文章目录
1.1交互式解释器
>>> print("Hello, world!")
Hello, world!
>>>
1.2算法是什么
计算机编程就是告诉计算机如何做
1.3数和表达式
加减乘除±*/
>>> 53672 + 235253
288925
取整//--------向下(小)圆整
>>> 5.0 // 2.4
2.0
取模(取余)%
>>> 10 % 3
1
乘方(求幂)
>>> (-3) ** 2
9
十六进制、八进制和二进制
>>> 0xAF
175
1.4变量
赋值
>>> x = 3
使用
>>> x * 2
6
Notice:使用Python变量前必须给它赋值,因为Python变量没有默认值。在Python中,名称(标识符)只能由字母、数字和下划线(_)构成,且不能以数字打头。
因此Plan9是合法的变量名,而9Plan不是。
1.5语句
赋值语句
Print语句(调用print函数的语句)
表达式:是一些东西
语句:做一些事情,根本特征是执行修改操作
1.6获取用户输入input()
Input函数
>>> input("The meaning of life: ")
The meaning of life: 42
'42'
输入内容以文本或字符串方式返回
>>> x = input("x: ")
x: 34
>>> y = input("y: ")
y: 42
>>> print(int(x) * int(y))
1428
>>> print(x+y)
3442
If语句
>>> if 1 == 2: print('One equals two')
...
>>> if 1 == 1:
print('One equals one')
...
One equals one
>>>
NOTICE:相等运算符(==)
1.7函数
调用函数:你向它提供实参,而它返回一个值。
鉴于函数调用返回一个值,因此它们也是表达式
pow()幂函数
>>> 2 ** 3
8
>>> pow(2, 3)
8
pow等标准函数称为内置函数,可结合使用函数调用和运算符来编写更复杂的表达
abs()计算绝对值
>>> abs(-10)
10
Round()将浮点数圆整为与之最接近的整数。
>>> 2 // 3
0
>>> round(2 / 3)
1.0
//整除符号是向下(小)圆整,
round()是向近圆整,有一个floor()可以向下(小)圆整,但不能直接使用,ceil()向上圆整
(也可floor()+1就是向上圆整)
1.8 模块
可将模块视为扩展,通过将其导入可以扩展Python功能
工作原理:我们使用import module导入模块,再以module.function的方式使用模块
中的函数
floor()向下圆整
>>> import math
>>> math.floor(32.9)
32
int()取整(类似的str()、float()实际上是类)
>>> int(32.9)
32
ceil()向上圆整
>>> math.ceil(32.3)
33
确定不会从不同模块导入多个同名函数,避免每次调用函数时都指定模块名,可以如下
变种from module import function
Sqrt()开平方
>>> from math import *
>>> sqrt(9)
3.0
Notice:如果使用这种命令,其他模块的同名函数则无法被调用。
事实上,可使用变量来引用函数(以及其他大部分Python元素)
>>> import math
>>> foo =math.sqrt
>>> foo(4)
2.0
1.8.1 cmath 和复数
如果有数平方是负数的话,那个数就是虚数。实部和虚部组成的数为复数。
Python标准库提供了一个专门用于处理复数的模块cmath。
>>> import cmath
>>> cmath.sqrt(-1)
1j
1j是个虚数,虚数都以j(或J)结尾。复数算术运算都基于如下定义:-1的平方根为1j
>>> (1 + 3j) * (9 + 4j)
(-3 + 31j)
1.8.2 回到未来
神奇模块__future__
1.9保存并执行程序
1.9.1从命令提示符运行 Python 脚本
Windows系统下:
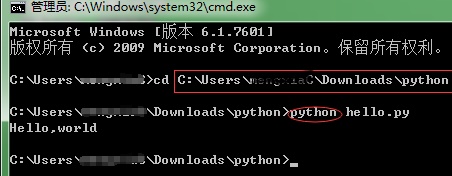
前提:
正确配置环境变量
存放hello.py文件的目录也要配置到环境变量,文件内容:print(“Hello, world!”)
不要忘记在文件名前输入“Python”
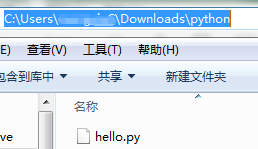
同理,改变hello.py内容
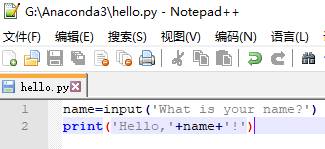

这里Jack是手动输入的
海归绘图法-比print更有趣的输出
>>> from turtle import *
>>> forward(100)
>>> left(120)
>>> forward(100)
>>> left(120)
>>> forward(100)
要将铅笔抬起,可使用penup();要将铅笔重新放下,可使用pendown()。
1.9.2 让脚本像普通程序一样
UNIX
#!/usr/bin/env python
$ chmod a+x hello.py
$ hello.py (尝试用./hello.py)
Windows
双击.py文件选择打开程序

修改文件,避免操作完就退出
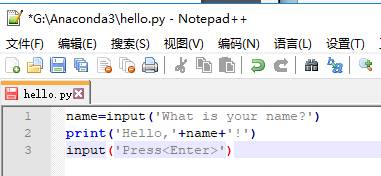
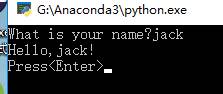
按完Enter键后退出
1.9.3 注释#
>>> #这是注释
... print('hello')
Hello
1.10 字符串
1.10.1 单引号字符串以及对引号转义’’ “” \
单引号和双引号在打印字符串的时候相同
>>> 'hello,world'
'hello,world'
>>> "hello,woeld"
'hello,woeld'
但当打印的字符串中有引用,需要同时用到这两种引号
>>> 'she said:"hello,world"'
'she said:"hello,world"'
>>> "Let's go!"
