在这种情况下,分类器会将每个输入对象与期望输出关联起来,然后分类器基于输入对象的特征进行推断,为新的未见输入预测期望的标签,监督学习常用的方法有朴素贝叶斯、支持向量机、和神经网络系列模型。
无监督学习已知数据并不带有标签问题,这类问题的典型实例就是聚类,在聚类问题中,算法会试图寻找数据节点中的隐藏结构,以便将相似的项分为一类,另一个应用是识别不属于特定组的项,最常用的方法是K均值算法。