pandas是python数据分析中非常常用的一个模块,pandas中功能较多学起来有一定难度,本片文章通过一些简单例子带大家快速上手pandas。
我们要用的森林植被的数据,文件名为parks.csv。
首先先载入pandas:
import pandas as pd
然后用pandas读入数据,把公园编号’Park Code’设置为index
df = pd.read_csv('parks.csv', index_col=['Park Code'])
# 显示出前5行
df.head(5)
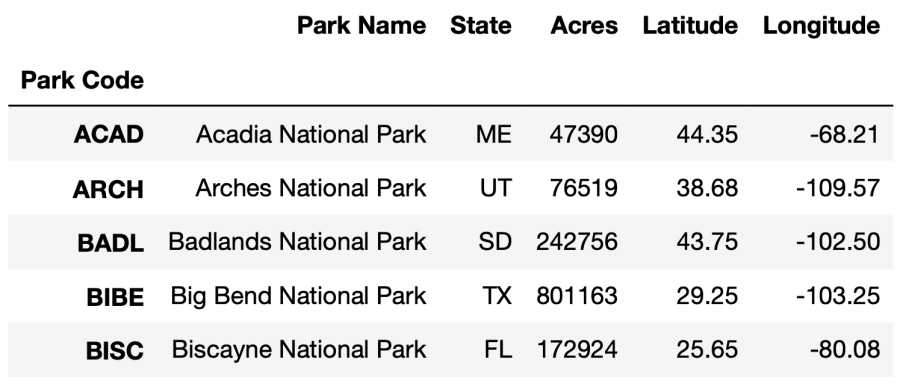
数据的列分别为:公园名字,公园在哪个州,公园大小,维度,经度
获取单行数据:
使用.iloc 加上行索引获取单行数据
df.iloc[2]
Park Name Badlands National Park
State SD
Acres 242756
Latitude 43.75
Longitude -102.5
Name: BADL, dtype: object
使用 .loc 方法加上index的名称获取单行数据
df.loc['BADL']
Park Name Badlands National Park
State SD
Acres 242756
Latitude 43.75
Longitude -102.5
Name: BADL, dtype: object
获取多行数据:
loc加上多行数据的名称
df.loc[['BADL', 'ARCH', 'ACAD']]

iloc加上行索引
df.iloc[[2, 1, 0]]
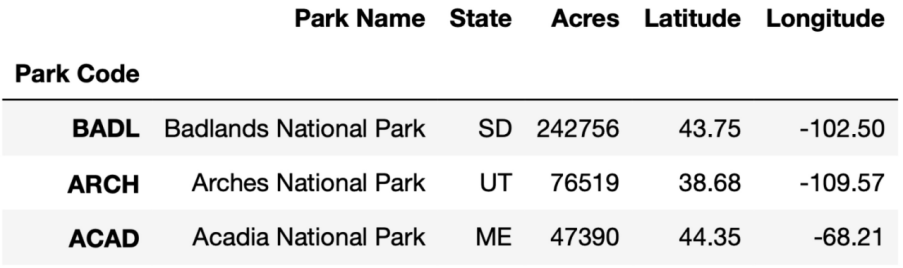
获取数据分片
# 获取前3行数据
df[:3]
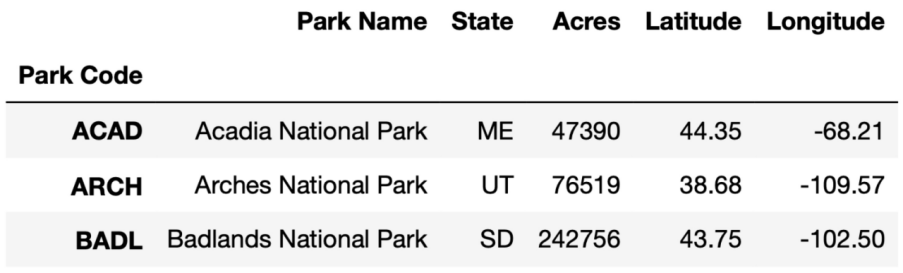
# 获取后3行数据
df[-3:]

获取单列数据
获得State这一列数据的前3行
df['State'].head(3)
Park Code
ACAD ME
ARCH UT
BADL SD
Name: State, dtype: object
使用下面df.State方法可以获得同样效果
df.State.head(3)
Park Code
ACAD ME
ARCH UT
BADL SD
Name: State, dtype: object
df.Park Code 将会出错,因为Park Code中间有空格