"Let's go!"
或者用反斜杠\转义
>>> 'Let\'s go!'
"Let's go!"
1.10.2 拼接字符串+
同时一次输入两个字符产,则自动关联
>>> "Let's say:"'"Hello,World"'
'Let\'s say:"Hello,World"'
拼接方法:+
>>> x='Hello,'
>>> y='World!'
>>> x+y
'Hello,World!'
1.10.3 字符串表示 str 和 repr
将值转换成了字符串。print输出比直接输出,消除引号,并可以识别字符串中的 转义符
'Hello,Woeld!'
>>> "Hello,World!"
'Hello,World!'
>>> print("Hello,World!")
Hello,World!
>>> "Hello,\nWorld!"
'Hello,\nWorld!'
>>> print("Hello,\nWorld!")
Hello,
World!
使用str(注意:这是个类)能以合理的方式将值转换为用户能够看懂的字符串。 例如,尽可能将特殊字符编码转换为相应的字符。
使用repr(object)(注意:这是个函数)时,通常会获得值的合法Python表达式 表示。返回一个对象的 string 格式。
>>> s='hello,\nworld'
>>> str(s)
'hello,\nworld'
>>> print(str(s))
hello,
world
>>> repr(s)
"'hello,\\nworld'"
>>> print(repr(s))
'hello,\nworld'
>>>
1.10.4 长字符串、原始字符串和字节
1. 长字符串
要表示很长的字符串(跨越多行的字符串),可使用三引号(而不是普通引号)。
>>> print('''This is a very long string,It continues here.
... and it's not over yet."Hello,World"
... Still here.''')
This is a very long string,It continues here.
and it's not over yet."Hello,World"
Still here.
>>>
常规字符串换行只要在换行出加\
>>> 1+2+\
... 4+5
12
2. 原始字符串
针对反斜杠的转义,可以在\前再增加一个\,对之前的\进行转义,从而打印 出完整的字符串
>>> path='C:\nwhere'
>>> path
'C:\nwhere'
>>> print(path)
C:
where
>>> print('C:\\nwhere')
C:\nwhere
或者在字符串前加r,原始字符串用前缀r表示
>>> print(r'C:\where')
C:\where
原始字符串不能以反斜杠结尾。
>>> print(r'This is illegal\')
File "<stdin>", line 1
print(r'This is illegal\')
^
SyntaxError: EOL while scanning string literal
如果非要以\结尾,可以尝试以下方法
>>> print(r'C:\Progrm\foo\bar'+'\\')
C:\Progrm\foo\bar\
>>> print(r'C:\Progrm\foo\bar\\'[:-1])
C:\Progrm\foo\bar\
>>> print('C:\\Progrm\\foo\\bar\\')
C:\Progrm\foo\bar\
3.Unicode、bytes和bytearray
每个Unicode字符都用一个码点(code point)表示,而码点是Unicode标准给每个字符指定的数字。
http://unicode-table.com
>>> '\u00C6'
'Æ'
不可变的bytes,可直接创建bytes对象(而不是字符串)方法是使用前缀b:
>>> b'Hello'
b'Hello'
>>>
只要文件使用的是UTF-8编码,就无需操心编码和解码的问题。但如果原本 正常的文本变成了乱码,就说明文件使用的可能是其他编码。
了bytearray,它是bytes的可变版
要替换其中的字符,必须将其指定为0~255的值。
因此,要插入字符,必须使用ord获取其序数值(ordinal value)
>>> x=bytearray(b'Hello!')
>>> x[1]=ord(b'u')
>>> x
bytearray(b'Hullo!')
>>>
1.11 小结
1.11.1 本章介绍的新函数
abs(number) 返回指定数的绝对值
bytes(string, encoding[, errors]) 对指定的字符串进行编码,并以指定的方式处理错误
cmath.sqrt(number) 返回平方根;可用于负数
float(object) 将字符串或数字转换为浮点数
help([object]) 提供交互式帮助
input(prompt) 以字符串的方式获取用户输入
int(object) 将字符串或数转换为整数
math.ceil(number) 以浮点数的方式返回向上圆整的结果
math.floor(number) 以浮点数的方式返回向下圆整的结果
math.sqrt(number) 返回平方根;不能用于负数
pow(x, y[, z]) 返回x的y次方对z求模的结果
print(object, …) 将提供的实参打印出来,并用空格分隔
repr(object) 返回指定值的字符串表示
round(number[, ndigits]) 四舍五入为指定的精度,正好为5时舍入到偶数
str(object) 将指定的值转换为字符串。用于转换bytes时,可指定编码和错误处理方式