df.Park Code
File “”, line 1
df.Park Code
^
SyntaxError: invalid syntax
我们可以把所有列的名称中的空格都替换成_避免出错
df.columns = [col.replace(' ', '_').lower() for col in df.columns]
print(df.columns)p=msno.bar(diabetes_data)
Index([‘park_name’, ‘state’, ‘acres’, ‘latitude’, ‘longitude’], dtype=‘object’)
获取多列数据
columns = ['state', 'acres']
df[columns][:3]
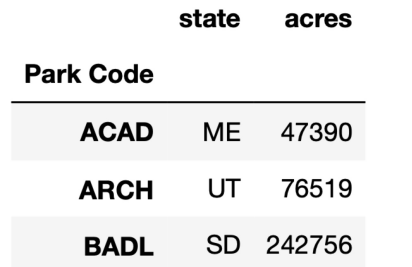
选择数据的子集
选择state=='UT’的数据,False表示条件该行条件不成立,True表示该行条件成立
(df.state == 'UT').head()
Park Code
ACAD False
ARCH True
BADL False
BIBE False
BISC False
Name: state, dtype: bool
选择所有state=='UT’结果为True的行
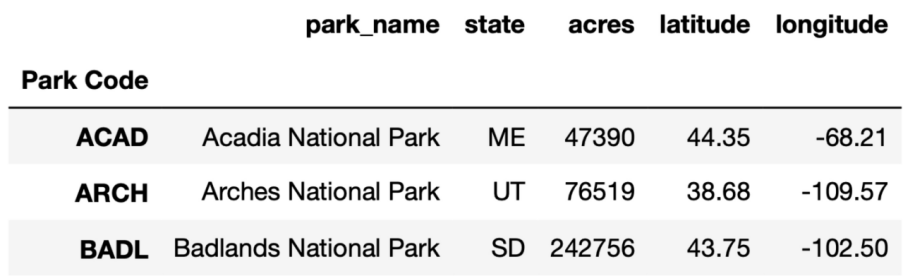
df[df.state == 'UT']
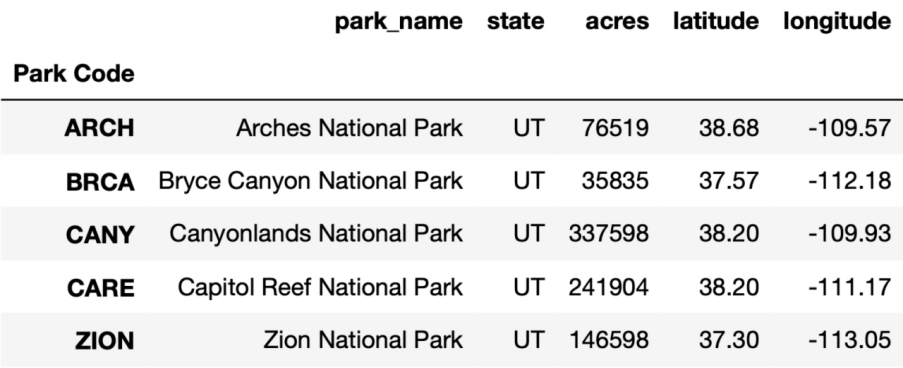
更复杂一些的数据提取,获取纬度大于60或者面积大于10^6的数据的前三行
df[(df.latitude > 60) | (df.acres > 10**6)].head(3)
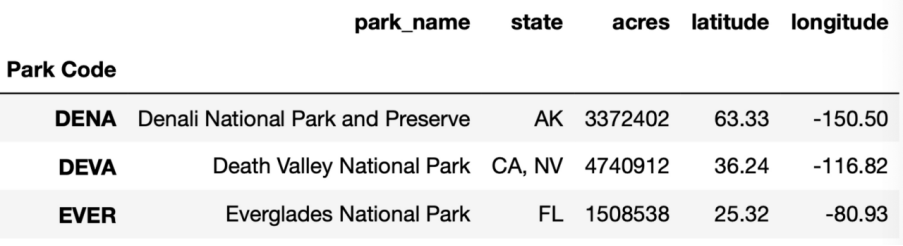
对park_name中的字符以空格做切分,切分后放入lambda x: len(x) == 3函数中做判断,如果判断正确返回True,判断错误返回False
df[df['park_name'].str.split().apply(lambda x: len(x) == 3)].head(3)
state中的数字为[‘WA’, ‘OR’, ‘CA’]中的一个则为True,否则为False
df[df.state.isin(['WA', 'OR', 'CA'])].head()
